


302
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享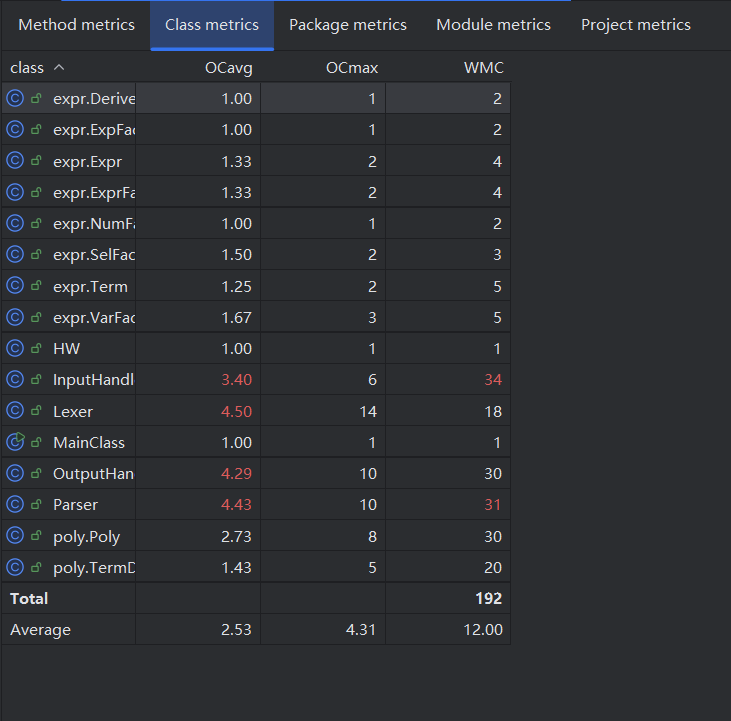
WMC (Weighted Method Count - 加权方法数):反映类的整体复杂度。
OCavg (Average Operation Complexity - 平均操作复杂度):反映类中方法的平均分支数。
OCmax (Max Operation Complexity - 最大操作复杂度):反映类中最复杂方法的分支数。
从度量图中可以明显看出,程序的复杂度集中在“解析”与“处理”类中:
Lexer 的 next() 方法包含了大量的 if-else if 字符匹配分支,导致 OCmax 高达 14。
Parser 的 parseFactor() 方法由于需要通过 switch-case 判定生成不同的因子(ExprFactor, ExpFactor, DeriveFactor 等),控制分支极多,推高了整体复杂度。
InputHandler 承担了极其繁重的预处理任务(去空格、括号栈匹配、递推函数展开等),导致 WMC 居全项目之首。
OutputHandler 在处理字符串拼接时,为了应对严苛的 exp() 必要括号判断,逻辑较为繁琐。
poly.Poly (WMC=30, OCmax=8):主要复杂度集中在 multiply 和 add 中的双重 for 循环与同类项合并逻辑。
除了上述类外,所有的 AST 节点(如 Expr, Term, VarFactor, SelFactor 等)的 OCavg 均在 1.0 ~ 1.6 之间,WMC 基本在 2 ~ 5 之间。这说明多态和层次化设计被很好地贯彻了,复杂的求导和计算逻辑没有堆砌在 AST 节点中,而是巧妙地委托给了底层的数学模型。
高内聚体现:数学核心引擎 poly 包具有极高的内聚度。TermData 完全封装了单项式的所有属性和数学运算(加、乘、求偏导)。
低耦合体现:AST 树模块与数学计算模块通过统一的接口方法 toPoly() 建立单向联系。解析阶段只负责建树,不关心怎么计算;一旦调用 toPoly(),控制权移交底层引擎,两者互不干扰。
