


309
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享Lexer 类:词法分析器
x、y+ - * ^ ( )exp、dx、dy、gradf() f{n}() [ ] ? :next() 和 peek() 方法供解析器使用。Parser 类:语法分析器
采用递归下降的方法,依据文法调用不同的 parse 方法。
各种 parse 方法将 token 流按照语法规则解析为 Polynomial 对象。
支持的语法结构:表达式(加减)、项(乘)、因子(数字、幂函数、表达式、指数函数、自定义函数、选择式、求导)
Polynomial 类:多项式类,内部使用 HashMap<Mono, BigInteger>,键为单项式,值为系数。
提供:
Add、Subtract、Multiply、Power、Divide (除数为常数)Substitute(Polynomial p) 将变量 x 替换为多项式 p,用于表达式函数调用DriveX()、DriveY()print() 自动处理系数、指数、exp 嵌套值得一提的设计:
在构造函数中删除系数为 $0$ 的项,然后所有运算方法按如下设计,便可以保证任意时刻均不会出现系数为 $0$ 的项,无需额外考虑。
public Polynomial(HashMap<Mono, BigInteger> coefficients) {
this.coefficients = coefficients;
Iterator<Map.Entry<Mono, BigInteger>> iterator = this.coefficients.entrySet().iterator();
while (iterator.hasNext()) {
Map.Entry<Mono, BigInteger> entry = iterator.next();
if (entry.getValue().compareTo(BigInteger.ZERO) == 0) {
iterator.remove();
}
}
}
public Polynomial Add(Polynomial x) {
HashMap<Mono, BigInteger> results = new HashMap<>(this.coefficients);
for (Map.Entry<Mono, BigInteger> entry : x.coefficients.entrySet()) {
