


304
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享经过三次迭代,整个代码规模有2000多行(感觉有点多哦,看来其他人的博客,大家的代码大概只有1000多行,具体原因下面再分析吧),使用IDEA的Statistic插件统计分析得到各类的代码规格:
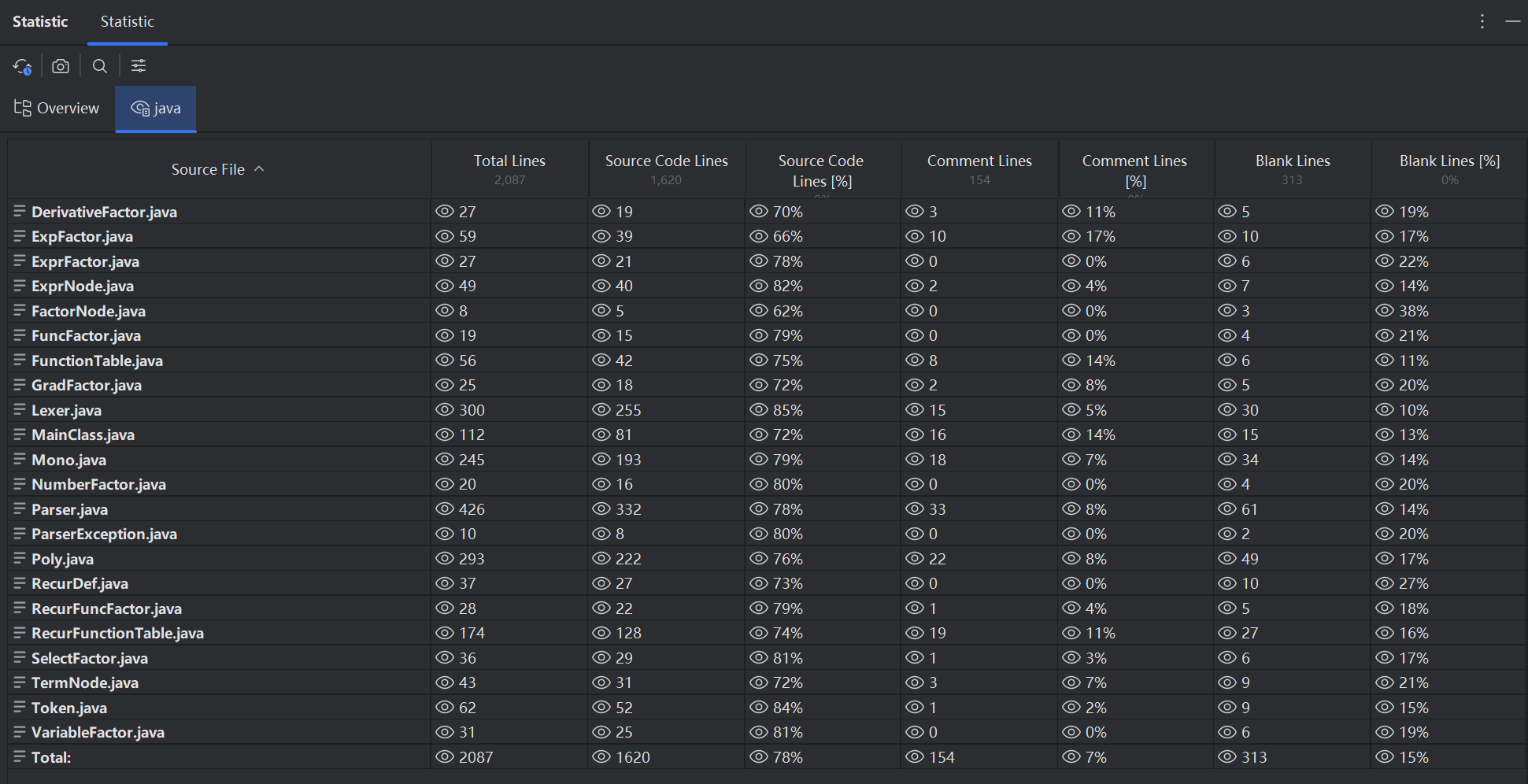
可以看到有几个类比较长,我们依次来分析
1.首先是Lexer类,做词法分析的任务,这个类比较长的主要原因是对每个字符都进行了单独的分析、新建token,这样就比较冗长。在互测的时候,看到有同学将所有token的新建写成了一个通用的方法,这是很值得学习的。
2.然后是Parser类,这个类比较长的原因主要有2个,一是我写了很多抛出异常,这会让代码变多变长,但是在debug的时候确实超级方便,能快速定位bug所在,我两次debug都在5分钟内迅速定位。二是我把对递推函数定义式的解析分离出来了,一是它不是传统的表达式,二是它的格式是固定的。为什么这样做呢,因为我在存储递推函数定义式的时候只想要6个参数,我把这6个参数传给RecurFunctionTable,如果把整个定义式传给RecurFunctionTable,那它还要做解析,但这就违背了Parser负责解析的任务。那可不可以把它当成普通表达式解析的同时又能把6个参数提取出来的方法呢,我想是有的,只是我没有想到。
3.还有2个比较长的类是Mono类和Poly类,因为这两个类除了承担了计算的任务,还承担了输出的任务,我直接重写了toString方法来实现输出,其实这样不太好,指导书里也建议把输出的任务单独写一个方法。
使用IDEA的MetricsReloaded插件分析得到如下所示的复杂度分析图
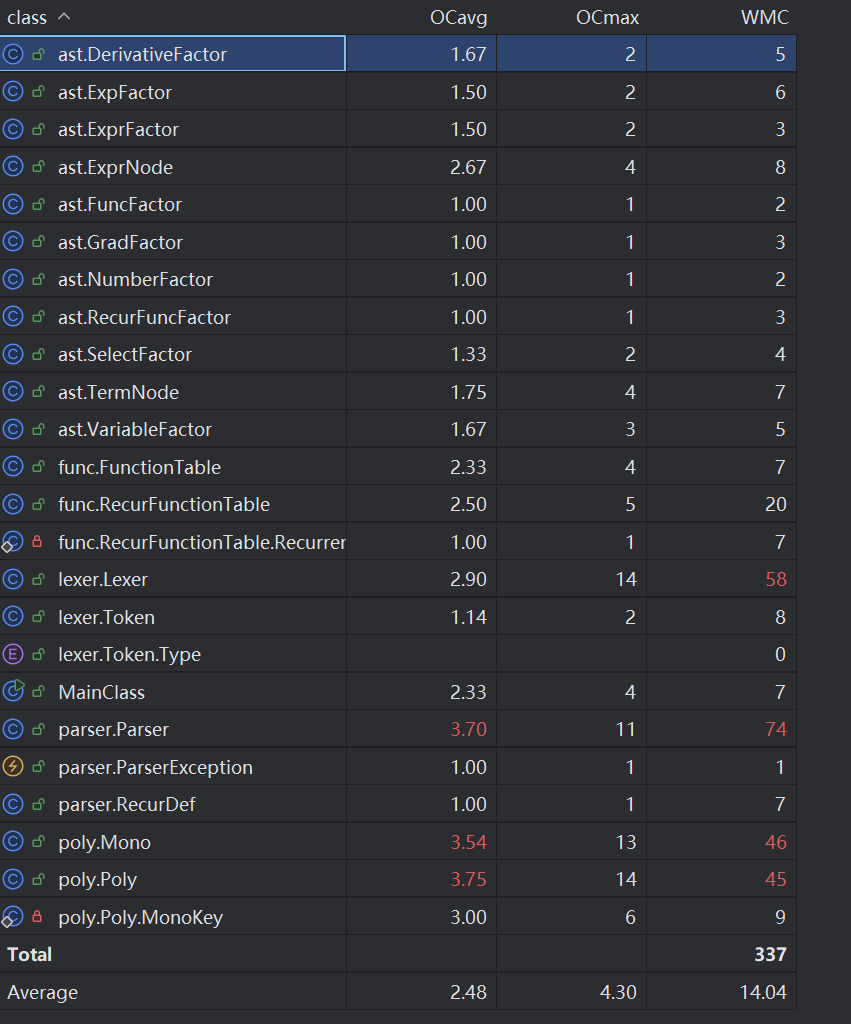
可以看出Parser类、Mono类、Poly类复杂度较高,结合上面的数据来分析类的内聚和耦合情况