耦合较高的部分:Parser 类由于扮演着“工厂”的角色,与 Lexer 强耦合,同时也与 expr 包下的几乎所有因子类(ExpFactor, VarFactor 等)存在依赖关系。
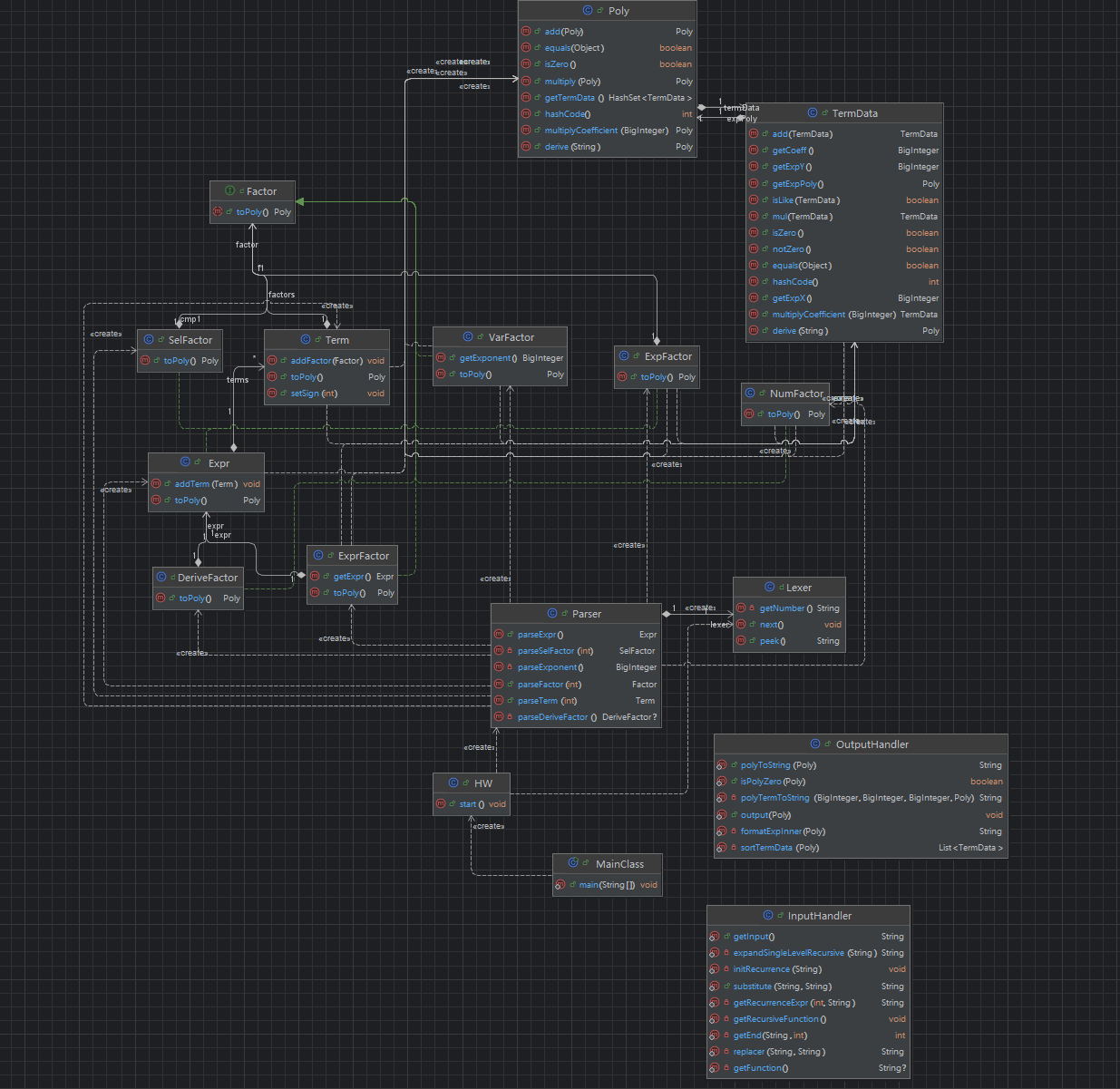
InputHandler类:用于输入的预处理,包括去空白字符,后来加入函数和非递推函数后通过替换的方法将其展开
Lexer,Parser类:用于分割解析文法,为创建表达式树做准备。
Expr,Term类,Factor接口:表达式的各级别的存储和向多项式的转换。
Poly,TermData类:用于存储多项式和各项,以及相关计算。
OutputHandler类:用于实现要求的输出
hw1中我的架构分为两层:顶层的抽象语法树和底层的数学模型 Poly。那时的 Poly 底层仅仅是一个简单的 HashMap<Integer, BigInteger>(映射 x 的指数到系数),方便合并同类项。
hw2引入了嵌套的 exp() 函数,为了更好地处理新的数学模型,我将Poly做了重构,在Poly包引入了 TermData 不可变对象,重写了加法乘法,相等方法,虽然在效率方面降低,但是逻辑很清晰。处理函数我使用括号匹配+replace方法预处理,不必修改抽象语法树。
hw3引入双变量xy和偏导数,自定义递推函数。这次不必修改之前的实现,求导机制在数学模型中实现即可与AST无关,递推函数则继续预先处理,不必修改Parser逻辑。
重构带来的是更加清晰的代码结构,也为后续迭代带来很大的便利。
语法分析层:微小拓展
底层数学模型:TermData 的结构天生支持横向扩展,增加超越函数项即可,合并同类项机制依旧有效,不必做大修改。
语法解析器错误:因子前的符号处理缺失,这是对语法理解不到位或者实现时思路不清晰导致;遇到形如 dx(exp(x)) 或选择式因子 [(A==B)?C:D] 时,程序在正常表达式中突然报错 Expected '==', but got ')' 或把 ? 送进了常数解析分支,即处理新增算子时没有显式调用 lexer.next();解决方法是引入防御性编程和断言检查以便于在自己测试是能方便地发现bug。即如果当前 Token 与预期不符,立即抛出附带上下文信息的异常。
函数预替换:括号匹配缺陷:早期寻找函数实参的右括号时,简单地使用了 while (c != ')')。会在第一个 ) 处提前截断,无法处理函数嵌套调用数据。后续修复为用工具方法,利用栈处理括号。
