



307
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享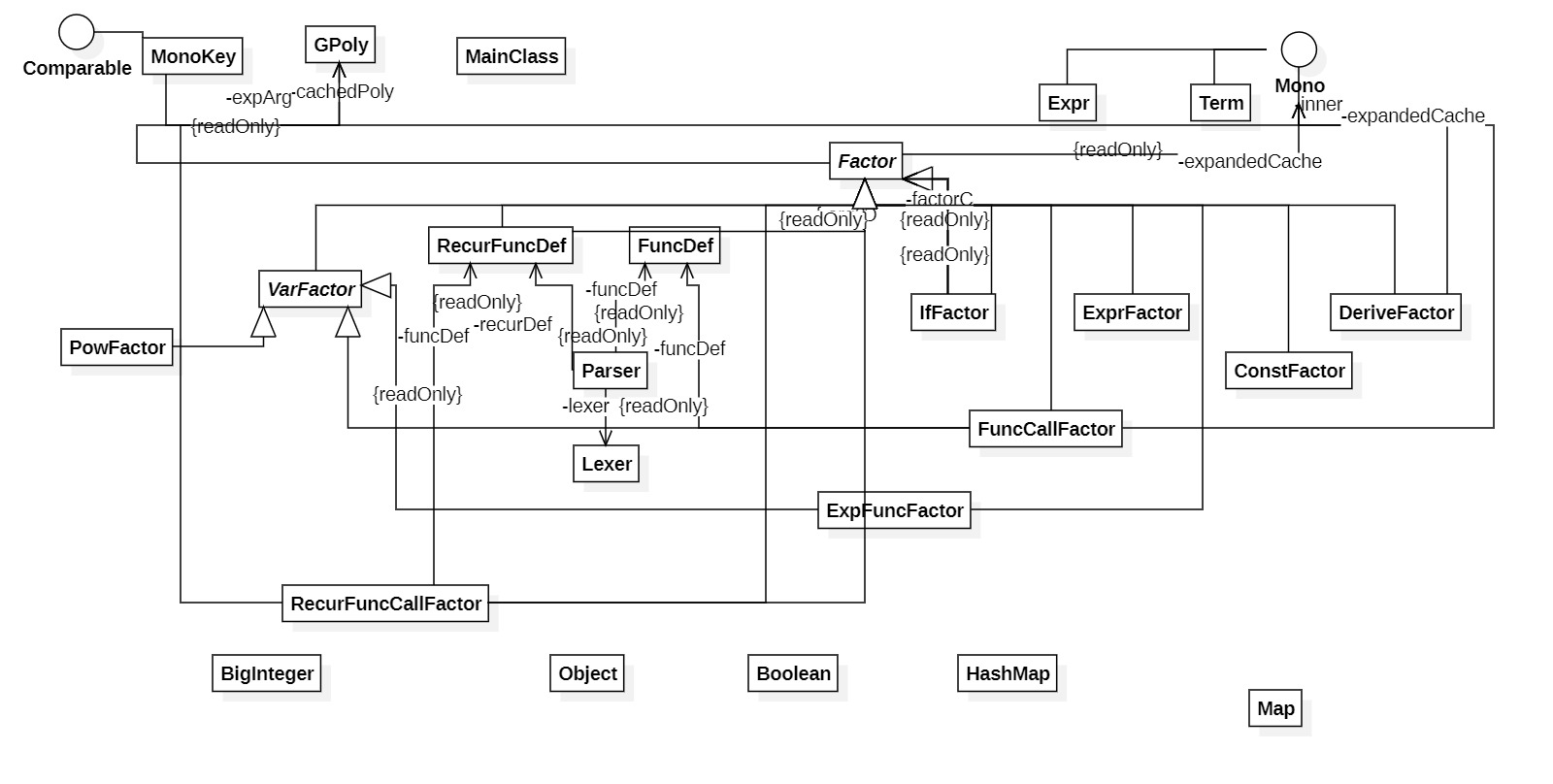
我的代码由输入解析、数据存储和语法树建立三个模块组成。
输入解析:这部分主要由Lexer和Parser完成。Lexer负责读入token,Parser负责通过递归下降将token流转化语法树,处理自定义非递归函数、递归函数和待解析表达式。
数据存储与计算:为统一储存,我设计了广义多项式GPoly类和单项式Mono类,通过Monokey在HashMap中进行管理。
语法树构建:这部分是解析逻辑的核心。设计上,我采用了和指导书相同的表达式、项、因子三层结构,又通过继承关系将Factor细分为ConstFactor、VarFactor、IfFactor等,并根据迭代要求进一步细分。

| 类名 | 属性数 (NOF) | 方法数 (NOM) | 代码规模 (LOC) | 加权复杂度 (WMC) |
|---|---|---|---|---|
| GPoly | 4 | 19 | 219 | 72 |
| Parser | 3 | 19 | 219 | 50 |
| MonoKey | 4 | 8 | 88 | 28 |
| Lexer | 3 | 5 | 55 | 18 |
| PowFactor | 2 | 4 | 39 | 11 |
| Term | 3 | 4 | 46 | 11 |
| ExprFactor | 2 | 5 | 34 | 10 |
| Expr | 2 | 5 | 31 | 8 |
| ExpFuncFactor | 2 | 4 | 28 | 7 |
| RecurFuncDef | 9 | 3 | 50 | 7 |
| RecurFuncCallFactor | 4 | 5 | 27 | 6 |
| IfFactor | 4 | 5 | 27 | 6 |
| FuncCallFactor | 3 | 5 | 25 | 6 |
| MainClass | 0 | 1 | 27 | 4 |
| ConstFactor | 1 | 4 | 15 | 4 |
| DeriveFactor | 2 | 4 | 18 | 4 |
| Factor | 1 | 2 | 10 | 3 |
| FuncDef | 1 | 2 | 9 | 2 |
| VarFactor | 0 | 0 | 2 | 0 |
| 所属类 | 方法名 | 规模 | 分支数 |
|---|---|---|---|
| GPoly | addStr | 55 | 22 |
| Parser | parseFactor | 24 | 10 |
| Lexer | next | 29 | 10 |
| GPoly | isSingleFactor | 13 | 10 |
| MonoKey | compareTo | 27 | 9 |
| MonoKey | equals | 19 | 8 |
| GPoly | toString | 30 | 8 |
| Parser | parseExpr | 23 | 6 |
| Term | derive | 20 | 5 |
| MonoKey | mult | 17 | 5 |
| PowFactor | substitute | 13 | 4 |
| PowFactor | derive | 10 | 4 |
| ExprFactor | derive | 13 | 4 |
| Term | toPoly | 13 | 4 |
| Parser | parseTerm | 17 | 4 |
理想情况是"高内聚,低耦合",即一个类只做好一件事,类与类间依赖度低。
| 类名 | 内聚度 (LCOM) | 耦合度 (CBO) |
|---|---|---|
| RecurFuncCallFactor | 4 | 6 |
