


7,639
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
BGE-Base-Zh-V1.5 按照 https://www.aidevhome.com/?id=54 运行失败:
(qnn_env) C:\Users\AI-PC-52\workspace\omni-note>python test2.py
Initializing Tokenizer...
Allocating Global Input Buffers...
Initializing QNN Context...
0.2ms [^main][21544][WARNING] input_data_type: float, output_data_type: float
20.7ms [^main][21544][ ERROR ] Unable to load backend. pal::dynamicloading::dlError(): load library failed
20.9ms [^main][21544][ ERROR ] Error initializing QNN Function Pointers: could not load backend: C:\Users\AI-PC-52\models\qai_libs\QnnHtp.dll
Error initializing QNN Function Pointers: could not load backend: C:\Users\AI-PC-52\models\qai_libs\QnnHtp.dll
SDK版本:
https://qpm.qualcomm.com/#/main/tools/details/Qualcomm_AI_Runtime_SDK?version=2.41.0.251128 下载失败,我使用2.42 版本
然后 python 环境:
qai_appbuilder 2.42.0.73
qai-hub 0.45.0
qai-hub-models 0.30.2
qai_libs 路径:代码里是 qnn_dir = 'C:\\Users\\AI-PC-52\\models\\qai_libs'
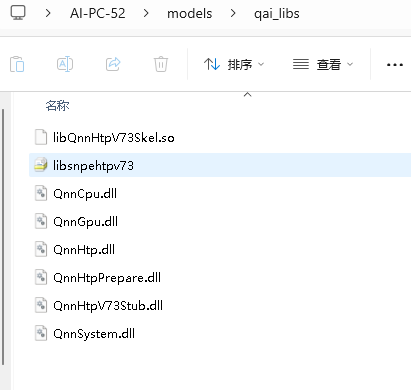
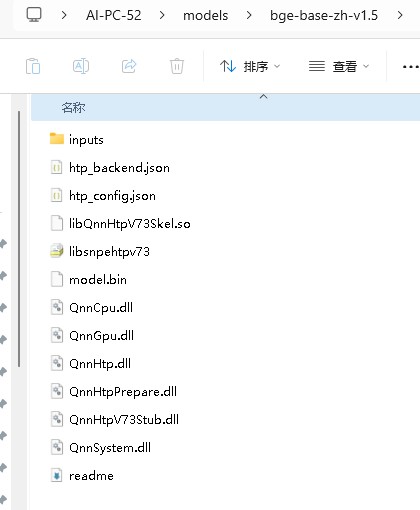
qnn模型路径:代码里是 model_path = 'C:\\Users\\AI-PC-52\\models\\bge-base-zh-v1.5'
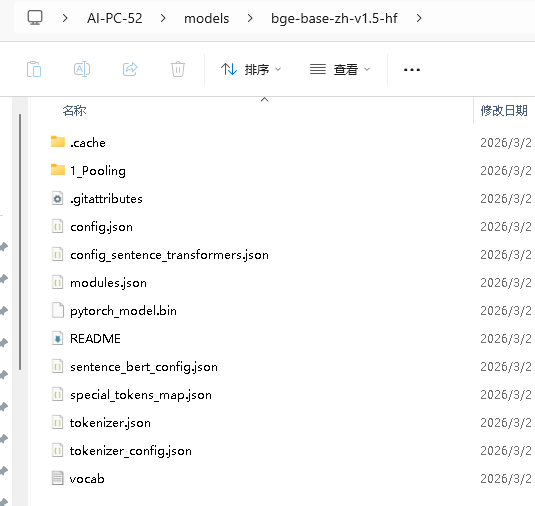
原始模型路径:代码是 tokenizer = AutoTokenizer.from_pretrained("C:\\Users\\AI-PC-52\\models\\bge-base-zh-v1.5-hf")
test2.py 代码:
# ---------------------------------------------------------------------
# Copyright (c) 2024 Qualcomm Innovation Center, Inc. All rights reserved.
# SPDX-License-Identifier: BSD-3-Clause
# ---------------------------------------------------------------------
import sys
import os
import numpy as np
from transformers import AutoTokenizer
from pathlib import Path
# 引入 qai_appbuilder 相关库
sys.path.append(".")
sys.path.append("python")
from qai_appbuilder import (QNNContext, Runtime, LogLevel, ProfilingLevel, PerfProfile, QNNConfig)
####################################################################
# 配置部分
####################################################################
MODEL_NAME = "bge"
MAX_LENGTH = 512
execution_ws = Path(os.getcwd())
# qnn_dir = os.path.join(execution_ws, "qai_libs")
qnn_dir = 'C:\\Users\\AI-PC-52\\models\\qai_libs'
# model_path = execution_ws / "model.bin"
model_path = 'C:\\Users\\AI-PC-52\\models\\bge-base-zh-v1.5'
model_bin = 'C:\\Users\\AI-PC-52\\models\\bge-base-zh-v1.5\\model.bin'
####################################################################
# 全局变量定义
####################################################################
bge_context = None
tokenizer = None
# 定义全局输入缓冲区 (Global Input Buffers)
# 作用:固定内存地址,确保多次推理时底层QNN能读到新数据
g_input_ids = None
g_attention_mask = None
g_token_type_ids = None
g_position_ids = None
class BGEModel(QNNContext):
def Inference(self, input_ids, attention_mask, token_type_ids, position_ids):
# 将全局缓冲区的引用传递给底层
input_datas = [input_ids, attention_mask, token_type_ids, position_ids]
output_datas = super().Inference(input_datas)
return output_datas[0]
def Init():
global bge_context, tokenizer
global g_input_ids, g_attention_mask, g_token_type_ids, g_position_ids
if not os.path.exists(model_path):
print(f"Error: Model file not found at {model_path}")
exit(1)
print("Initializing Tokenizer...")