results.put(entry.getKey(), results.getOrDefault(
entry.getKey(), BigInteger.ZERO).add(entry.getValue()));
}
return new Polynomial(results);
}
Mono 类:单项式类,表示形式:x^a * y^b * exp(Poly),其中 exp(Poly) 表示指数函数,参数为多项式。
Multiply(Mono)Substitute(Polynomial)DriveX()、DriveY()(使用链式法则)print() 配合系数输出Function,RecFunction 类:函数类,用于存储和调用函数。
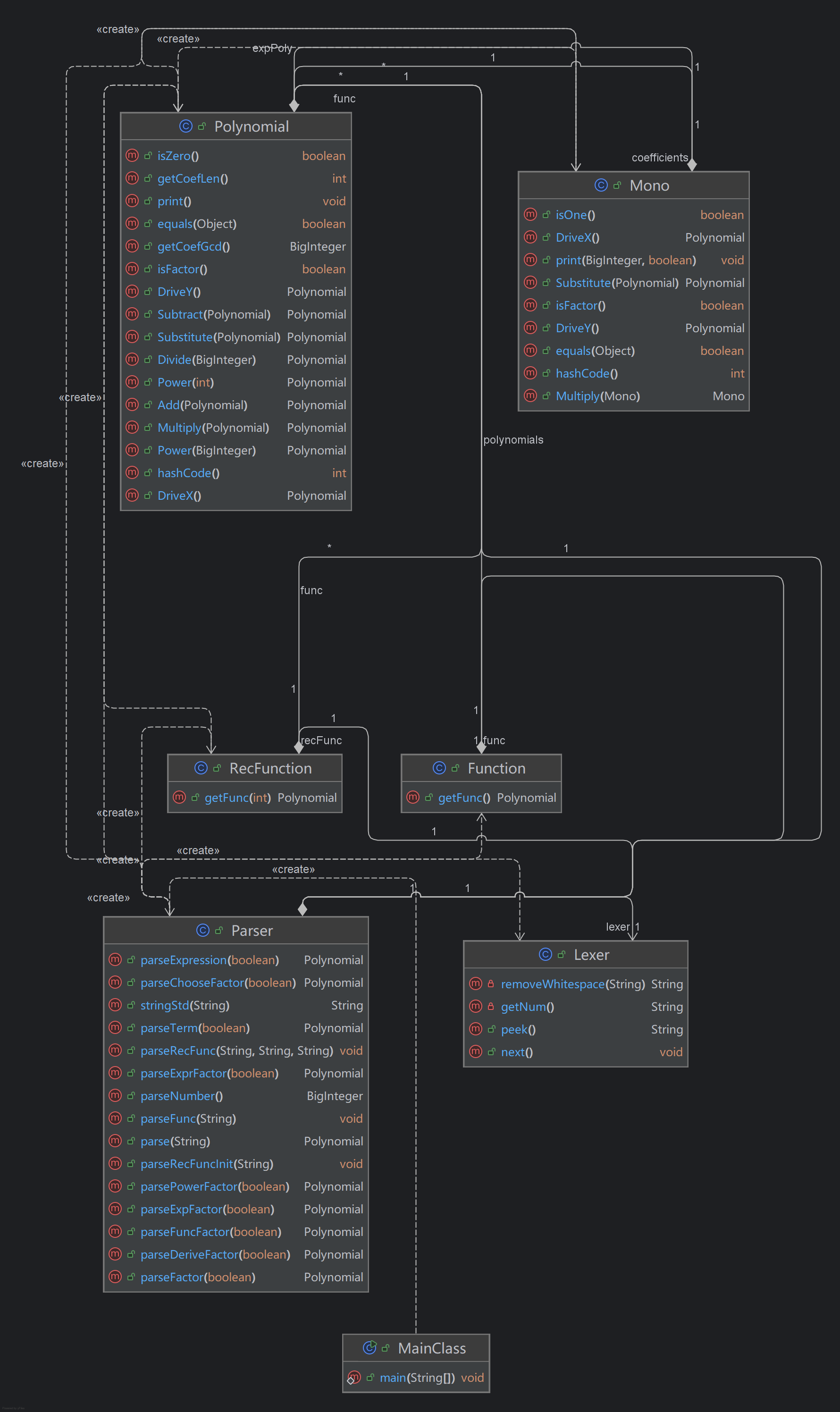

可以看出,代码的主要部分为 parser 的解析部分与 Polynomial,Mono 的计算部分。
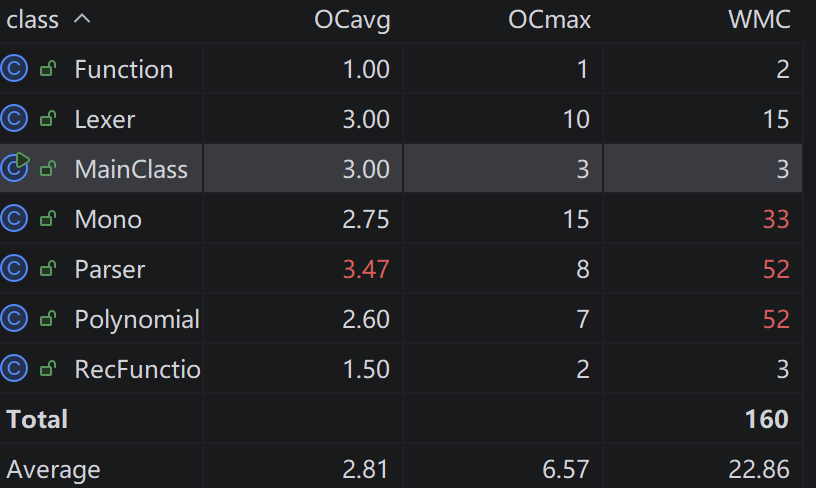
可以看出,由于实现的类较少,每个类 WMC 较大。
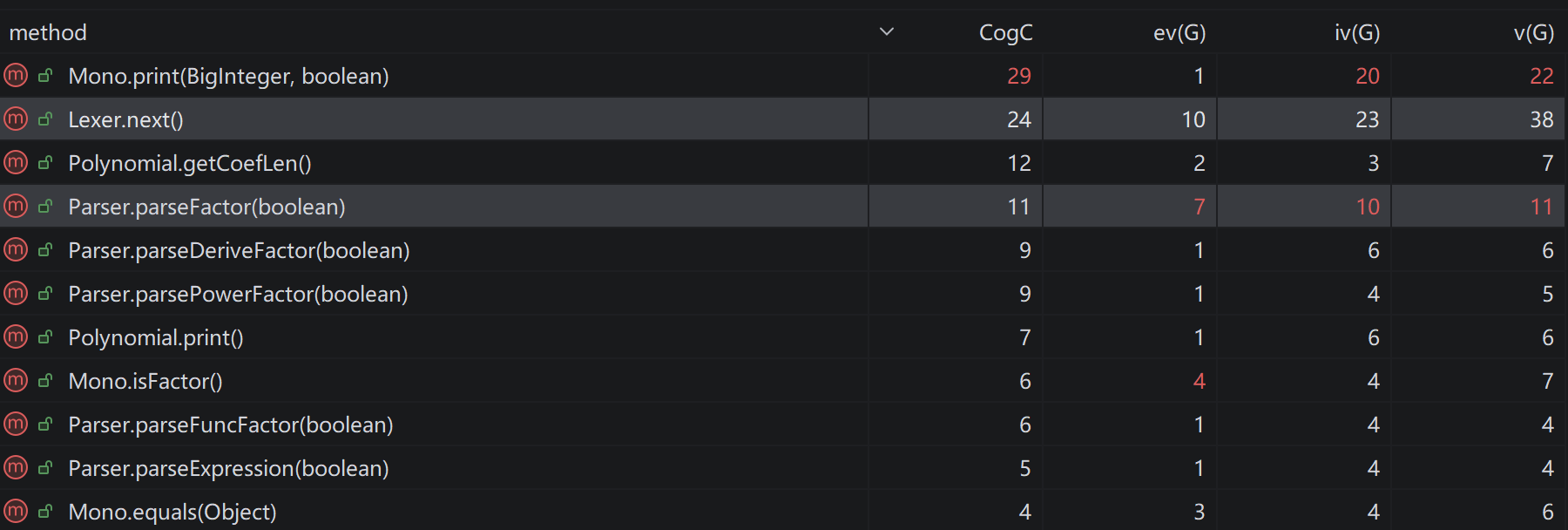
print 函数由于考虑了各种输出优化,故认知复杂度较高。lexer.next 函数需要识别各种 token,分支较多,故认知复杂度较高。Factor 接口,对每种因子新建一个类进行存储和管理,而是选择将所有因子都以多项式的结果进行存储和管理。这直接导致我在本单元中仅使用较少的类,而在多项式类中方法繁多。我认为两种架构各自有其可取之处:Factor 接口的架构,其能清晰的表征每种因子的结构,通过接口方法实现统一管理和计算。同时其将解析和运算两个步骤分离,实现功能解耦,能更好的支持选择因子中的短路要求。parser 类中,但是函数的定义解析需要同时用到 parser 类和 lexer 类的方法,而且使用的是同一个 lexer,所以最后还是将函数的定义解析放在 parser 类中,函数类只实现了函数的存储和调用,这种功能分离的架构实在有些奇怪。通过对数学意义上的表达式结构进行建模,完成单变量多项式的括号展开,初步体会层次化设计的思想的应用和工程实现。
lexer 和 parser 类解析表达式,之后的迭代中添加新的功能,也需要在 lexer 类内部添加新的关键字,parser 类内部添加新的解析方法,后面不再赘述。parser 类使用递归下降的方法解析表达式,所有解析方法的返回值均为多项式,最后直接调用多项式的输出方法。通过对数学意义上的表达式结构进行建模,完成包含指数函数、自定义函数和新增逻辑判断结构的多项式展开与化简,进一步体会层次化设计的思想,并初步接触符号计算中的等价性判定问题。
