


302
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享整体采用以下思路:
目前的输入输出还是太过笨重:
| method | CogC | ev(G) | iv(G) | v(G) |
|---|---|---|---|---|
| ==Average== | 1.17 | 1.39 | 1.59 | 1.88 |
| Class | OCavg | OCmax | WMC |
|---|---|---|---|
| ==Average== | 1.74 | 2.89 | 9.82 |
| io.Outputter | 2.75 | 7.0 | 33.0 |
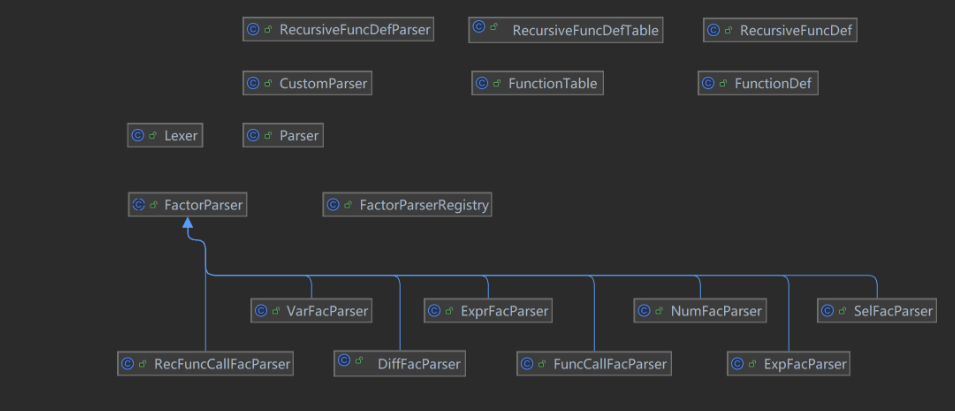
factorParser()的优化
//Parser
public Factor parseFactor() {
for (FactorParser p : FactorParserRegistry.DEFAULT.parsers()) {
if (p.canParse(lexer)) {
return p.parse(this);
}
}
throw new IllegalArgumentException("Unexpected token in factor: " + peek());
}
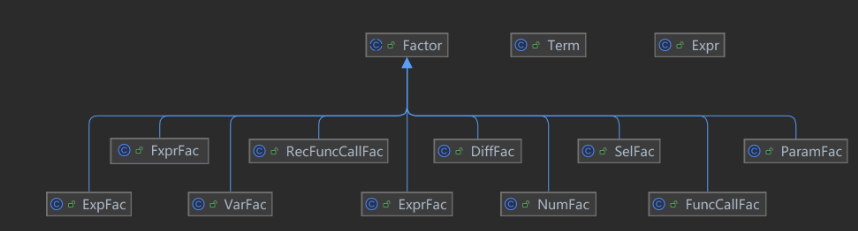
由Poly到Fxpr
a*x^b变为a*x^b*exp(c),带来原先的Poly和toPoly()方法的重写(变为Fxpr和toFxpr())自定义函数
-==替换机制==:先替换,再和原来一样化简Fxpr
Mono的进一步迭代
由于变量因子的扩展,原先只记录单指数b的设计不够用了,于是拓展为HashMap记录各变量对应指数
HashMap<String, BigInteger> newVars = new HashMap<>(this.varPowers);
新增求导算子
toDiff()方法自定义迭代函数
整体思路类似第二次作业中的自定义函数
问题:普通函数本质是单次参数替换,保留 AST 很自然;递推函数本质是多层展开求值,直接走 Fxpr 更方便。
但是,这样会引出返回值不统一的问题,例如:
解决:将Fxpr也包装成Factor(即:新建一个FxprFac类)
三次迭代下来,我的bug基本都集中于Outputter对exp括号内输出格式的处理上
exp(x*y)/exp(x*exp(x))这样的错误没有发现太重的错误,和自己一样多为输出格式错误,例如把exp(1)直接按e输出
在理解了递归下降解析法的前提下,第一单元的设计并没有太难理解的地方。设计好拆分-解析-输出的大框架后,后续两次迭代虽然增加了不少功能,但总体上还是在原有架构基础上进行的,没有大规模重构。所以说,在上手码代码之前,一定要明确自己是在干什么、要实现什么,而不是一头雾水地就开始赶作业敲键盘了。