| PowFactor | 0 | 9 |
| ExprFactor | 0 | 7 |
| IfFactor | 8 | 4 |
| Term | 0 | 6 |
| Parser | 15 | 16 |
| Lexer | 0 | 1 |
| MainClass | 0 | 6 |
| ExpFuncFactor | 0 | 8 |
| Expr | 0 | 5 |
| FuncDef | 0 | 1 |
| Factor | 1 | 3 |
| MonoKey | 0 | 2 |
| RecurFuncDef | 0 | 7 |
| VarFactor | 0 | 1 |
| FuncCallFactor | 4 | 7 |
| GPoly | 0 | 2 |
| ConstFactor | 4 | 4 |
| DeriveFactor | 0 | 3 |
以上是利用ck导出的分析表格,列出了每个类的内聚度与耦合度。从表格中可以看出,对于大部分类较为健康。ConstFactor等基础类的 CBO 多在4一下,说明它们不怎么依赖外部复杂的逻辑。这种低耦合的设计使得基础运算单元非常稳定,修改其他类几乎不会波及到它。同时由于采用了 Factor 接口,所有的子类如 ExpFuncFactor 和 PowerFactor 的 CBO 都维持在 8 左右,没有出现某个因子依赖过重的情况。这证明了接口隔离和多态机制有效地平衡了系统的耦合压力。
但与此同时,我们也可以看到高 LCOM + 高 CBO的类,如Parser。分析可得,Parser的职责为递归下降解析输入,并将具体的处理任务分配至相应的类,方法之间共享属性较少且与许多类都有互动,在递归下降场景下很难避免。
此外,我们还发现IfFactor 的 LCOM 达到 8,明显高于其他因子。分析发现,这可能是由于内部受限于父类接口定义存在空方法且为提高代码复用性进行了choose()方法分离带来的字段非直接访问。
这一单元整体架构迭代的还是比较顺利的,只在第一次作业之后进行过一次重构。
第一次作业架构设计时,由于Factor类别较少,我并没有显式建立语法树,而是只有MainClass, Lexer, Parser和Poly四个类,边解析边计算。这样的好处是类数量少,架构简单,处理简单情况已经足够了。但第二次作业在第一次基础上增加了指数函数因子、选择式因子和自定义函数,若还是边解析边计算则Parser类会非常复杂。加上考虑到之后第三次迭代可能还会增加因子种类,最终决定建立显式的表达式树,将Expr, Term和Factor拆出来。可能因为重构的比较早,且只是将隐式的表达式树显式呈现出来,重构难度不算大。
我的迭代思路其实比较简单,基本上就是完全依照指导书更新架构,新增因子于函数并添加对应的输入处理部分。这一单元课上和指导书已经给出了很明显的表达式树的架构提示,我个人认为其中需要我们补全的多在于细节实现,架构上留的空间到不太多。实践下来,大概有两点收获:
若还要迭代的话,或许可以尝试引入三角函数因子? 那就需要在Poly中增加三角函数,给 MonoKey增加属性sin,并在Factor接口下新建 SinFactor 和 CosFactor 类。整体思路还是沿用先前的,就是化简部分应该得多费一些功夫。
这一单元我的bug只在互测部分被发现,一共有两个bug,分别是哈希冲突没有处理好和输入解析部分常数未解析符号。
第一个bug是无意义优化的副产物,也是和AI互动且未仔细研代码的结果。我为实现输出是系数降序排列需要对项之间进行比较,而在特判哈希冲突是选择了简单直接的返回1。这导致最终容器HashMap中的存储顺序与我记录指数序列的ArrayList顺序不一致,最终出错。分析原因,一是由于理解不深对哈希冲突没有加以重视;二是面对逻辑复杂的compare()方法设计测试样例时未涵盖所有分支,考虑不全面;三是我自己完成代码初稿后交由AI检查,面对AI返还的修改后的代码凭借对AI的奇妙信任拿来即用,非常不可取。
