


302
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享一、基于度量指标的分析:
使用metric reloaded工具,对第三次作业代码分析如下。
首先给出类的属性个数(NOF/CSA)、方法个数(NOM/CSO)、类总规模(LOC)的表征:
| class | NOF | NOM | LOC |
|---|---|---|---|
| DxNode | 1 | 15 | 11 |
| DyNode | 1 | 15 | 11 |
| Element | 4 | 34 | 255 |
| Exp | 2 | 15 | 22 |
| ExprFactor | 2 | 15 | 13 |
| ExprNode | 1 | 16 | 17 |
| Func | 1 | 15 | 12 |
| FunctionRegistry | 9 | 20 | 110 |
| Lexer | 3 | 15 | 53 |
| Main | 0 | 14 | 35 |
| Monomial | 5 | 28 | 261 |
| Number | 1 | 15 | 10 |
| Parser | 1 | 22 | 172 |
| RecFunc | 2 | 15 | 13 |
| Select | 4 | 15 | 23 |
| Solver | 3 | 15 | 16 |
| TermNode | 2 | 16 | 22 |
| Variable | 2 | 15 | 22 |
| Total | 44 | 315 | 1078 |
| Average | 2.44 | 17.50 | 59.89 |
总代码量(1078行)对于一个表达式求导/解析器来说不是很离谱,但总体上确实暴露了“头重脚轻”的问题。仔细看看 Monomial 和 Element 类,Monomial 261行, Element 255行,这两个类的代码量加起来超过了 500 行,几乎占据了整个项目一半的体积。而其他的叶子节点(如 Number, DxNode 等)大多只有 10-20 行;Element 的方法个数是34,Monomial 是28,明显多于其他类。这种现象的出现是很自然的,因为我的Element类承担了过重的责任,里面包含了数学计算、辅助优化逻辑、字符串输出部分;Mono也是大致如此,甚至因为它承担了核心的拆分exp内表达式的重任,而显得更加冗长复杂,实际上其中正好藏着一个卡了L3互测的问题。我觉得至少输出逻辑是可以提出去自成一个类的,可以防止两个核心类过度膨胀。
唯一令人开心的是属性个数指标:绝大多数类的属性个数在 1 到 4 个之间,这是一个非常健康的数据。但 FunctionRegistry 的属性个数达到了 9 个,这其实也是一个设计时候的问题,FunctionRegistry 作为一个静态记录表,里面东西多点倒也正常,问题是我当时不想把 RecFunc 递归函数部分写的太冗长,又觉得FunctionRegistry 如果只是个记录数据的静态结构比较没用,于是把他的核心递推逻辑交给了 FunctionRegistry (实际上它的方法数也来到了20),结果又是头重脚轻的,或许归还给 RecFunc 来处理会自然一些?
注:我其实比较好奇为什么像DxNode这样的节点类只有 10 几行代码却有 15 个方法,AI说是因为继承了父类的方法或使用了自动生成工具,不知道是否属于正常现象?
接下来是每个方法规模、每个方法的控制分支数目的表征数据:
| method | BRANCH | CogC | CONTROL | ev(G) | iv(G) | LOC | v(G) | RLOC |
|---|---|---|---|---|---|---|---|---|
