



307
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享第一单元的OO课程已经落下帷幕。在这一单元的三次作业迭代中,我的多项式解析与计算系统经历了从雏形到相对完善的演进过程。初期由于试图用简单的字符串替换来处理复杂的代数逻辑,我遇到了严重的扩展性瓶颈。随着迭代的深入,我深刻认识到了抽象语法树AST与层次化设计的重要性,并最终将架构重构为基于 AST 解析与动态上下文求值的模式。下面我将结合代码度量数据、UML 类图以及测试策略,对本单元的架构演进与实践经验进行总结。
我的最终版本大致可以分为三个核心层级:
Parser,负责将输入的字符串流进行词法切分并自顶向下组装成语法树。Expr、Term 以及实现了 Factor 接口的众多节点类(VarFactor、ExpFactor、FuncFactor、SelectFactor 等)。这一层主要负责承载语法结构,不涉及具体的代数化简操作。Poly(多项式核心计算引擎)与 MonoKey(单项式的底层键值,用于支持哈希合并)。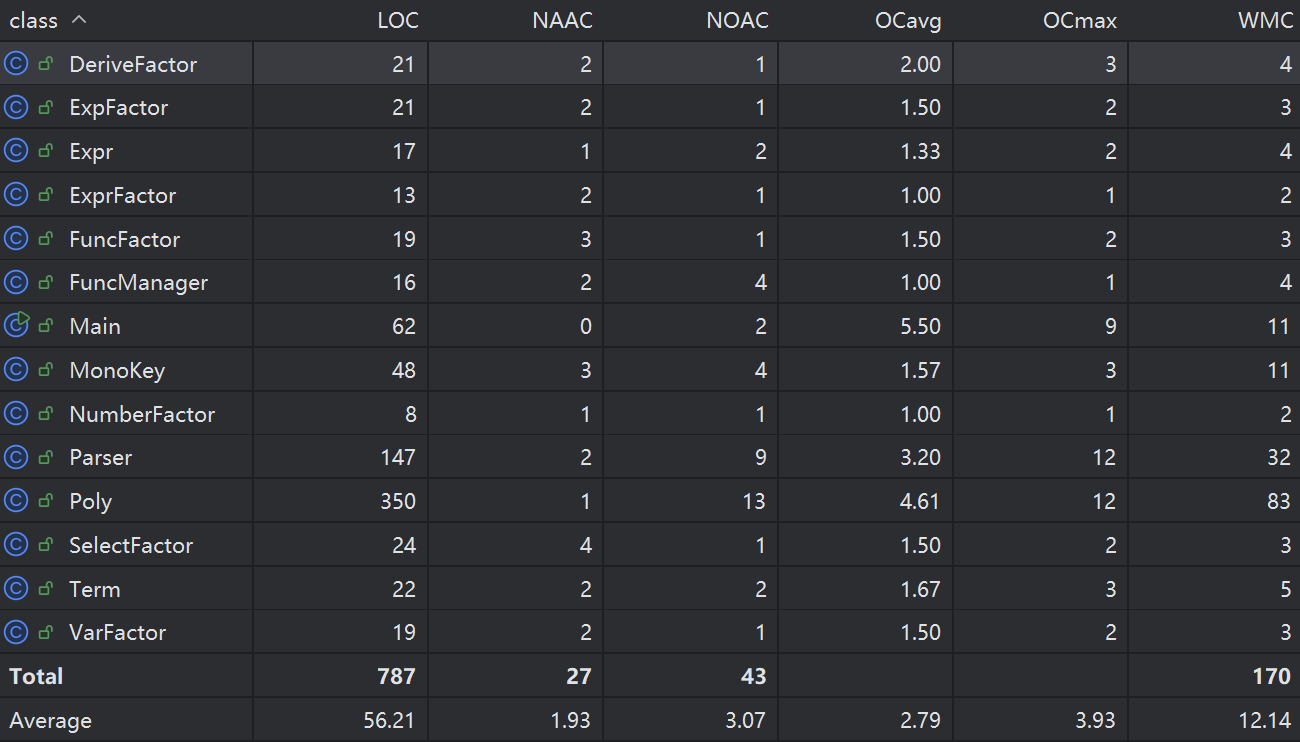
从上述 Metrics 度量数据表中,可以清晰地看出当前代码架构的特征:
NumberFactor、VarFactor、ExprFactor 等 AST 节点类,其代码行数(LOC)普遍在 10 ~ 25 行之间,方法数(NOAC)仅有 1~2 个,且类的总加权复杂度(WMC)平均在 3 左右。这表明系统在语法树节点的设计上,成功将“数据结构承载”与“代数计算行为”剥离,节点类实现了极高的内聚性。Poly 类和 Parser 类上。特别是 Poly 类,代码行数达到 350 行,方法数 13 个,WMC 高达 83,并包含全局最高的单方法圈复杂度(OCmax = 12)。这印证了当前架构的一个隐患:Poly 承担了过多的职责(涵盖了多项式的加减乘计算、偏导数计算、提取公因式优化以及格式化输出。在后续的设计中,将 Printer(格式化输出逻辑)从 Poly 中剥离是降低系统复杂度的首要任务。以下为本系统的核心架构 UML 类图:
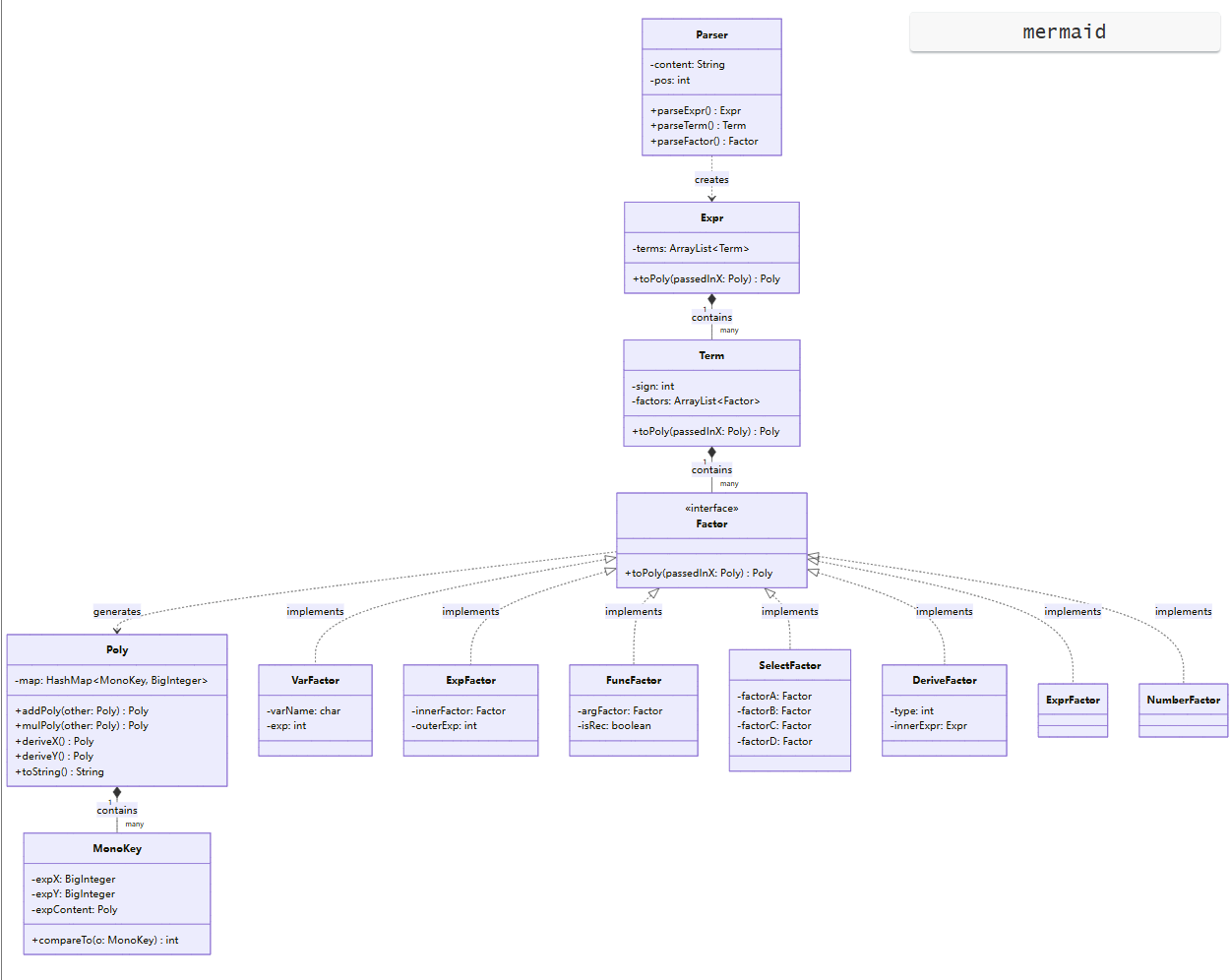
本类图隐去了辅助变量与 Getter/Setter 方法,着重展示系统的核心交互链路:
Factor 的动态上下文求值: toPoly(Poly passedInX) 是本系统最核心的设计。系统并未在 AST 树上进行深拷贝和节点替换,而是在执行求值时,直接将已化简的实参多项式 passedInX 作为上下文环境传递给子节点。这一设计从物理层面上杜绝了变量代入时可能产生的符号混淆和作用域污染。MonoKey 的底层哈希合并: 将最终的表达式统一抽象为 HashMap<MonoKey, BigInteger>。MonoKey 内部封装了 expX、expY 以及 expContent(Poly)。通过重写 equals 和 hashCode,保证所有在数学意义上同构的项,在存入 Map 的瞬间自动完成合并同类项,有效控制了状态空间,防止 TLE 和 MLE。DeriveFactor和 SelectFactor均被视为普通的 Factor,在解析阶段仅作原样建树,直到调用 toPoly 阶段才进行实际的偏导计算或条件真值判定,保障了计算逻辑的自洽与安全。exp 和自定义函数的引入,进行了彻底的架构重构。确立了 Expr -> Term -> Factor 的严格 AST 树结构,并抽象出 MonoKey 来支持嵌套 exp 的表示,规范了标准化多项式的流转。passedInX 上下文传参机制,面对复杂的递推函数 f{n},系统无需维护复杂的闭包环境,只需计算出实参多项式并传入即可,AST 树结构保持了极高的稳定性,仅需新增相应的算子节点类。若在当前架构上引入第三维度变量 z 及对应的偏导算子:
MonoKey 中增加 BigInteger expZ 属性并同步更新 hashCode 与 equals;计算引擎 Poly 中可复用现有的求导逻辑,新增 deriveZ 方法;解析层 Parser 补充相应分支即可。基于哈希映射的同类项合并机制和 AST 接口完全不需要伤筋动骨,符合开闭原则。在强测和互测阶段,本系统的代数计算引擎未出现任何逻辑计算错误,但因格式化输出(Wrong Format)逻辑的疏漏产生了一个 Bug。
x^8 * y^8),且该项作为参数传入了 exp 函数内部。...*exp(x^8*y^8)...*exp((x^8*y^8))Poly.isSimpleFactor() 方法中。原逻辑判断为:若内部无嵌套的 exp,且整体系数为 1,且总幂次 sumXY > 0,则判定为简单因子并剥离外层括号。但我忽略了 x 和 y 可能同时存在的情况。当 x 和 y 同时存在时,其在形式化文法中构成了一个项,必须外加括号降级为表达式因子后,方可合法放入 exp 内部。对比发现,出现 Bug 的 isSimpleFactor 方法由于揉合了大量的状态判断逻辑(判断 x/y/exp 的组合情况),其圈复杂度远高于纯粹进行数学化简的 mulPoly 等方法。