1.内聚性;ast结点的内聚性较好,职责单一;lexer类和parser类内聚性中等,分别承担词法分析和语法分析的任务;Mono类和Poly类内聚性中等,分别进行多项式的运算和单项式的运算。
2.耦合性:Mono类和Poly类耦合性较高,Poly类的很多计算方法高度依赖于Mono类的计算;Parser类与ast结点的耦合度较高,Parser类几乎每个方法都要与ast结点进行交互。
(1)首先是第一次迭代,我参考了oolens给出的架构建议,以及往年学姐学长的架构,设计了MainClass、lexer、parser、ast结点、poly五个方面,先在MainClass里预处理,去掉所有空白符,然后在lexer里词法解析,再在parser里语法解析,递归下降构建ast结点树,让每个ast结点调用toPoly方法进行计算,合并同类项后输出。
(2)第二次迭代,新增的选择式因子只需要添加一个新的选择式因子类即可;新增的指数函数除了要添加新的因子类,还需要将Mono变成“系数 * x^指数 * exp(参数)”的形式;新增的函数调用,我是新增了一个FunctionTable类,用来存储函数定义式,同时在这个类里实现参数的替换。
(3)第三次迭代,新增的求导算子只需要在Poly类和Mono类里新增求导的计算方法即可,单项式的求导很简单,很容易实现;新增的递推函数,我仔细考虑后认为非递推函数和递推函数是2个不同的函数,只不过函数名都是f罢了,所以我把二者当成了2个不同的因子来处理,同时新建了一个RecurFuncTable类来存储递推函数的定义式。
参考往年题,可以新增正余弦函数,也是新增相应的因子类,实现FactorNode接口,在Poly和Mono类中实现正余弦函数的计算方法。不过这个化简可能会有点麻烦,我还没有具体想过这个事。