| Node.toElement(Element) | - | - | - | - | - | - | - | 33.33% |
| DxNode.DxNode(Node) | 0 | 0 | 0 | 1 | 1 | 3 | 1 | 27.27% |
| DxNode.toElement(Element) | 0 | 0 | 0 | 1 | 1 | 5 | 1 | 45.45% |
| DyNode.DyNode(Node) | 0 | 0 | 0 | 1 | 1 | 3 | 1 | 27.27% |
| DyNode.toElement(Element) | 0 | 0 | 0 | 1 | 1 | 5 | 1 | 45.45% |
| Element.Element() | 0 | 0 | 0 | 1 | 1 | 3 | 1 | 1.18% |
| Element.Element(HashMap) | 0 | 0 | 0 | 1 | 1 | 3 | 1 | 1.18% |
| Element.getStandard() | 0 | 0 | 0 | 1 | 1 | 3 | 1 | 1.18% |
| Element.getTerms() | 0 | 0 | 0 | 1 | 1 | 3 | 1 | 1.18% |
| Element.isZero() | 0 | 0 | 0 | 1 | 1 | 3 | 1 | 1.18% |
| Element.subtract(Element) | 0 | 0 | 0 | 1 | 1 | 3 | 1 | 1.18% |
| Exp.Exp(BigInteger, Node) | 0 | 0 | 0 | 1 | 1 | 4 | 1 | 18.18% |
| ExprFactor.ExprFactor(Node, BigInteger) | 0 | 0 | 0 | 1 | 1 | 4 | 1 | 30.77% |
| ExprFactor.toElement(Element) | 0 | 0 | 0 | 1 | 1 | 5 | 1 | 38.46% |
| ExprNode.ExprNode() | 0 | 0 | 0 | 1 | 1 | 3 | 1 | 17.65% |
| ExprNode.addTerm(Node) | 0 | 0 | 0 | 1 | 1 | 3 | 1 | 17.65% |
| Func.Func(Node) | 0 | 0 | 0 | 1 | 1 | 3 | 1 | 25.00% |
| Func.toElement(Element) | 0 | 0 | 0 | 1 | 1 | 6 | 1 | 50.00% |
| FunctionRegistry.clear() | 0 | 0 | 0 | 1 | 1 | 11 | 1 | 10.00% |
| FunctionRegistry.defineFunction(String) | 0 | 0 | 0 | 1 | 1 | 5 | 1 | 4.55% |
| FunctionRegistry.defineRecursiveFunction(...) | 0 | 0 | 0 | 1 | 1 | 5 | 1 | 4.55% |
| FunctionRegistry.getFuncBody() | 0 | 0 | 0 | 1 | 1 | 3 | 1 | 2.73% |
| Lexer.Lexer(String) | 0 | 0 | 0 | 1 | 1 | 4 | 1 | 7.55% |
| Lexer.peek() | 0 | 0 | 0 | 1 | 1 | 3 | 1 | 5.66% |
| Monomial.getExpInner() | 0 | 0 | 0 | 1 | 1 | 3 | 1 | 1.15% |
