


304
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享核心类度量表
| 类名 | 属性数 | 方法数 | 总代码行数 | 平均方法行数 | 平均圈复杂度 |
|---|---|---|---|---|---|
| Poly | 1 | 12 | 238 | 19.8 | 4.2 |
| Mono | 4 | 8 | 82 | 10.3 | 2.5 |
| Parser | 9 | 12 | 195 | 16.3 | 5.8 |
| Expr | 2 | 4 | 38 | 9.5 | 2.8 |
| Term | 3 | 6 | 43 | 7.2 | 2.2 |
| Factor接口 | 0 | 2 | 5 | 2.5 | 1.0 |
| 各Factor实现类 | 2-3 | 1-2 | 15-35 | 8-18 | 1.5-3.5 |
| 类名 | OCavg | OCmax | WMC |
|---|---|---|---|
| expr.choice | 1.50 | 2 | 3 |
| expr.Derivel | 1.00 | 1 | 2 |
| expr.ExpFac | 2.00 | 3 | 4 |
| expr.Expr | 1.75 | 4 | 7 |
| expr.ExprFa | 1.00 | 1 | 3 |
| expr.FunFac | 1.00 | 1 | 3 |
| expr.GradFa | 1.00 | 1 | 2 |
| expr.Mono | 3.00 | 12 | 24 |
| expr.NumFa | 1.00 | 1 | 3 |
| expr.Poly | 3.31 | 11 | 43 |
| expr.RecFur | 1.00 | 1 | 2 |
| expr.Term | 1.67 | 5 | 10 |
| expr.VarFac | 1.33 | 2 | 4 |
| Lexer | 2.75 | 7 | 11 |
| MainClass | 2.50 | 4 | 5 |
| Parser | 4.57 | 21 | 64 |
| 总计 | — | — | 190 |
| 平均值 | 2.60 | 4.81 | 11.88 |
OCavg:平均圈复杂度(Average Cyclomatic Complexity),衡量方法的平均复杂度。
OCmax:最大圈复杂度(Maximum Cyclomatic Complexity),表示类中某个方法的最大复杂度。
WMC:加权方法复杂度(Weighted Methods Complexity),类中所有方法圈复杂度的总和,反映类的整体复杂度。
1. 整体情况
所有类的 WMC 总和为 190,平均每个类的 WMC 为 11.88。
平均 OCavg 为 2.60,说明多数方法复杂度较低,结构相对清晰。
平均 OCmax 为 4.81,但个别类的 OCmax 极高,存在复杂度过高的方法。
2. 高复杂度类
Parser
OCavg = 4.57(偏高)
OCmax = 21(很高)
WMC = 64(占总复杂度 1/3)
→ 该类复杂度最高,存在至少一个非常复杂的方法。
expr.Poly
OCavg = 3.31
OCmax = 11
WMC = 43
→ 整体复杂度较高,方法间复杂度不均,存在复杂逻辑。
expr.Mono
OCavg = 3.00
OCmax = 12
WMC = 24
→ 单个方法复杂度较高,包含过多分支或嵌套逻辑。
3. 低复杂度类
多个类如 expr.DeriveFactor、expr.ExprFactor、expr.GradFactor、expr.NumFactor 等 OCavg 为 1.00,OCmax 为 1,结构简单,职责单一,符合良好设计原则。
