在 LLM 代理(LLM Agent)风靡软件工程领域的当下,研究者们普遍认为:只有通过多轮交互、工具调用、自主规划的智能体(Agent)。然而,来自伊利诺伊大学厄巴纳-香槟分校(UIUC)的研究团队在最新论文《AGENTLESS: Demystifying LLM-based Software Engineering Agents》中提出了一个颠覆性观点:
复杂的 LLM 代理并非必要。
一个无代理(agentless)的两阶段流程(定位 + 修复),在 SWE-bench Lite 上达到了 27.33% 的修复成功率,超越所有开源 LLM 代理,且成本仅为 $0.34/bug,远低于 SWE-agent($2.51)等系统。
更令人惊讶的是,作者对 SWE-bench Lite 进行了人工细粒度分类,发现其中 21.3% 的问题存在严重缺陷(如描述信息不足、修复方案直接泄露在 Issue 中等)。剔除这些问题后,他们构建了更严格的 SWE-bench Lite-S。在该基准上,Agentless 依然保持 SOTA 开源性能(28.17%),进一步验证了其鲁棒性。
动机:为何我们需要重新审视 LLM 代理?
论文指出,当前 LLM 代理存在三大根本性缺陷:
- 工具使用复杂且脆弱
代理需通过 API 调用工具(如文件读写、测试执行),但 API 设计需精确的输入/输出格式。一旦 LLM 生成格式错误的调用(如参数类型错误),整个流程可能崩溃,且错误会通过多轮交互放大。 - 决策过程缺乏控制
代理自主决定下一步行动,但其决策基于历史反馈,易陷入局部循环(如反复读取同一文件)。一次错误的探索可能导致后续所有操作偏离正确路径。 - 缺乏自省与纠错能力
代理在复现 Issue 时可能生成错误的测试用例,而其无法判断测试是否可靠,导致基于错误测试的修复必然失败。
核心质疑:我们真的需要让 LLM 像人类一样“自由探索”吗?还是说,专家设计的、确定性的流程(procedural approach)
Agentless 方法论:极简两阶段框架
Agentless 完全摒弃了 LLM 的自主决策,采用纯专家驱动的两阶段流程:
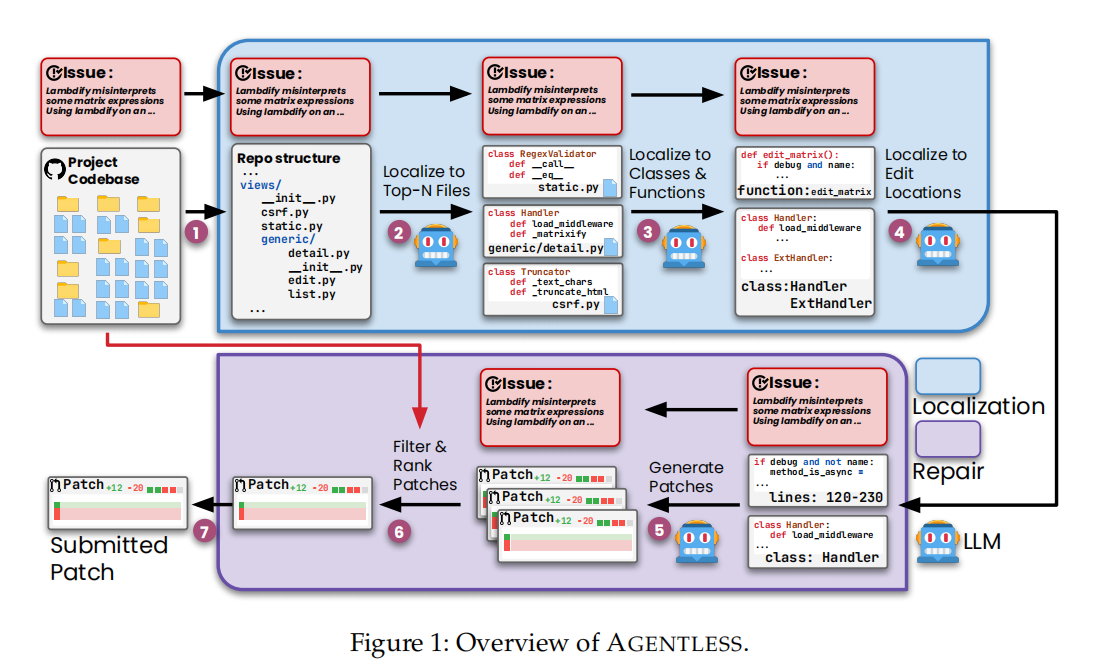
阶段 1:分层定位(Hierarchical Localization)
- Step 1: 定位到 Top-N 文件
将整个仓库转换为目录树结构(repository structure format),提供给 LLM。LLM 根据 Issue 描述返回最可疑的文件列表(默认 Top-3)。 - Step 2: 定位到相关类/函数
为每个可疑文件生成骨架格式(skeleton format,见 Figure 2):仅包含类、函数的声明头(不含实现),保留模块级注释。LLM 返回需要检查的具体类/函数。