误用不可变对象:Poly 和 TermData 被设计为了不可变对象(即内部属性 final,任何修改都会返回一个新对象)。在求导累加时,写成了 newPoly.add(td.derive(allVar));。由于没有将返回的新对象重新赋值给 newPoly,导致加法结果丢失。
函数表达式的预替换:整体替换时未加括号导致替换后优先级变更
出现 Bug 的高危方法通常是控制流集中的,例如Lexer.next(),Parser.parseFactor(),InputHandler中的方法。这些方法往往超过 50 行,控制分支(if, switch, while)极多,难以测试。
解决:首先应该将控制分支的内部处理为新的函数,减少行数且便于测试,比如将逻辑拆分到 parseVarFactor(), parseExpFactor(), parseSelFactor() 等独立的小方法中。Lexer 中对不同算子(dx, dy, grad, ==)的判断使用了过多的 if-else。可以使用正则表达式进行统一的切词,或者维护一个 HashMap<String, TokenType> 的映射表,查表解析以代替硬编码的分支判断。
黑盒测试:根据语法要求设计各种嵌套和结合各种因子的表达式测试解析是否正确;
白盒测试 :结合他人的代码结构,如观察对方的各种代码逻辑是否符合其方法名,进而发现bug
,### 分析自己进行的优化
本单元作业中我的优化不多,一是利用TermData类对表达式做同类项合并,二是对指数的乘法exp(a)*exp(b)类转化为exp(a+b)(考虑到可能的因式分解,这并不总是最短)。
这两个优化融入了数学模型的计算部分,没有设计额外的函数,十分简洁,不会影响正确性。
在函数表达式的预替换时,为了保证正确性,尽可能的加了括号,也没有在后续优化括号直接嵌套的层数;显然
对于直接连续的括号,可以根据表达式或因子的要求去除一部分,避免如(((((x+1)))))的出现
经过OO第一单元的学习,我对递归下降的思想有了更进一步地理解,能够熟练掌握抽象语法树的书写。同时,我对代码复杂,类的规模的意义掌握更深,复杂与高耦合的代码很不利于后续的迭代和bug寻找。
通过在互测阅读他人的代码结构,我不仅能高效地找到对方架构中的脆弱点,更在潜移默化中反思了自己架构的优劣。
提供更多关于代码测试的指导。