高内聚类:
Mono:封装了单项式的指数和嵌套表达式,职责单一
Lexer:专注词法分析,内聚性良好
低内聚类:
Poly:承担了多项式运算、求导、替换、字符串格式化等多种职责,方法数达12个,存在职责过重问题
Parser:解析逻辑与语义构建耦合,同时负责递归函数的展开计算
耦合分析:
Poly与Mono形成强耦合(组合关系),这是合理的
所有Factor实现类都与Poly耦合,这是架构设计决定的
Parser与多个Factor实现类直接依赖,耦合度较高
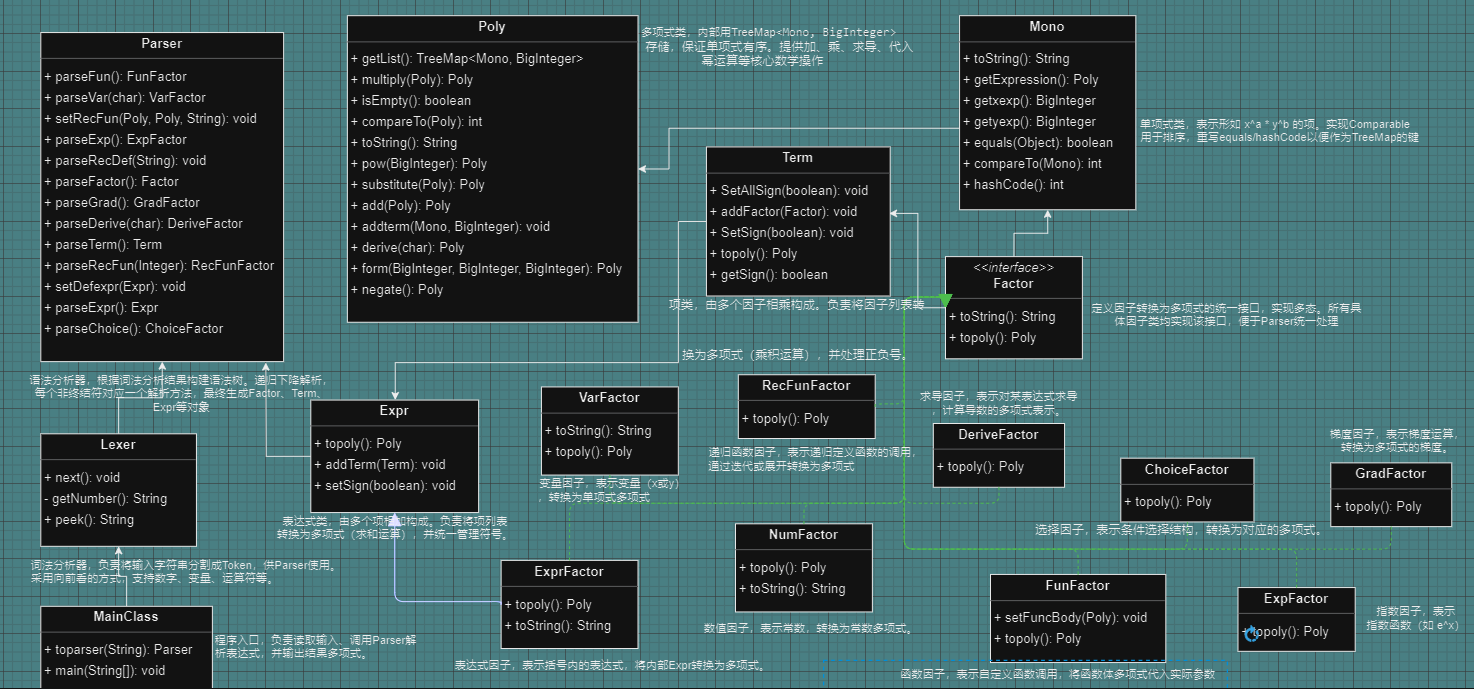
优点:
层次化设计清晰:Expr → Term → Factor 的三层结构很好地表达了表达式的组成
接口抽象合理:Factor接口定义了统一的topoly()方法,使各类因子可以被统一处理
递归下降解析:Parser实现了递归下降解析,代码结构与文法一一对应,易于理解和维护
Poly作为核心数据结构:使用TreeMap存储多项式,自动按Mono排序,便于合并同类项
缺点:
Poly类职责过重:同时承担多项式运算、求导、替换、格式化,违反单一职责原则
Mono设计耦合度高:Mono内部包含Poly类型的expression字段,导致嵌套exp的处理复杂化
缺少中间抽象层:没有对“函数”概念进行抽象,FunFactor和RecFunFactor存在代码重复
字符串解析与语义构建耦合:Parser中混合了解析逻辑和语义构建逻辑
第一次作业(单变量多项式):
核心架构:Expr → Term → Factor
因子类型:常数、变量、表达式因子
Poly使用HashMap<指数, 系数>表示多项式
第二次作业(指数函数、选择式因子、自定义函数):
新增ExpFactor、ChoiceFactor、FunFactor
Poly扩展:支持嵌套exp结构,引入Mono类(x指数 + 嵌套Poly)
增加substitute()方法实现函数代入
选择式因子实现恒等判断
第三次作业(双变量、求导、递推函数):
Poly扩展:支持双变量,Mono增加y指数
新增DeriveFactor、GradFactor、RecFunFactor
实现求导规则(乘法法则、链式法则)
递推函数:在Parser中预计算f0~f5
在第二次作业中,为了支持exp(expr)结构,我对Poly进行了重构:
引入Mono类,将多项式从Map<指数, 系数>改为Map<Mono, 系数>
Mono包含x指数和嵌套Poly,用于表示exp(expr)^xexp结构
新增substitute()方法实现函数代入
重构前后对比:
| 度量项 | 重构前 | 重构后 |
|---|---|---|
| Poly方法数 | 8 | 12 |
| 平均方法行数 | 15 | 19.8 |
| 圈复杂度 | 2.8 | 4.2 |
重构带来了更强的表达能力,但也增加了复杂度。
如果新增三角函数因子sin(factor)和cos(factor),当前设计的扩展性:
需要修改的内容:
新增SinFactor、CosFactor实现Factor接口
修改Lexer识别"sin"/"cos"
修改Parser增加解析分支
修改Poly增加三角函数处理(Mono需要扩展表示三角函数类型)
扩展性评估:
Factor接口设计良好,新增因子只需实现topoly()
Poly需要较大修改:Mono需增加trigType和trigParam字段
求导规则需要新增三角函数求导实现
1.hw1中出现的bug
(1)表达式中常数前出现正号会触发RuntimeError,bug位于Parser类ParseFactor方法
原因:职责不清:parseFactor 承担了过多职责,既解析普通因子,又尝试解析常数,导致符号处理逻辑重复且易错。符号处理的重复:表达式、项、因子三层都有符号处理逻辑,但规则不一致,容易在边界条件上出错。