| Monomial.getHashCache() | 0 | 0 | 0 | 1 | 1 | 3 | 1 | 1.15% |
| Monomial.hashCode() | 0 | 0 | 0 | 1 | 1 | 4 | 1 | 1.53% |
| Monomial.multiply(Monomial) | 0 | 0 | 0 | 1 | 1 | 6 | 1 | 2.30% |
| Monomial.optimizeExp(Element) | 0 | 0 | 0 | 1 | 1 | 3 | 1 | 1.15% |
| Number.Number(BigInteger) | 0 | 0 | 0 | 1 | 1 | 3 | 1 | 30.00% |
| Number.toElement(Element) | 0 | 0 | 0 | 1 | 1 | 4 | 1 | 40.00% |
| Parser.Parser(String) | 0 | 0 | 0 | 1 | 1 | 3 | 1 | 1.74% |
| Parser.grad() | 0 | 0 | 0 | 1 | 1 | 14 | 1 | 8.14% |
| Parser.innerExpr() | 0 | 0 | 0 | 1 | 1 | 7 | 1 | 4.07% |
| Parser.select() | 0 | 0 | 0 | 1 | 1 | 14 | 1 | 8.14% |
| RecFunc.RecFunc(int, Node) | 0 | 0 | 0 | 1 | 1 | 4 | 1 | 30.77% |
| RecFunc.toElement(Element) | 0 | 0 | 0 | 1 | 1 | 5 | 1 | 38.46% |
| Select.Select(Node, Node, Node, Node) | 0 | 0 | 0 | 1 | 1 | 6 | 1 | 26.09% |
| Solver.Solver(String) | 0 | 0 | 0 | 1 | 1 | 5 | 1 | 31.25% |
| Solver.getOutput() | 0 | 0 | 0 | 1 | 1 | 3 | 1 | 18.75% |
| Solver.solve() | 0 | 0 | 0 | 1 | 1 | 3 | 1 | 18.75% |
| TermNode.TermNode(int) | 0 | 0 | 0 | 1 | 1 | 4 | 1 | 18.18% |
| TermNode.addFactor(Node) | 0 | 0 | 0 | 1 | 1 | 3 | 1 | 13.64% |
| Variable.Variable(String, BigInteger) | 0 | 0 | 0 | 1 | 1 | 4 | 1 | 18.18% |
| Element.Element(BigInteger) | 0 | 1 | 1 | 1 | 2 | 7 | 2 | 2.75% |
| Element.Element(Monomial, BigInteger) | 0 | 1 | 1 | 1 | 2 | 6 | 2 | 2.35% |
| Element.divideBy(BigInteger) | 0 | 1 | 1 | 1 | 2 | 7 | 2 | 2.75% |
| Element.hashCode() | 0 | 1 | 1 | 1 | 2 | 8 | 2 | 3.14% |
| ExprNode.toElement(Element) | 0 | 1 | 1 | 1 | 2 | 8 | 2 | 47.06% |