错误的抽象比高复杂度更危险。字符串输出的合法性判定不应过度依赖底层的数学多项式模型去反推。更为合理的设计是专门剥离出一个负责 AST 或多项式结构化输出的 Printer 类,使 Poly 纯粹聚焦于数学计算。
在互测阶段,由于同房间同学的代码架构普遍较为健壮,纯随机数据的命中率极低。我主要采取了“文法边界测试与特性组合测试”相结合的策略:
---+x)、前导零等文法边界情况进行针对性测试,检验对方词法分析和语法分析层的鲁棒性,观察是否存在对符号优先级的误判。dx(dy(f{3}((x+y))+x*y)-x+y),或者将求导算子、函数调用置于选择式的分支判断中。此类测试能够有效检验对方的 AST 树是否真正实现了隔离与惰性求值,还是在解析或化简阶段发生了状态越界。exp 内部参数括号判断上踩过的坑,我专门针对格式要求严格的语法点,如必要括号、exp 参数格式设计用例,测试对方在输出阶段是否也会因为特判逻辑不严密而遗漏括号,产生格式错误。我的常规测试策略分为三个层次:
Parser,设计复杂的括号层次与递推定义格式;针对 Evaluator/Poly,重点测试函数替换、选择式的真假短路逻辑以及链式求导法则的正确性。在兼顾正确性的前提下,本系统进行了以下维度的性能优化:
HashMap<MonoKey, BigInteger> 进行状态维护。每次加法与乘法运算均即时合并同类项,保证了整个系统的状态空间始终收敛,是后续判定恒等、缓存乃至求导的基石。该优化完美契合数学本质,完全保证了代码的简洁性。toString 方法中,实现了诸如正项提前输出、exp(k*A) 与 exp(A)^k 的启发式转换等逻辑。虽然此举有效缩减了输出长度,但代价是极大增加了输出模块的逻辑重量,甚至引入了引发格式错误的风险。因此,复杂度和表现层优化必须加以隔离,未来应为复杂的转换规则单独建立回归测试集。equals 与 hashCode 模板,以及部分正则表达式的预处理替换。BigInteger 构造异常)以及复杂的逻辑盲区。回顾整个第一单元,我最深刻的感悟是:真正困难的不是把当前的功能做出来,而是在需求不断迭代时,代码能否依然保持可读与可控。
面向对象设计本质上是对问题域的物理建模。当尝试用字符串替换去处理代数关系时,面临的将是无穷无尽的正则陷阱与优先级冲突;而当将表达式抽象为 AST,将化简收敛于基于哈希的归一化多项式时,原本复杂的边界 Bug在架构层面上便不复存在。程序的正确性、可扩展性与可维护性,归根结底都来源于健壮的架构。
提供系统的错误边界防范提示: 诸如连续符号、exp 内部必要括号等极易踩坑的文法边界,我们往往不是无法实现,而是缺乏对其会引发错误的预见性。建议在指导书中提供更为系统的反面示例,引导大家在设计初期即将边界情况纳入架构考量之中。