改进方案:将常数因子的解析独立为 parseNumber()。在 Lexer 中增加 peekNumber() 方法,直接返回数字字符串,避免符号干扰。统一符号处理:只在表达式层和项层处理正负号,因子层不再处理任何符号。
(2)当最终结果为0时,则会什么也不输出,bug处于Poly类的toString方法
原因:缺少对空多项式的特殊处理。没有为 Poly 定义明确的“零多项式”表示,导致输出与数学含义不符。
改进方案:在 toString() 开头添加判断:if (list.isEmpty()) return "0";统一规范:将空 Poly 视为数学上的0,所有运算应保持此语义。
2.hw2中出现的bug
(1)在一些情况下乘法会出现错误,bug位于Mono的getMono方法,该方法返回Mono的Monos属性原件,导致乘法操作之后可能改变Mono本身属性,可能影响后续运算结果
原因:可变对象共享:Mono 内部的 expression 是可变对象,直接暴露给外部,破坏了封装性。未使用防御性拷贝:在返回内部引用前未进行深拷贝。
改进方案:将 Mono 设计为不可变类:构造函数中复制传入的 Poly,所有 getter 返回不可变视图或深拷贝。在 Poly 的运算方法中,确保所有对 Mono 内部 expression 的操作都基于新创建的副本。使用 Poly.copy() 方法显式拷贝。
(2)在表达式出现多层exp函数嵌套时,会出现TLE,bug位于Poly和Mono类的toString方法
原因:缺乏缓存:没有对已计算过的 Poly 字符串结果进行缓存。递归深度大时,未考虑性能优化,直接使用字符串拼接。
改进方案:为 Poly 添加 toStringCache 字段,在第一次计算后缓存结果,下次直接返回。使用 StringBuilder 替代字符串拼接,减少临时对象。设计一个访问者模式,将字符串生成与数据结构分离,并支持缓存。
(3)在选择式出现短路时,若未被选择的那一项复杂度很高则会TLE,bug位于FunFactor的构造方法中
原因:缺乏延迟求值:所有因子在解析时就被立即转换为 Poly,而不是在真正需要时才计算。选择式因子的语义要求短路,但实现中没有体现。
改进方案:将因子接口设计为可延迟求值,例如引入 LazyFactor 包装,或使用函数式接口 Supplier<Poly>。在 ChoiceFactor.topoly() 中先计算条件,再根据结果选择计算哪一个分支。
3.hw3中出现的bug
在递归函数定义式中,若系数位数大于一时则会出现解析错误的情况,bug位于Parser的parseRecDef中
原因:解析逻辑手写且复杂,容易出错。未使用正则表达式或专门的数字解析器,导致代码脆弱。对输入格式的假设过于理想化,未考虑多位数、符号等边界情况。
改进方案:将解析逻辑封装成独立函数 parseNumber(),使用 Character.isDigit() 循环读取。引入 Lexer 支持直接返回数字 token,避免在解析器中手动处理字符。
3.2 复杂度与bug关联分析
| 方法 | 代码行数 | 圈复杂度 | 是否出现bug |
|---|---|---|---|
Parser.parseFactor | 45 行 | 15 | 是 (hw1 bug1) |
Poly.toString | 35 行 | 8 | 是 (hw1 bug2, hw2 bug2) |
Mono.getExpression | 1 行 | 1 | 是 (hw2 bug1,设计问题) |
ChoiceFactor.topoly | 5 行 | 2 | 是 (hw2 bug3,设计问题) |
Parser.parseRecDef | 50 行 | 23 | 是 (hw3 bug1) |
