第一单元架构分析
一、度量数据汇总
1.各类度量指标
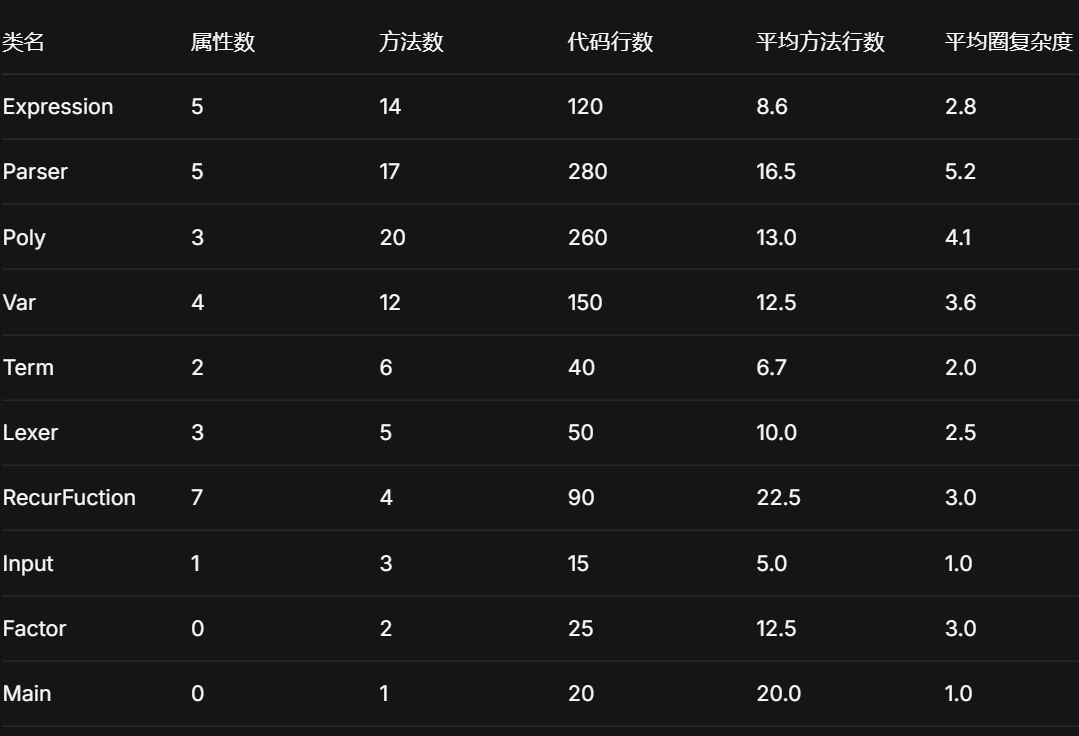
2.各类结构展示
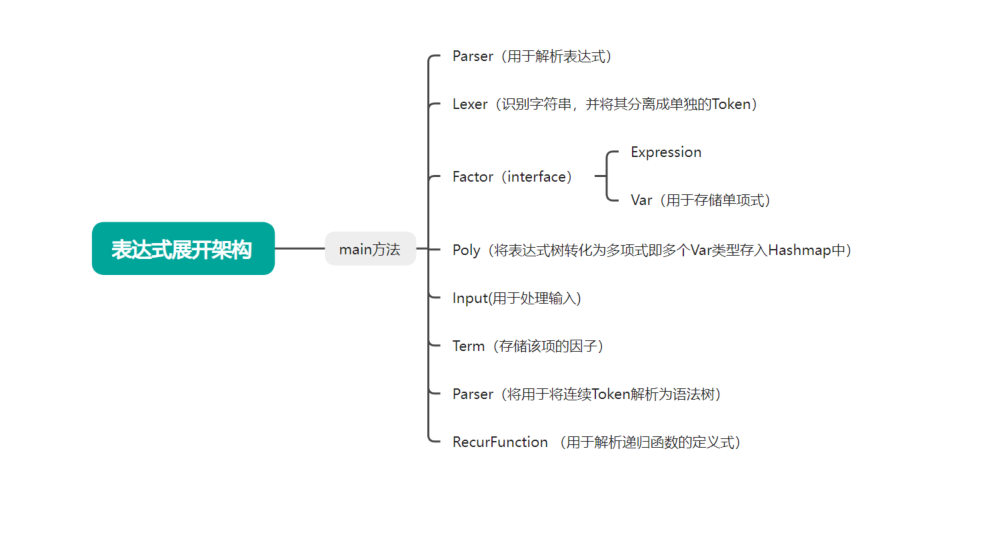
3.耦合度与内聚性分析
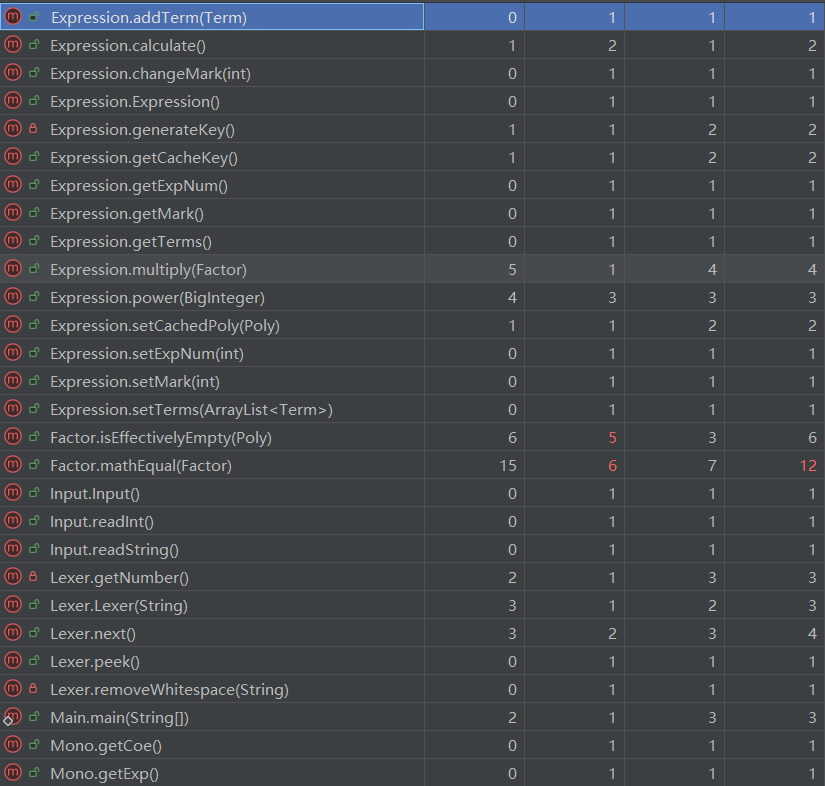
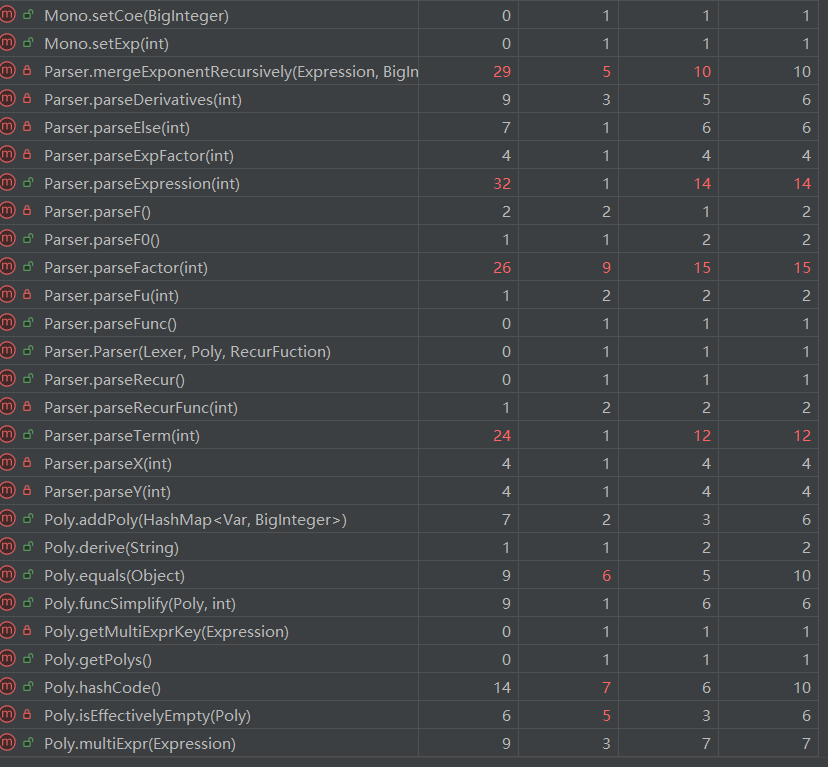
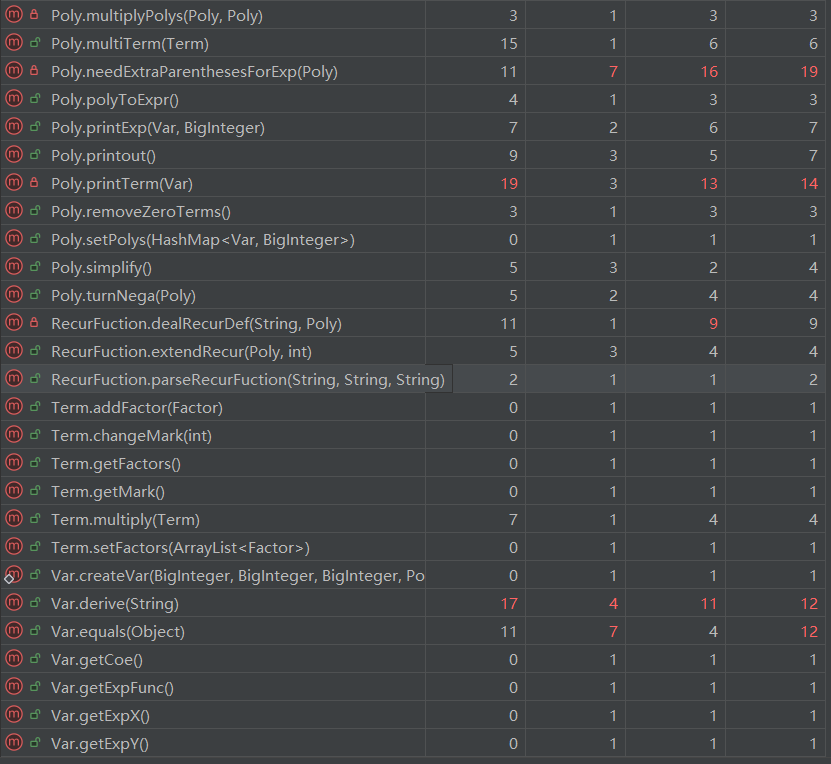
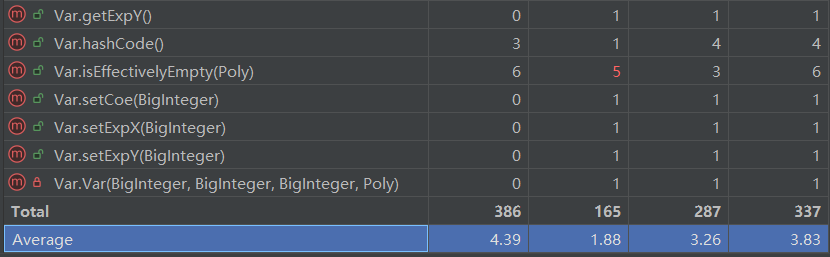
- 问题分析:该结果基于 MetricsReloaded 工具生成,其中从左往右各项分别为CogC、ev(G)、iv(G)、v(G),部分方法耦合度较高导致CPU运行时间过长,递归下降深度较大。
二、各类设计考虑
1、Expression(表达式类)
- 设计考虑:表示由Term通过加减号连接的表达式,支持指数运算、乘法运算和缓存。采用组合模式,Expression包含多个Term。
- 优点:有缓存机制避免重复计算
- 缺点:与Poly双向依赖,职责边界模糊