| FunctionRegistry.parseRecurrenceRelation... | 0 | 2 | 1 | 1 | 2 | 21 | 2 | 19.09% |
| Main.normalizeSigns(String) | 0 | 1 | 1 | 1 | 2 | 12 | 2 | 34.29% |
| Monomial.Monomial(BigInteger, ...) | 0 | 2 | 1 | 1 | 1 | 12 | 2 | 4.60% |
| Monomial.wrapExp(Element) | 0 | 2 | 1 | 2 | 2 | 7 | 2 | 2.68% |
| Parser.parseTerm(int) | 0 | 1 | 1 | 1 | 2 | 9 | 2 | 5.23% |
| Select.toElement(Element) | 0 | 2 | 1 | 2 | 2 | 11 | 2 | 47.83% |
| Element.getGlobalGcd() | 1 | 3 | 3 | 3 | 2 | 10 | 3 | 3.92% |
| Element.negate() | 0 | 2 | 2 | 2 | 2 | 10 | 3 | 3.92% |
| Exp.toElement(Element) | 0 | 2 | 2 | 3 | 1 | 14 | 3 | 63.64% |
| Main.main(String[]) | 0 | 2 | 2 | 1 | 3 | 21 | 3 | 60.00% |
| Monomial.isEmptyMonomial() | 0 | 1 | 0 | 1 | 3 | 4 | 3 | 1.53% |
| Parser.dealVariable(String) | 0 | 3 | 2 | 2 | 3 | 13 | 3 | 7.56% |
| Parser.exp() | 0 | 3 | 2 | 2 | 3 | 16 | 3 | 9.30% |
| Parser.exprFactor() | 0 | 3 | 2 | 2 | 3 | 15 | 3 | 8.72% |
| TermNode.toElement(Element) | 0 | 2 | 2 | 1 | 3 | 11 | 3 | 50.00% |
| Element.derive(String) | 0 | 4 | 3 | 2 | 3 | 16 | 4 | 6.27% |
| Element.formatTerm(BigInteger, Monomial) | 0 | 3 | 3 | 4 | 2 | 13 | 4 | 5.10% |
| Element.getTotalComplexity() | 0 | 6 | 3 | 4 | 3 | 12 | 4 | 4.71% |
| FunctionRegistry.processRecursiveLine... | 0 | 3 | 3 | 1 | 4 | 13 | 4 | 11.82% |
| Variable.toElement(Element) | 0 | 3 | 3 | 4 | 2 | 14 | 4 | 63.64% |
| Element.add(Element) | 0 | 6 | 4 | 3 | 3 | 21 | 5 | 8.24% |
| Element.equals(Object) | 0 | 4 | 3 | 4 | 2 | 14 | 5 | 5.49% |
| Element.hasHugeCoefficient() | 0 | 8 | 4 | 5 | 3 | 13 | 5 | 5.10% |
| Element.isSingleFactor() | 0 | 4 | 3 | 4 | 2 | 15 | 5 | 5.88% |