(1)第一次迭代,我在中测的一个点上卡了很久,身边的同学都没有卡这个点的,我迟迟没有找到原因,后来在看给出数据点的测试点的时候,发现有些测试点没有任何空白符,这个时候我意识到是我对指导书的理解有问题,于是重新审视了输入合法性的要求,解决了这个问题。这启示我一定要仔仔细细阅读指导书,把每一处都读懂,每一处都不要忽视。我后来也确实是这样做的,hw2和hw3的指导书前前后后读了很多遍,确保自己正确理解了题目要求。
(2)第二次迭代,新增了token,但是我在处理正负号的方法里并没有处理新增的token,虽然强测没被测出来,但是互测被狠狠hack了15次(哭),但是客观的讲,我还是非常感谢互测中找到我bug的同学,因为这里不修改,第三次迭代必然要出问题。
(3)第三次迭代,强测wa了2个点,是同一个错误,处理递推函数定义式中的函数项有错误,对负号的理解有问题,我自己在测试的时候没有考虑到这点,自测的时候还是不够全面,没把所有情况考虑到,这个问题在以后的作业中一定要改。
(4)对比分析bug出现的方法和未出现的方法,发现bug出现的地方确实是方法比较复杂,复杂就容易出错,在以后的作业中还是要思考如何降低方法的复杂度,以免出bug,比如可以思考从数学角度降低方法的复杂度、相似作用的方法可以合并成一个方法,不要写好多次等等。
(5)另外说一句题外话,我在2次debug的时候都非常顺利,5分钟内就快速定位了bug所在,究其原因,我想除了我对自己代码的掌握度较高,知道哪里可能出错,还有就是我写了很多抛出异常,虽然代码变长了很多(甚至有的方法超行数了),但是确实给我找bug带来了很大便利。至于如何平衡方法过长和多写抛出异常的关系,这是一个值得思考的问题。
1.首先我在三次互测中只成功hack了别人一次(这听起来有点惨,但是从0到1总是好的!),第一次作业大家几乎都没什么bug,第二次作业我在a房,大家似乎也真的没什么bug(不知道该哭还是该笑),第三次成功hack了别人一次。
2.由于oop课程并不涉及互测,所以客观的讲,我并不知道如何高效的进行互测,后来一些学长给了我很多建议,我才慢慢知道如何做,在此特别感谢lc学长、wzh学长、sqh学长!