NumFactor.topoly | 4 行 | 1 | 否 |
VarFactor.topoly | 7 行 | 2 | 否 |
观察:出现 bug 的方法普遍具有较高的圈复杂度(>8)或较长的代码行数。一些设计缺陷(如可变对象共享)并不直接反映在圈复杂度上,但通过降低耦合和增强封装可以避免。
降低复杂度的方法:
分解方法:将 parseFactor 拆分为 parseNum、parseVar、parseExp 等独立方法,每个方法只负责一种因子,降低圈复杂度。
封装不变性:将 Mono 设计为不可变类,使用 copy() 方法返回副本,避免共享可变状态。
缓存与延迟计算:为 Poly.toString 添加缓存;将选择式因子的分支计算改为惰性求值,避免提前计算。
统一符号处理:将符号处理统一到表达式层,因子层不再处理符号,减少重复逻辑。
通过以上方法可以将复杂方法的圈复杂度降低,同时提高代码的可读性和可维护性,从根源上减少 bug 的产生。
单元测试:为Poly、Mono等核心类编写JUnit测试
边界测试:0^0、exp(0)、指数为0等边界情况
随机测试:随机生成表达式,与Python sympy对比结果
针对ChoiceFactor的跳过因子判断:
1
f(x)=(x+1)^8
[(1==1)?1:f(f(f(f(f(f(f(f(f(f(f(f(f(f(f(f(f(f(f(f(f(f(f(f(f(f(f(f((x+1)))))))))))))))))))))))))))))]
此样例可能引发TLE
针对使用GCD化简式子:
1
f(x)=exp(exp(exp(exp(exp(exp(x)^2)^2)^2)^2)^2)^2
f(f(f(f(x))))
此样例会导致GCD出现递归,从而TLE
4.3 有效性评估
随机测试能发现大部分语义错误,但无法保证完全正确。使用sympy作为Oracle时,需注意sympy的化简策略与作业要求可能不完全一致。
合并同类项:Poly使用TreeMap存储,自动合并指数相同的项
系数化简:添加项时,若系数相加为0则删除该项
输出优化:
系数为1时省略
系数为-1时只保留负号
指数为1时省略指数
exp内部表达式为简单形式时省略括号
正确性问题:如果优化代码覆盖情况不够全面,则会出现错误的输出。
性能问题:合并同类项将会使多项式相关计算所需时间增加
| 作业 | 正确性辅助 | 性能优化 | 备注 |
|---|---|---|---|
| 第一次 | 20% | 10% | 主要参考了递归下降解析结构 |
| 第二次 | 30% | 20% | 求导规则、替换逻辑参考AI |
| 第三次 | 40% | 30% | 复杂求导实现、递推展开参考AI |
Bug查找:使用AI分析代码逻辑,发现Poly.derive中的局部变量问题
测试用例生成:使用AI生成边界测试用例
房间中有1-3名同学存在大量Javadoc注释,方法命名规范异常统一,推测使用了AI辅助生成。这类同学通常代码结构清晰,但可能存在隐藏的逻辑bug(如选择式因子的恒等判断实现不完整)。
层次化设计:Expr-Term-Factor三层结构很好地体现了表达式的递归定义
接口与实现分离:Factor接口使各类因子可被统一处理
递归下降解析:解析器结构与文法一一对应,易于扩展
嵌套exp的表示:如何用多项式表示exp(exp(x))这样的嵌套结构是最大挑战
求导实现:乘法法则、链式法则的正确实现需要仔细设计
选择式因子的恒等判断:多项式化简后判断是否为0,需要保证化简的完备性
将Poly拆分为多项式表示和运算两个类
抽象函数基类,统一处理exp、f(x)等函数因子
引入访问者模式处理求导、替换等操作
增加设计模式讲解:在作业前介绍组合模式、访问者模式在表达式处理中的应用
提供更清晰的架构指引:给出推荐的类结构和职责划分,避免学生走弯路