| FunctionRegistry.findParen(String, int) | 0 | 6 | 4 | 3 | 3 | 15 | 5 | 13.64% |
| Monomial.getBestGlobalExp(Element) | 0 | 10 | 4 | 1 | 5 | 20 | 5 | 7.66% |
| Element.multiply(Element) | 0 | 9 | 4 | 2 | 5 | 24 | 6 | 9.41% |
| FunctionRegistry.evaluateRecursiveFunc... | 0 | 9 | 4 | 2 | 6 | 26 | 6 | 23.64% |
| Monomial.derive(String) | 0 | 5 | 3 | 1 | 6 | 19 | 6 | 7.28% |
| Monomial.optimizeExpInner(Element, int) | 0 | 6 | 4 | 5 | 5 | 16 | 6 | 6.13% |
| Element.power(BigInteger) | 0 | 8 | 6 | 4 | 4 | 24 | 7 | 9.41% |
| Monomial.equals(Object) | 0 | 5 | 3 | 4 | 4 | 15 | 7 | 5.75% |
| Parser.parseExpr() | 0 | 7 | 4 | 1 | 5 | 20 | 7 | 11.63% |
| Monomial.tryLocalSplit(Element, int) | 0 | 14 | 6 | 2 | 7 | 29 | 8 | 11.11% |
| Element.output() | 2 | 12 | 9 | 6 | 7 | 28 | 10 | 10.98% |
| Monomial.output() | 0 | 12 | 9 | 2 | 9 | 30 | 10 | 11.49% |
| Lexer.nextToken() | 0 | 17 | 9 | 2 | 10 | 41 | 12 | 77.36% |
| Monomial.isSingleFactor() | 0 | 13 | 10 | 8 | 3 | 35 | 13 | 13.41% |
| Monomial.getCandidateGcds(List) | 3 | 23 | 16 | 7 | 13 | 48 | 17 | 18.39% |
| Parser.parseFactor() | 0 | 15 | 16 | 11 | 15 | 58 | 17 | 33.72% |
| Total | 6 | 248 | 168 | 165 | 218 | 995 | 274 | - |
| Average | 0.07 | 2.82 | 1.91 | 1.88 | 2.48 | 11.31 | 3.11 | 7.63% |
总体而言,这里的问题其实和上文的分析差不多,基础节点健康,而核心枢纽过载。大部分叶子节点和基础操作复杂度很低,但解析(Parser)和复杂化简(Monomial)的个别方法已经极其危险了。我们观察下面三个危险的方法:
(1)Parser.parseFactor(): v(G)=17(分支极多),ev(G)=11(严重缺乏结构化),iv(G)=15(极度耦合),LOC=58(全场最长)。这里面包含了一个巨大的 switch case 来判断当前 Token 是变量、数字、括号还是函数。ev(G) 高达 11 是因为里面全是提前 return这种破坏单入单出原则的代码,非常容易在处理嵌套表达式时发生遗漏或越界 Bug,实际上这块维护起来也是特别该死,为了解决checkstyle我还把一些逻辑移了出去,但仍旧很糟糕,至于他的耦合性似乎没有很好的解决思路。