3.接下来说说互测的策略
(1)首先是在测试自己的代码时用到了一些测试用例,以及自己代码中遇到的错误,这些都可以用来hack别人。
(2)二是搭评测机(但是这种方法我在U1的三次互测中还没用过,打算从U2开始试着搭评测机)
(3)三是结合对方的代码构造特殊样例,比如如果他在处理选择式因子时,先替换了,而不是先确定需要因子C还是因子D,就可以构造一个让对方tle的样例;再比如说,他在优化exp部分,可能为了少一组括号而导致输出不合法,或者第三次迭代增加了y因子,他忘记考虑这件事了,这个时候就可以去看看他的代码,我就成功用这个点hack了一个人;再比如说,他可能函数调用直接替换,而不是计算成poly形式,也可以构造特殊样例让他tle。
1.我主要做了以下几个优化:一是正项提前,这个在构建表达式树的时候不用考虑,在输出的时候把系数的正负作为key之一就可以了;二是exp非表达式因子可以少一层括号,这一点我是单独判断的,看它是不是非表达式因子,是就不用再加一层括号,不是就加一层括号。总的来说,这两个优化都比较简单,只是在输出部分处理一下即可,其他架构完全不用动。
2.再来说说我没做的优化,就是exp提系数的优化,说实话,这个优化非常麻烦,我在写hw2时仔细考虑过这个问题,首先就是不是所有都能提系数,二是提了系数也不一定会变短,三是不是提最大公约数是最短的,如果真的要写好,难度甚至超过了写oo作业本身,所以综合考虑,我认为没有必要做这个优化。(不过好像影响也不大,我hw2没做这个优化,也被分到了a房,所以,还是先保证正确性吧,优化是次要的!)
1.在U1中我对大模型的使用主要集中在java语法方面,虽然上学期学了oop,但是隔了几个月没写java,语法还是有些忘了,包括一些不知道用什么方法写的部分,也问了大模型,这点我觉得大模型做的还不错的。
2.我这次没用大模型帮我debug,上面提到,因为我对自己代码的掌握度较高,而且写了很多抛出异常,所以在debug的时候很快就定位了。虽然这次我没用它帮我debug,但是我觉得用大模型辅助找bug、辅助构造测试用例以及辅助搭评测机都是很不错的。
总的来说,是实现了从0到1的进步吧,学会了怎么设计出一个合理的、迭代过程中不需要大改的架构,对java语法进行了比较充分的复习,学会怎么构造测试用例在提交前测试自己的代码,还跟几位学长学习了怎么高效地进行互测。
1.建议每次作业除了提交代码,也提交自己架构的设计思路,在一定程度上减少AI的滥用吧
2.建议加强引导,让大家更多地关注正确性,而非一味追求性能分(研讨课上好像几乎都在讨论怎么优化,感觉有点偏离oo课程设计的初衷)