2、Parser(解析器类)
- 设计考虑:递归下降解析,每个非终结符对应一个parse方法。支持嵌套表达式、函数调用、递归函数。
- 优点:解析逻辑相对清晰
- 缺点:方法过长、分支过多、与多个类高耦合
3、Poly(多项式类)
- 设计考虑:核心数据结构,使用HashMap<Var, BigInteger>存储多项式。提供运算、化简、输出功能。
- 优点:支持复杂的指数函数运算
- 缺点:职责过重(运算+输出+缓存+转换)
4、Var(变量类)
- 设计考虑:表示幂函数x^a*y^b和指数函数exp(f)的组合。通过equals/hashCode实现同类项合并。
- 优点:指数函数嵌套处理较好
- 缺点:equals方法复杂,与Poly循环依赖
5、Term(项类)
- 设计考虑:表示由Factor通过乘号连接的项。相对简单,职责单一。
- 优点:简单清晰
- 缺点:multiply方法创建新对象时逻辑略显冗余
6、Lexer(词法分析器)
- 设计考虑:预处理连续符号,提供token流。独立于Parser。
- 优点:符号化简做得好
- 缺点:next方法过于简单,不能处理多字符token
三、架构设计体验
HW1
第一次作业中参考了作业中的提示信息采取了以下步骤进行架构
1、预处理
2、解析语法树
- 将连续字符串识别为Token
- 用Parser类将连续Token转化为语法树存在结果Expression中
3、将语法树转化为多项式
4、输出结果
HW2
第二次作业中扩展了Var类中存储的属性,将指数函数的指数表达式存在Var中,且扩展了解析因子的方法,将选择表达式与自定义函数还有指数函数在解析语法树时直接转换为对应的Var因子或者Expression因子。
HW3
第三次作业中再一次扩展了Var中存储的属性,加入了Biginteger型的变量用于存储y的指数;加入了新的类RecurFuction用于解析并存储递归函数的定义;加入了新的解析方法用于存储y的指数,并且用来解析导数符号;在Poly、Var类中加入了新的方法derive用于解析因子的导数
迭代新情景
- 新情景:加入了新的变量
- 解决方法:仅在Var中增加属性存储新变量的指数并在解析因子的ParseElse方法中加入判断该变量名的条件
分析自己程序的bug
- 在第一次迭代后加入选择表达式后,需要判断数学相等,在最初的数学相等方法中出现了逻辑错误,后来改为将两个多项式相减然后判断是否为0
- 第三次迭代中发现导数因子后如果有指数会报错,忘记在解析导数时解析指数
测试策略
1、特殊结果测试
- 例如简化后结果为0的,或者指数函数指数表达式化简后为0的应简化为1等
2、针对题设表述中的细节测试
- 例如在递归函数定义中系数可为正或负,递归函数定义中f{0}和f{1}的顺序可以交换
泛化测试
四、大模型相关使用
1、方法编译错误检验
2、结构优化
3、内置方法使用的学习
- 例如符合判断Hashmap中是否存在某键值对可以使用containsKey方法
五、心得体会
本单元收获
- 递归下降解析:从零实现了一个完整的解析器,理解了编译原理
- 面向对象设计:深刻体会到"职责单一"的重要性,Parser的膨胀导致过分递归下降
- 缓存的重要性:指数运算是指数爆炸的,没有缓存HW3会大量CPU超时
教训
- 重构要及时:第二次作业Parser中的解析Exprssion方法超行,没有拆分导致第三次更糟
- 过度循环:Var→Poly→Expression→Term的循环让代码在调试时难以理解
六、未来方向
个人觉得oo课上可以更加结合作业展开



 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
