


302
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享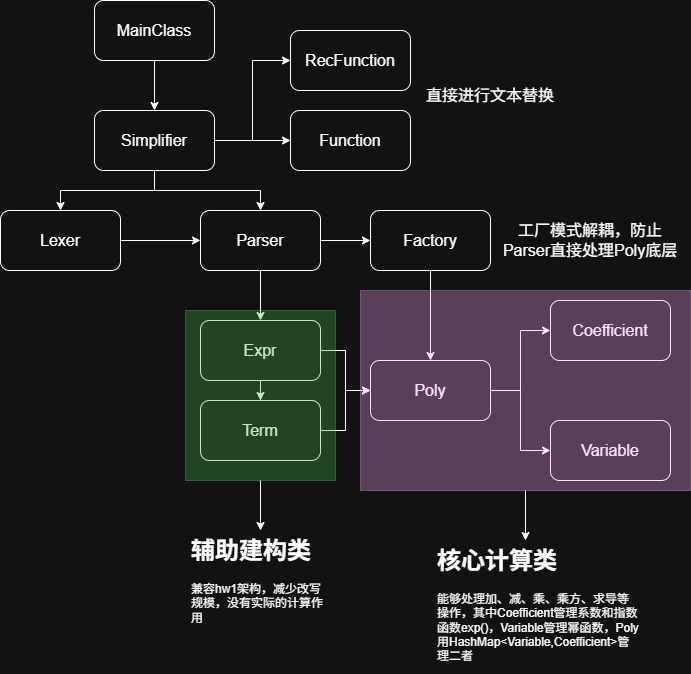
自我点评:
优点:
职责划分较为清晰,不会出现功能交叉,耦合度相对较低,各部分独立运行
核心计算类设计利好直接合并同类项,实现起来比较简单
缺点:
Function、RecFunction 直接进行文本替换,容易被嵌套复杂结构影响或者是卡住,此外没有抓住二者共性,代码重复度较高
计算类较为臃肿,扩展性较差
Mono 类实际只用来解构输出,可能将部分 Poly 权责下放 Mono 会更加优美
本次项目的宏观度量数据如下(以下数据部分为经过 Lizard 工具对项目全局扫描,使用 AI 工具整理形成):
| 类名 (Class) | 总规模 (NLOC) | 方法数 (Func Cnt) | 平均方法规模 (Avg.NLOC) | 平均圈复杂度 (Avg CCN) |
|---|---|---|---|---|
Poly | 263 | 19 | 13.0 | 3.4 |
Lexer | 220 | 15 | 13.9 | 5.3 |
Coefficient | 183 | 19 | 8.9 | 2.3 |
Variable | 143 | 16 | 8.2 | 2.0 |
Parser | 131 | 8 | 15.0 | 3.9 |
RecFunction | 68 | 5 | 11.8 | 3.0 |
Mono | 62 | 4 | 13.2 | 3.8 |
Simplifier | 52 | 5 | 8.4 | 2.4 |
MainClass | 48 | 1 | 43.0 | 6.0 |
Term | 37 | 5 | 6.2 | 1.8 |
Expr | 36 | 7 | 4.1 | 1.3 |
Function | 27 | 4 | 5.5 | 1.5 |
Factory | 23 | 3 | 5.0 | 1.0 |
| Total | 1293 | 111 | - | - |
| Avg | - | 8.53 | 10.5 | 2.9 |
分析:
整体而言,类的方法数控制在 5 ~ 15 个 的合理范围,平均方法规模在 5 ~ 15 行 内,平均圈复杂度在 1.0 ~ 3.0 内,说明整体内聚性和耦合度控制得比较合理
处于平均视角之外:Poly、Coefficient、Variable 、Lexer 承担了相当多的功能,以 Lizard 给出的指标:```
!!!! Warnings (cyclomatic_complexity > 15 or length > 1000 or nloc > 1000000 or parameter_count > 100) !!!!