(2)Monomial.getCandidateGcds(List):他的 CogC=23,是全场最高的认知复杂度,v(G)=17,LOC=48也不好。CogC高 是因为这个方法里写了 for 循环套 for 循环,里面再套着 if-else。还是那句话,为了优化我什么都可以做的。
(3)Monomial.isSingleFactor() :LOC = 35,v(G) = 13 ,CogC = 13 ,ev(G) = 8 。它里面堆积了大量的业务推算和条件判断逻辑,且充斥着非结构化的逻辑为了判断一个单项式是否为单一因子,我使用了大量的 if-else if 分支,并在其中穿插了各种提前 return true 或 return false。这种多出口、深嵌套的代码,导致逻辑流极其跳跃。我为了判断是不是单因子,得去判断系数是不是 1 或者 -1;判断变量是不是只有一个,且指数是不是 1;判断exp有没有挂载内部表达式,判断条件组合过多,导致了你的 v(G) 和 CogC 双双飙升到 13。应该拆出几个分别判断的小函数,由isSingleFactor做整合比较好。
总体分析:我的整体架构基本遵循了“词法分析 -> 语法解析 -> AST构建 -> 多项式计算”的流水线模式。总体而言,系统的耦合与内聚呈现出两极分化状态。
(1)类的内聚情况分析 :
AST 节点类高内聚做的比较好: 像 Number、Variable、DxNode、DyNode 等叶子节点类表现出了极高的内聚性。它们通常只有 1-2 个属性,只负责存储具体的数值或变量名,且方法紧紧围绕自身数据的获取和转化为底层计算模型(toElement)展开,完美符合单一职责原则。
但计算核心类是低内聚的重灾区: Element 和 Monomial 作为多项式计算的底层容器,出现了明显的低内聚现象。它们不仅负责存储系数和指数,还包揽了加减乘除运算、求导逻辑、最大公约数提取(GCD)、甚至格式化输出(output)等多种职责。方法之间并未共享所有的成员变量,导致类内部功能变得庞杂。
(2) 类的耦合情况分析 :
良好的解耦设计: Lexer 和 Parser 之间实现了较好的解耦。Lexer 只负责无脑向后读取字符并生成 Token,而 Parser 只需要调用 lexer.peek() 和 lexer.nextToken(),不需要关心底层的字符串解析细节。
严重的紧耦合隐患: 整个系统对 Element 和 Monomial 产生了极其严重的依赖(高耦合)。所有的 AST 节点(ExprNode, TermNode, Func 等)最终都需要通过 toElement() 方法转化为 Element 对象进行数学运算;同时,Parser 在解析过程中也频繁介入了计算逻辑的调用。一旦底层数学运算的规则(如引入新的化简规则)发生改变,上层几乎所有的节点类都可能受到波及。
二、架构设计演变:
在最后的L3中,我将系统中的类大致划分为四个核心模块。以下是每个模块及其内部类的具体设计考虑:
(1)解析模块:
Lexer: 词法状态机。设计初衷是隔离底层的字符串操作,将输入的原始表达式字符串切分成一个个具有独立语义的词法单元(Token),供 Parser 消费。Parser: 语法解析枢纽。采用递归下降算法,将 Lexer 传来的 Token 流组装成抽象语法树。其设计核心在于准确翻译表达式的文法规则。
(2)抽象语法树节点模块 :