第二个bug就比较低级了,完全是审题不当,或是代码写到后面脑子不怎么转了吧。更值得思考的是为什么自己设计测试样例时为什么没有涵盖这一点?可能是当局者迷吧。
这一段单元我在hack上没取得大的成绩,第一次作业hack0次,第二次作业hack1次,第三次作业是4次。策略的话,有,但受限于个人能力不一定次次有效。
这一单元涉及的优化有三个方向,分别为省略首项前的符号,提公因数以及进一步的多项式拆分。在分析实现难度后,我在代码中只实现了前两种。
符号省略:省略首项前的符号思路较为简单,只需寻找第一个正项,若有则提到最前。遍历一次O(n)的复杂度还是可以接受的。
公因数提取:提公因数的优化可以说的就多了。我个人是只针对exp项考虑了提最大公因数与不提两种情况,分别写出最后的输出后比较字符串长短,选其中较短的作为最终答案。但研讨课上同学分析出最优解不一定在上述两种情况里,提较大的公因数一些情况下比最大公因数性能更优,并证明只需讨论gcd/1 - gcd/9即可找到最优解。
可以看出,我的优化整体来说较简单,并未引入过多内容。最后整体效果上虽然性能没有那么优秀,但也没有因为优化引入额外的bug。
写这一单元作业过程中,我应该算是大模型深度使用者。虽然除cache优化的部分外每一行代码最初都由我亲手敲下,但不可否认,从前期的架构设计到中期写代码,再到后期debug和评测机搭建,每一步都有大模型的参与。
和大模型交互我的体验是:大模型能力真的很强,至少在某些方面比现在的我厉害很多,但若要将它的能力发挥出来,还需要我们的引导与纠正。以前期架构设计为例,HW1中我让大模型以递归下降的思路给出样例表达式解析的详细过程,帮助我理解递归下降的概念。在三次作业中,我也会就自己设计的粗糙架构与大模型讨论,请它纠错与优化,并讨论实现中可以采用哪些设计模式与数据结构。可能是递归下降相关的语料较充足,这一部分大模型完成的挺不错的。
之后就是写代码,这一部分最需要克制AI使用冲动。在一番拉锯之后,我找到的平衡点是正确性部分不论质量高低我先写一版,之后交由AI检查与优化,我再学习AI给出的答案,找合理的地方修正到我的代码里。而优化部分AI使用占比则明显变多,基本上除了第一次作业的排序还有古法的痕迹,后面的$gcd$提取逻辑等优化大模型占比显著增多,也因此在互测中带来了一些问题。
然后就是100%AI的评测机,我在其中起到的作用大多在提需求与对架构的建议,基本集中在使用层面。至于最重要的数据生成,我的办法是先由AI分析需要涵盖哪些情况的数据并生成,自己再分析一些易错的方向并让AI辅助构造。坦白来说,这样造出来的评测机在数据强度上并没有什么优势。AI很难在合法性、复杂度和cost组成的三角中找到一个平衡,反应在数据上就是重复单调且结构简单,整体质量并不高,而最终能hack到他人的数据还是以手搓出来的为主。
而对于找bug,我的体验是AI擅长对着答案反推过程,而不太能根据问题找答案。即给出数据点与错误输出,AI可以轻松帮你找出错因,但若一股脑把代码丢进去让AI找bug,往往效果不太好。
最后就是互测中看到的AI使用情况。第一二次作业互测房间中还没有看到明显的AI生成代码的现象。第三次作业中天枢星作业中有明显AI注释存在,大模型使用较明显 。
虽说只是OO的第一个单元,OO之旅才刚刚开始,但已经能感受到压力了。
这短短的一个月内,我拥有了许多个"第一次"。第一次搭建评测机(虽然是在大模型的辅助下),第一次hack到他人,第一次在作业完成后看其他同学的代码感受不同思路的碰撞……这一切的感受都可以说是新奇,但也伴随着挑战。
不可否认,大模型能力的提升在一定程度上降低了作业的难度,但也带来了新的问题。感谢有大模型的支持让我们可以更快地找到正确的方向,但同时思考与练习上的懒惰也会在一定程度上阻碍自身能力的成长。大模型触手可及的当下,如何平衡与AI的协作与自己的思考尝试?我还没有找到答案。
如何要修改第一单元的课程,或许可以加入对大模型使用的引导与建议,如设置一个环节强制要求与大模型以某种方式交互完成?