equals 和 hash 方法从而实现判等,同时在代码中很小心的删除 0 系数项,避免其带来影响。在强测阶段因为未短路未选择分支而产生计算冗余,而笔者的架构中并未实现解析与计算分离,而是解析后立即返回多项式结果。为解决该问题只能采取一个下策,在 parser 方法中传入参数 calc 表示是否需要计算,如果不需要就只进行形式上的解析占位,然后返回空多项式。parser 类的方法,将得到的多项式结果存储下来。多项式和单项式类实现 substitude 方法 ,调用函数时将因子代入多项式即可。通过对数学意义上的表达式结构进行建模,完成包含求导运算、递推函数等复杂结构的多变量表达式的展开与化简,深度体会层次化设计的思想及其在复杂问题中的应用。
recFunction 类用于存储和查询即可。总体而言,第三次迭代并没有新增较为复杂的功能,只需在之前的架构上稍加修改即可。这也是我耗时最短的一次作业。
BigInteger 类 。在 hw1 中我曾尝试搭建评测机进行代码测试,但发现随机数据并不能有效找出代码在边界情况下的错误,效率较低,因此在后续的作业中放弃了此种做法。
在后续的作业中,我的 hack 思路主要是先结合自己在编写代码过程中认为可能出现的问题(比如表达式等价关系判断)构造一些数据。此外我也会阅读代码容易产生问题的地方(比如输出函数exp括号的问题),针对此构造数据。
exp(x*y),这明显是没有考虑到多变量加入对因子判定的影响。exp 嵌套的数据。本单元作业中主要在检查代码正确性的方面使用了大模型工具,其余部分(代码编写,性能优化)均由自己完成,具体而言:
在 hw1 中使用大模型工具生成评测工具,进行测试。该评测机只能实现数据的纯随机生成,测评结果并不令人满意。
在完成作业后和互测过程中,使用大模型工具分析代码中的错误。大模型很容易找到输出格式的各种错误(我认为这些都是代码编写过程中产生的细节问题,比如结果为0时输出空字符串),也能找到性能方面的问题(比如提供cost计算方法,其能发现选择表达式未短路造成的性能影响)。当然,其结果不一定准确,也会产生一些错误的分析过程。
总体而言,我认为大模型已经能较好的解决目前作业的各种要求。
这里吐槽一下,第一次实验课代码解析表达式的方式是通过加减号分隔处理,似乎并没有采用递归下降的方法。我在 hw1 中也采用了类似的方式,但发现其并不能很好的处理多层嵌套的复杂表达式,只能被迫重构代码。感觉可以替换成更标准的递归下降的形式,给出一个大致的架构方便同学们学习。