- Step 3: 定位到编辑位置
提供 Step 2 中函数的完整代码,LLM 返回精确的编辑位置(行号或函数名)。
关键设计:通过分层缩减上下文,避免将整个仓库塞给 LLM,既降低成本,又提升定位精度。
阶段 2:修复与排序(Repair and Ranking)
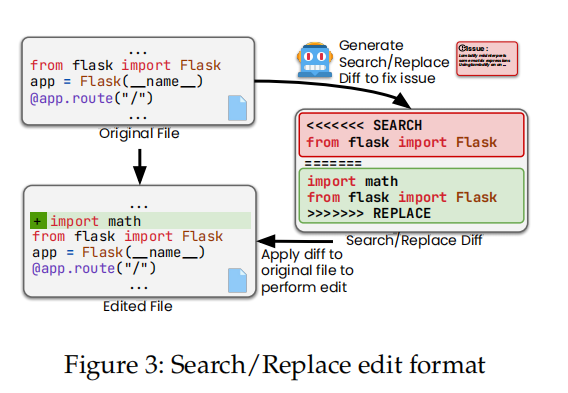
- Patch 生成:
采用 Search/Replace Diff 格式(见 Figure 3):LLM 生成“原代码片段 → 新代码片段”的替换指令,而非重写整个文件。 - Patch 过滤:
执行回归测试(regression test):剔除导致原功能失效的补丁。 - Patch 排序:
使用多数投票(majority voting):对补丁进行标准化(AST 解析 → 去除注释 → 重格式化 → 计算文本 diff),选择出现频率最高的补丁。
实验结果:性能反超、成本最低
主实验(SWE-bench Lite)
|
系统
|
% Resolved
|
Avg. $ Cost
|
File Acc
|
Func Acc
|
|---|
|
Agentless
|
27.33%
|
$0.34
|
68.7%
|
51.0%
|
|
SWE-agent (GPT-4)
|
18.00%
|
$2.51
|
61.0%
|
45.3%
|
|
AutoCodeRover
|
19.00%
|
$0.45
|
62.3%
|
42.3%
|
|
RAG (ChatGPT)
|
0.33%
|
$0.13
|
27.3%
|
11.3%
|
- Agentless 是所有开源系统中修复率最高(27.33%)且成本最低($0.34)的;
- 唯一性分析(Figure 4):Agentless 修复了 15 个其他开源代理均未修复的问题,证明其互补价值。

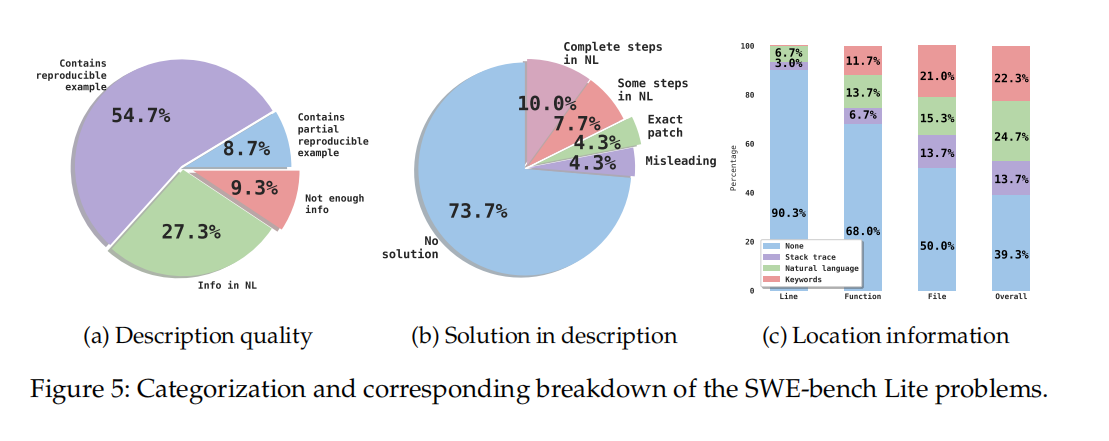
人工分析 SWE-bench Lite:发现三大问题
作者对 300 个 Issue 进行人工分类(Figure 5):
- 4.3% 的 Issue 直接包含修复补丁(Exact patch in description);
- 9.3% 的 Issue 信息不足(Not enough info),无法从描述推断正确修复;
- 4.3% 的 Issue 包含误导性方案(Misleading solution)。
基于此,作者构建了 SWE-bench Lite-S(252 个问题),在该基准上 Agentless 依然保持 28.17% 修复率(排名第 5,开源第 1)。
启示与贡献
- 简单性胜过复杂性:无需 LLM 自主决策,专家设计的流程即可达到 SOTA 性能;
- 成本效益极高:$0.34/bug 的成本,使其具备工业落地潜力;
- 可解释性强:每一步定位与修复均有明确依据,便于开发者审查;
- 基准需更严谨:揭示了 SWE-bench Lite 的数据缺陷,推动社区构建更可靠的评估标准。
开源地址:https://github.com/OpenAutoCoder/Agentless



 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