try:
# 使用模型名称从 Hugging Face 加载 tokenizer(本地模型目录是 QNN 转换后的,缺少 config.json)
tokenizer = AutoTokenizer.from_pretrained("C:\\Users\\AI-PC-52\\models\\bge-base-zh-v1.5-hf")
except Exception as e:
print(f"Failed to load tokenizer: {e}")
print("提示:请确保已下载 BAAI/bge-base-zh-v1.5 模型的 tokenizer 文件到本地缓存")
exit(1)
# --- 初始化全局固定缓冲区 (全零初始化) ---
print("Allocating Global Input Buffers...")
g_input_ids = np.ascontiguousarray(np.zeros((1, MAX_LENGTH), dtype=np.int32))
g_attention_mask = np.ascontiguousarray(np.zeros((1, MAX_LENGTH), dtype=np.int32))
g_token_type_ids = np.ascontiguousarray(np.zeros((1, MAX_LENGTH), dtype=np.int32))
g_position_ids = np.ascontiguousarray(np.arange(MAX_LENGTH, dtype=np.int32).reshape(1, MAX_LENGTH))
print("Initializing QNN Context...")
# 使用 HTP (DSP) 加速
QNNConfig.Config(qnn_dir, Runtime.HTP, LogLevel.WARN, ProfilingLevel.BASIC)
bge_context = BGEModel("bge_context", str(model_path))
def Preprocess(text):
"""
分词并将数据拷贝到全局缓冲区
"""
global g_input_ids, g_attention_mask, g_token_type_ids, g_position_ids
print(f"Preprocessing text: '{text}'")
inputs = tokenizer(
text,
padding="max_length",
truncation=True,
max_length=MAX_LENGTH,
return_tensors="np"
)
# --- 使用 np.copyto 更新全局缓冲区内容 ---
np.copyto(g_input_ids, inputs["input_ids"].astype(np.int32))
np.copyto(g_attention_mask, inputs["attention_mask"].astype(np.int32))
np.copyto(g_token_type_ids, inputs["token_type_ids"].astype(np.int32))
# 打印前5个ID以验证数据更新
print(f"Global Input IDs (first 5): {g_input_ids[0][:5]}")
return g_input_ids, g_attention_mask, g_token_type_ids, g_position_ids
def Postprocess(raw_output):
"""
后处理:Reshape -> 取[CLS] -> 归一化 -> 深拷贝
"""
# 必须拷贝一份数据,否则会被下一次推理覆盖
data = raw_output.astype(np.float32).copy()
try:
data = data.reshape(512, 768)
except ValueError:
print(f"Error: Output shape {data.shape} cannot be reshaped.")
return data
# 提取 [CLS] 向量
sentence_embedding = data[0]
# 归一化
norm = np.linalg.norm(sentence_embedding)
if norm > 1e-12:
sentence_embedding = sentence_embedding / norm
return sentence_embedding.copy()
def Inference(text_input):
global bge_context
# 1. 前处理 (写入全局缓冲区)
input_ids, attention_mask, token_type_ids, position_ids = Preprocess(text_input)
# 2. 设置性能模式 (提高DSP频率)
PerfProfile.SetPerfProfileGlobal(PerfProfile.BURST)
# 3. 执行推理
raw_output = bge_context.Inference(input_ids, attention_mask, token_type_ids, position_ids)
# 4. 释放性能模式
PerfProfile.RelPerfProfileGlobal()
# 5. 后处理
final_embedding = Postprocess(raw_output)
return final_embedding
def Release():
global bge_context
if bge_context:
del bge_context
print("QNN Context Released.")
# ================= 主程序 =================
if __name__ == "__main__":
try:
Init()
# --- 示例 1 ---
text_a = "这是一段测试文本"
print(f"\n[Case 1] Input: {text_a}")
emb_a = Inference(text_a)
print("Embedding (Top 10):", emb_a[:10])
print("Shape:", emb_a.shape)
# 保存为 Numpy 文件
np.save("embedding_a.npy", emb_a)
print("Saved to embedding_a.npy")
# --- 示例 2 ---
text_b = "今天天气不错"
print(f"\n[Case 2] Input: {text_b}")
emb_b = Inference(text_b)
print("Embedding (Top 10):", emb_b[:10])
print("Shape:", emb_b.shape)
# 保存为 Numpy 文件
np.save("embedding_b.npy", emb_b)
print("Saved to embedding_b.npy")
except Exception as e:
print(f"An error occurred: {e}")
import traceback
traceback.print_exc()
finally:
print("\nReleasing resources...")
Release()


把qai_appbuilder降级到2.38