该模块采用了组合模式),所有的节点类都向上提供了一个统一的计算接口(toElement)。ExprNode & TermNode 作为树的非叶子节点,负责管理其下的子节点集合。设计考虑在于体现加减运算(Expr)和乘法运算(Term)的层次差异。Factor类型的扩展节点比较多:ExprFactor 处理括号嵌套问题,它是打破普通单项式规则、引入递归解析的关键设计;Number 和 Variable 是最基础的叶子节点,仅负责包裹 BigInteger 类型的数值或字符串变量名;DxNode / DyNode 将求导操作也抽象为一种特殊的树节点,使得求导动作可以像普通因子一样参与语法树的构建,随后在计算阶段再触发实际的求导逻辑;Func / RecFunc 用于占位和计算自定义的函数调用,设计时考虑了将函数名与实际传入的实参列表进行绑定。
(3)数学计算模块:
该模块脱离了 AST 的树形结构,专注于多项式的数学运算与合并同类项。Element: 系统中最核心的“多项式”实体类。设计考虑是作为所有 AST 节点计算后的最终归宿。它内部通常维护一个项的集合,负责统筹加减法以及整体的求导调度。Monomial: 具体的“单项式”实体类。它细化了数学运算,负责存储系数、以及各个变量的指数。乘法、提取公因式等复杂的代数运算逻辑主要集中于此。
(4)状态与环境管理模块:
FunctionRegistry:设计为一个全局可访问的上下文环境,负责在解析预处理阶段存储自定义函数和递归函数的定义(形参和函数体),并在 Parser 解析到具体的函数调用时,提供实参替换和函数体实例化的支持。
我放出在三次作业中我的项目大观:
L1:
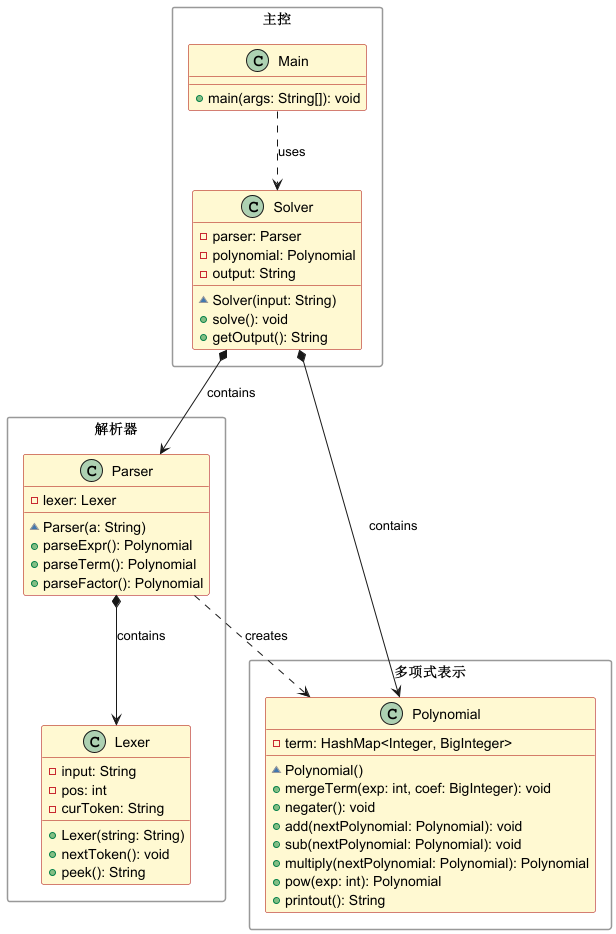
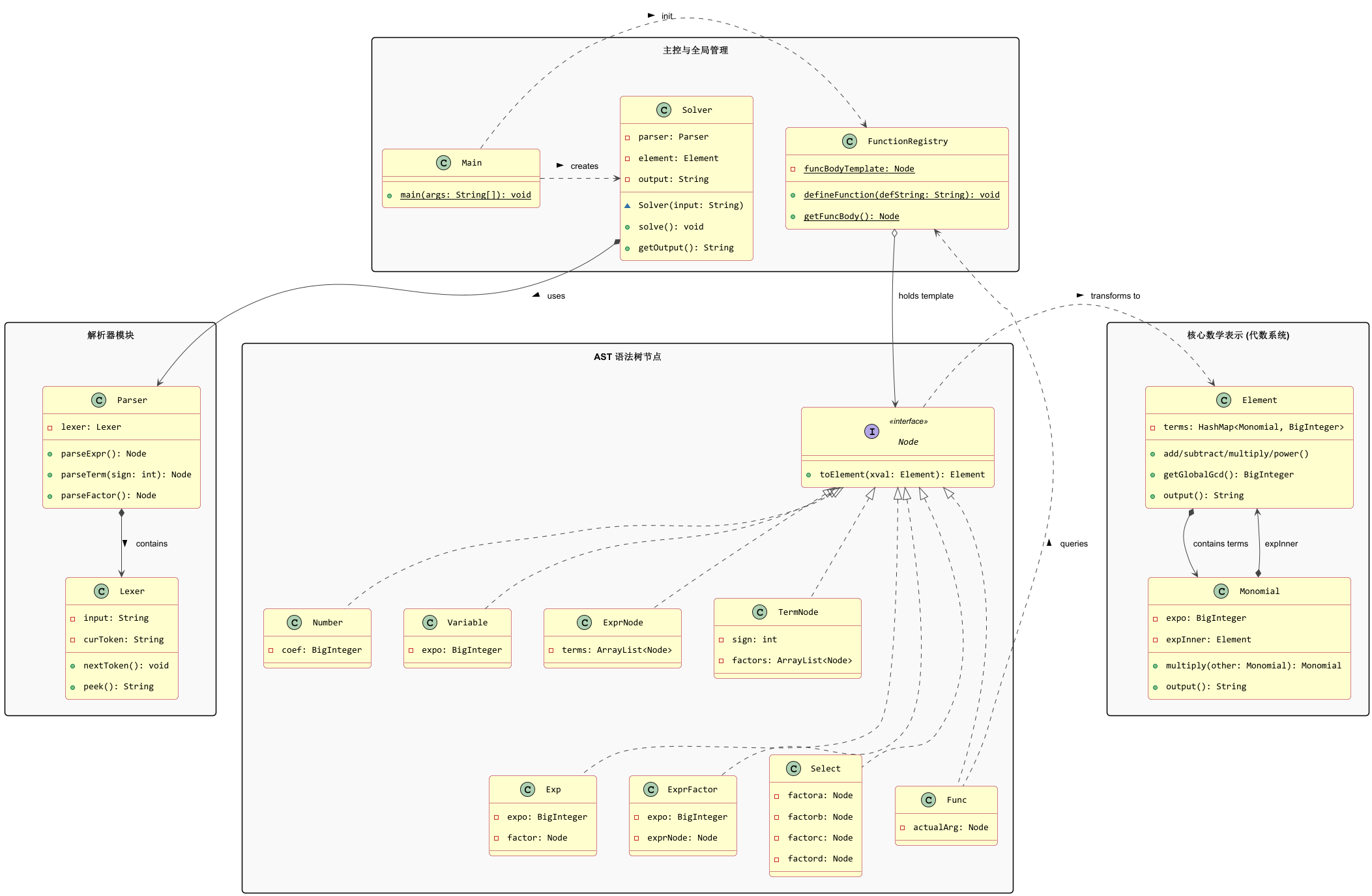
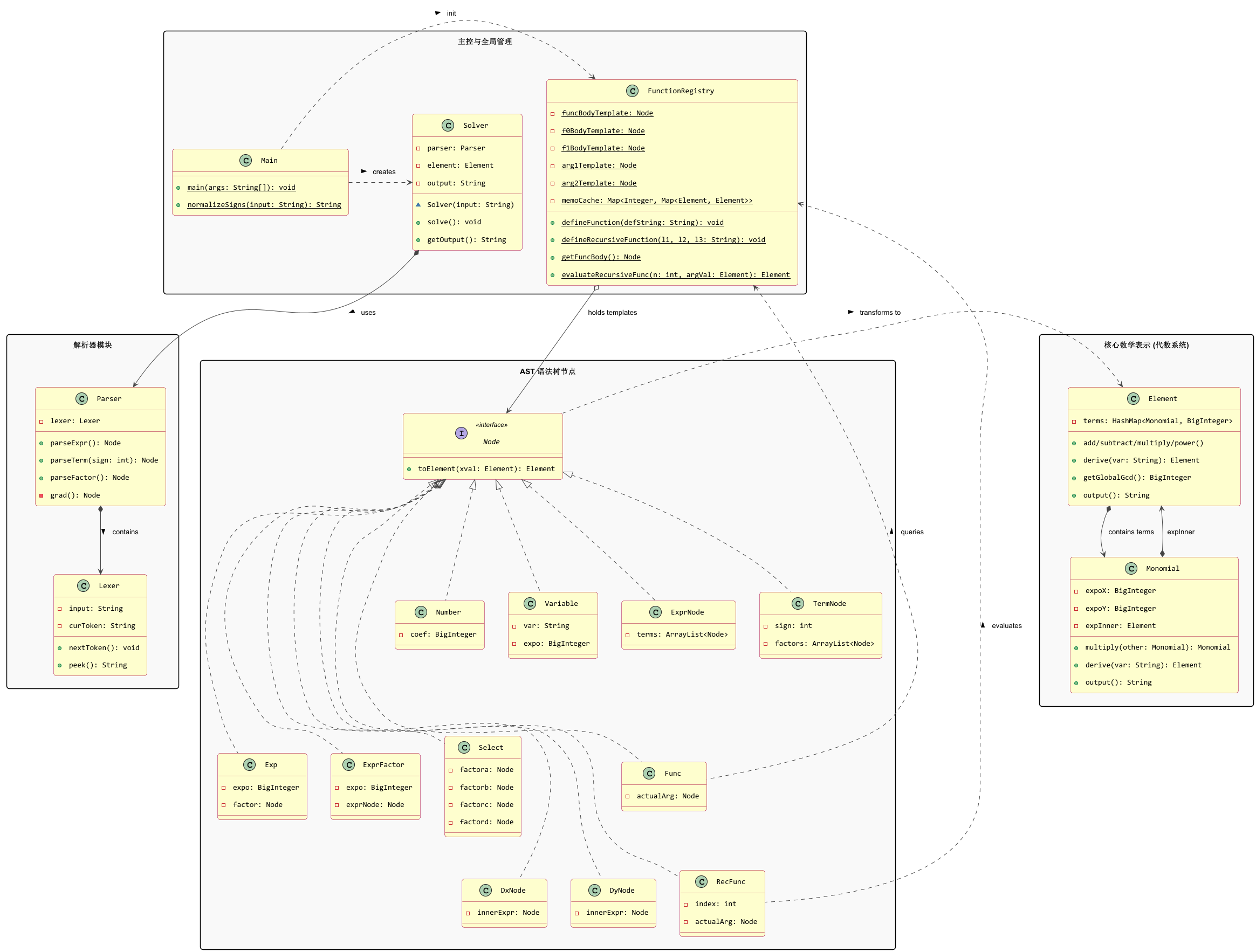
可以看到L2到L3变化是比较小的,无非是多了几个类;但L1到L2却是发生了巨大的重构。这是因为在L1时任务比较简单,底层factor衔接的类数目较少,当时就是边解析边计算,直接在 parser 的 switch 里面就算了,完全没有抽象语法树的事情。这当然不是啥很好的代码风格,但在L1的时候也够用了。但到了L2,底层 factor 种类的急剧膨胀和函数代入的需求使得老方法玩不转了,于是我拆分了形式语义的语法树部分和实际计算的计算部分,通过 toElement 接口将所有的语法树转化为实际运算数据。这套法子还是很稳固的,L3新增的求导没有给我造成多大的麻烦,面对一些新场景,比如说加入三角函数什么的,事情也没多麻烦,按照以下顺序修改即可:修改Lexer,新增入对token的解析——>在parser中找个位置加入parserCos(估计是parserFactor中)——>新增cos类,写toElement方法——>进入Monomial类编写他的求导运算行为——>修改isSingleFactor的判定------>可能会有的优化?基本就是这样。
三、优化思路:
这个事情得分成两部分来看待。一方面人为财死,鸟为食亡——要想不出bug,最好的办法就是不优化,我在第三次互测7人房里砍了4个人,幸存的两个人基本没做任何优化,有一个连gcd都没有,我总不能攻击他的Hashmap吧?但另一方面,今年计分的改革使得被hack不扣分,为了追求强测更高分,冒着制造bug的风险进入互测,分析一下其实也不亏,只能说见仁见智吧。
我本人是走的第二条道路,我不是啥OO享受者,也不追求更高更快更强,只是我确实觉得这个事情可以做,至少AI可以做。我有一个类似于聚类的想法,如果有gcd,那么当然是好的,只要在[max_gcd/10,max_gcd]找就好;麻烦的是如果gcd为1的情况,这就不得不涉及拆分exp内的多项式,我是这么做的:
(1)寻找候选 GCD:它先扫描一遍内部的所有项,找出绝对值最大的 3 个系数,然后拿这 3 个基准点去和内部其他所有项的系数求 GCD。只要 GCD > 4,就被认为是一个有价值的“候选拆分因子”。