说明这些类设计得相当臃肿,扩展性和可读性相对较差
控制分支:
!!!! Warnings (cyclomatic_complexity > 15 or length > 1000 or nloc > 1000000 or parameter_count > 100) !!!! ================================================ NLOC CCN token PARAM length location ------------------------------------------------ 40 22 293 1 40 Lexer::preOperation@42-81@./src\Lexer.java 51 19 334 0 52 Lexer::next@147-198@./src\Lexer.java ==========================================================================================
Lexer 由于控制分支过多,触发了警告,不过似乎这也是没办法的事情?或者我们可以将一些判断再细分出一些方法,这样可以增强可读性。如果需要进一步优化,应该再分析这些条件分支的共性,进一步抽象,可以减少圈复杂度
高内聚模块:Expr 和 Term 作为表达式树的节点,只负责维护自身的数据结构和基础的合并逻辑,方法极短(平均 4-6 行),职责极其单一,体现了极好的信息内聚。Simplifier 将化简逻辑独立出来,也体现了较高的功能内聚。
低内聚风险(上帝类):Lexer 类不仅负责了字符串的遍历 (next, skipIf),还负责了预处理 (preOperation) 和函数展开 (expandFunctions)。这违反了单一职责原则,导致该类既长又杂,内聚度下降。
不可避免的结构性耦合:Parser 强耦合于所有的语法树节点(Expr, Term, Factor 等),因为它需要实例化这些对象,这是递归下降解析器的固有特征。
良好的解耦尝试:我引入了 Factory来统一管理变量和因子的创建。这有效地将 Parser 和具体的底层数据类型进行了解耦,当需要增加新的变量类型时,只需修改工厂,符合开闭原则。
数据依赖耦合:Poly Coefficient, Variable之间由于存在大量的数学运算,它们的方法互相调用频繁,且互相作为参数传递。这种业务逻辑上的紧耦合是相对合理的,但是难以解开,扩展性差。
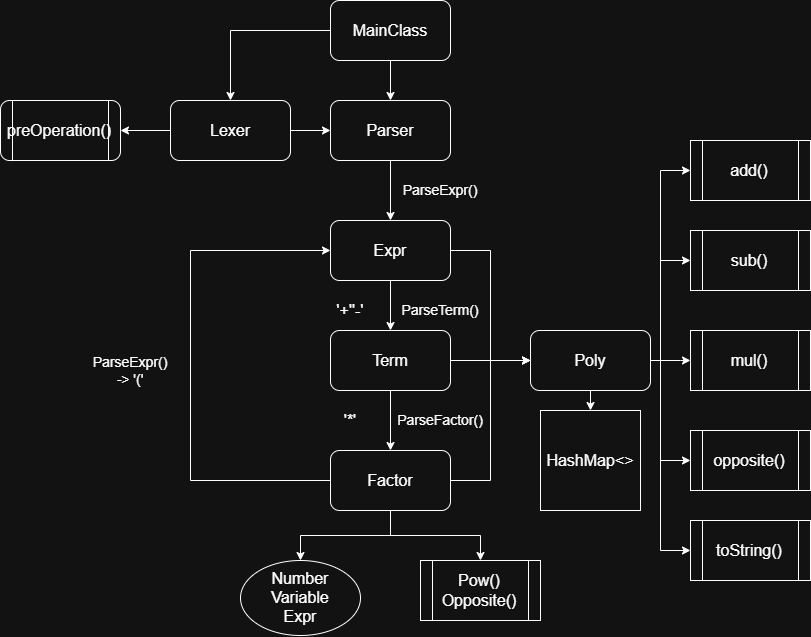
这是我第一次作业的架构,在第二次作业仅仅只是引入了新的元素,没有进行较大改动,但是在第三次作业,我将很多 Factor 类去掉了,原因在于即使我实现了它们,计算时仍然总是用 getPoly() 来工作,既然如此直接用 Poly 不就好了 ,因此,我的重构策略如下:
Parser 将诸多 Factor 直接解析为 Poly (通过工厂类),不再显式地创建因子类,减少无用结构
将预处理的部分实现转移到 Simplifier ,并把化简式子整体功能用 Simplifier 实现,既可以在运行过程中使用,也方便测试
扩展可行性分析:
不可拆函数:例如三角函数,可以类比 exp 封装到 Coefficient 里
新的自变量:例如 z ,我的 Variable 类使用 HashMap<String,BigInteger> 实现从变量名到指数的映射,因此添加不难
积分:只考虑单独的幂函数不难,如果配合指数函数貌似数学上有困难(?)