(2)执行拆分:遍历每一个 candidateGcd,把内部多项式硬生生劈成两半,能被其整除的和不能被其整除的。
(3)递归与组合:将拆出来的两部分组合成乘法,判断是否节省长度
(4)深度限制与剪枝:depth<2,单项最多允许500个系数,复杂度大概是O(n)~O(n^3)
启发式本身就是玄学,我的优化部分很多vibe-coding的成分,也难以说得上多么严谨,我自己在测试部分也在评测机中看到了诸如TLE的问题,但也懒得解决它,不过我两次强测99,说明选择至少没错。
四、互测部分我和别人的bug:
我觉得这世界是个摆烂的世界。
我在周五研讨课的时候听了刘睿知同学的分享,这更进一步地强化了我对于世界的刻板印象。如果所有人都有刘同学一半的认真,那这个世界会变得好上很多,也会残酷很多。我的互测分组运气不错,代码被hack的不多,实际上我自己都能发现他的很多问题,毕竟ai+玄学优化+牙疼会产生巨多的问题。最大的问题就是L2我忘记了拆分exp会可能导致它从因子变成表达式,如果外层还有exp,会出现语法错误,发现这个bug本身并不需要什么技巧,也不用搞很大的数据,但他就是在我眼皮子底下呆了近乎一周而没有被发现,只能说水平还是不太够。
至于别人的bug,那更是很寂寥了。我本人不是啥互测享受者,也没有什么使命感敦促我一定要把他们叉掉。很多时候,我制造了一个很极端的数据,把他们黑掉了,这不能说明我有多么高明或者他们有多么大的问题,我们组有个写状压DP的,复杂度O(3^n),他限制了n<=12,但我还是把他黑掉了,这能说明什么问题吗?可能他在bug修复阶段,把n<=12改成n<=11就过了,这甚至说不上是个问题,只是一个性能和正确性的权衡罢了。我所观察到大多数人,包括我,都是很松弛的,我们的代码、测试、自我检查和对别人的攻讦,都有一种不严谨的气息,可能这确实是个摆烂的世界吧。
五、大模型的使用:
我用大模型用的不少,无论是课内还是科研。我主要是优化部分用它写,然后自己改剪枝,这个笨蛋搞不明白我对时间判断的提示词,不过不得不说他的启发式还是很有一手的,至少很有想象力,虽然也有很多bug。至于基础的架构设计和实现,我跟他讨论。这部分是不能让他写的,底子没打好后续什么扩展都做不了,更遑论正确性了。我主要是用它帮助我理解题干,一开始的形式语义对一个离散不好的人实在不友好;然后询问他一些关于函数替换的思路问题;以及发挥AI作为一个参谋的作用,去询问它两种不同的路径(如预处理正则表达式替换和语法树节点替换)各自的优缺点;最后是做一些性能上和时间复杂度上的分析。我个人觉得AI作为参谋而言是合格的,但不要让他替你做决定,不论为什么,有些错误是要自己犯下的。
六、心得体会:
我大概确实不是个OO享受者,实在是不能从这门课中获得纯粹代码的喜悦和叉人至高的快乐,可能我不太适合当一个软件程序的开发者或者一个hack别人的黑客。甚至这门课给我最大的收获都不一定是在代码本身,而更多的在于一种思路,直觉和一些工程能力。我觉得架构本身是可以讲的,我们可以去讲诸如工厂模式的一些既有范式,但本质上来说,没有任何人可以告诉我,面对某个特定场景我要选取什么样的架构。说的再具体一点,有什么架构和我要选择哪个架构本质上是两个差了很大的问题,有什么架构可以通过知识的积累,但选哪一个,这更多的依赖于实践的锤炼。
可能干的久了,自然而然的就能发现有些idea看起来很好,实践起来就会出很多问题;可能做到第一部分,就已经能预见到后续业务的需要,可以做针对性的准备和调整了。而这些都需要丰沛的实践来培养一种感知和洞见,我经验不多,就不乱说了。
七、未来方向:
第一单元跟编译原理联系很紧密,说不定可以给大家分发一些编译相关的处理语法树的延展性资料,来供大家过渡?L1从无到有还是有一定门槛的,我当时确实忘记了递归下降怎么处理了,或许可以通过一些资料降低一点?