总体来说,由于使用了相应的保管类,加东西是可行的,但是 Key 值的复杂化可能会导致 HashMap 性能下降,导致超时
hw1: 空白项需要包含 '\t' ,x^0的特判处理
hw2: 没有跳过选择式因子中不需要解析的那个因子,导致TLE
hw3: 优化做错,导致多加了长度
出现这些问题往往是因为开发周期较长,以至于具体细节实现时忘记应该考虑的事情,容易顾此失彼。
此外,经过对比分析可以发现,有问题的方法圈复杂度较高,需要进行很多情况的考虑。
我认为后续的设计可以采用以下方式减小错误:
每次作业前先整体的列出架构,从正确性和性能两个方向考虑,最好形成文字
控制单个类的规模,并针对每个方法及时写测试,保证每个类内局部最优
尝试合并条件分支,简化逻辑
采取了评测机对拍 + AI分析 + 重点观察核心类的方法
评测机(开源链接)的数据来源于自己拍脑袋想出来的一些边界数据和随机脚本生成的数据,允许将互测房间内所有人的程序 zip 同时测试,根据自定义规则筛选出不同的答案,可以初步确定一些情况
AI分析环节主要是让 AI 快速总结项目架构,便于快速地掌握整体
重点观察环节则是根据个人理解,对于自己容易错或者认为对方架构可能哪里出错的地方进行重点观察,并针对具体原因设计样例
例如: 在 hw3 中,因为我自己是采取先把所有的 f 进行替换,然后再进行解析计算的策略,但是后来想到选择式因子不需要解析不符合的因子,而展开也需要时间,这个问题在hw2或许不太明显,因为 f 只有单层的,只需要注意解析时跳过即可,但是hw3可能会出现展开之后变得很长的因子,即使我们直接跳过不解析它,也会因为展开延误了时间。
而我在互测房间里发现和我一样做法的同学。
以下是我构造的样例:
1 f(x) = (2x^2+10x+779) ^4 0 [(1==1)?1:f(f(f(f(f(f(f(f(f(f(f(f(f(f(f(f(f(f(f(f(f(f(f(f(f(f(f(f((x+y)))))))))))))))))))))))))))))]
缓存: 由于主体采用 HashMap ,而构造 hash 需要一定时间,因此在复制时将 hash 值一并克隆,可以减少重复构造的开销。此外 toSting() 、递推函数也采用了缓存,加快速度
长度: 将正项提前,省略 1* / ^1 ,将 exp(0) 等同于 1,判断 exp 内是否需要加额外的括号
快速幂: 为了计算更迅速,采用快速幂
事实上,我的优化并不总能带来最好的结果:
快速幂在常数上比较好用,但是对于多项式来说大头反而是底数的自乘,例如底数本身是个 x+1 ,如果是依次乘入,只需要处理简单的系数,而如果使用快速幂,则乘入时的项将非常复杂,性能上可能更差
exp()的指数并不总要乘到括号里,有时候提出来反而会更简洁
经过交流,我有一些初步的想法:
例如,计算exp(inside)中 inside 的最大公因数,提取出来作为指数或许能得到更好的结果
| 正确性AI率 | 性能优化AI率 | |
|---|---|---|
| hw1 | 20% | 30% |
| hw2 | 30% | 50% |
| hw3 | 40% | 70% |
完成作业的过程中,正确性方面(也即完成主要内容)使用 AI 主要是进行代码补全(例如对方法名称的补全),提高效率;性能优化方面主要是用 AI 不断完善,添加一些修补性的优化代码
其他方面,在辅助找 bug、评测机搭建、博客作业等方面都使用过 AI 进行。
下面对大模型的效果总体评价一下:
上下文长度是最明显的瓶颈,长文本任务降智比较严重(如找bug,需要阅读整个项目进行理解)
对于局部性任务,或许相对而言比较好,但不一定与其他组件适配(例如它很难理解为什么解析选择式因子需要跳过其中一些部分)
对于博客作业,生成的文字味道比较重,很难说跟本人风格相像
发现别人使用大模型的痕迹:
注释十分详尽的,一看就是
变量名、方法名、类名比较长的(长到已经有多余的单词),有嫌疑
本单元的学习继承了先导课的知识,整体上能比较充分地考虑架构设计,实现课上课下结合,掌握了面向对象思想的部分内容,学会如何根据实际需求合理建类、分配方法和属性,形成一套完整的开发流程(整体设计——代码实现——功能测试)
希望未来的第一单元课程能够设置更多样化的元素,使课程内容更丰富
题目给出了准确的设定形式化表述,我们可以将其中所有的元素(包括空白项)进行建模,通过解析器解析来判断是否符合格式,例如
对于表达式 → 空白项 [加减 空白项] 项 空白项 | 表达式 加减 空白项 项 空白项
parseExpr():
hasHead = false
Expr expr = new Expr();
while(1):
if (lexer.end()):
return ture
if (!hasHead):
if isBlank(lexer.peek()):
expr.add(makeBlank())
lexer.next()
if isPlusOrSub(lexer.peek()):
expr.add(makePlusOrSub())
lexer.next()
if isBlank(lexer.peek()):
expr.add(makeBlank())
lexer.next()
else:
if isPlusOrSub(lexer.peek()):
expr.add(makePlusOrSub())
lexer.next()
else:
return false
if isBlank(lexer.peek()):
expr.add(makeBlank())
lexer.next()
if parseTerm():
hasHead = true
else:
return false
if isBlank(lexer.peek()):
expr.add(makeBlank())
lexer.next()
按照形式化表述严格处理即可
在 1. 输入合法性检验 中,类似的解析方法不仅能检测出异常成分,而且在解析过程中会建立相应的成分实例,最终计算 cost 时,每个类会计算自己的cost,然后上层类根据相应的规则结合起来
对于多余括号的判定,可以写一个返回因子数的方法,当括号里的因子数多于1时,即认为是表达式

