


302
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享以下是第三次作业(HW3)代码的完整度量结果。
| 类名 (Class) | LOC (代码行数) | CBO (类间耦合度) | LCOM (方法内聚缺乏度) | CSA (属性数量) | CSO (方法数量) |
|
|
177 |
15 |
1 |
4 |
15 |
|
|
215 |
6 |
1 |
2 |
33 |
|
|
155 |
5 |
1 |
4 |
15 |
|
|
82 |
4 |
1 |
3 |
5 |
|
|
55 |
6 |
1 |
2 |
2 |
|
|
28 |
0 |
0 |
24 |
0 |
|
|
25 |
4 |
1 |
4 |
3 |
|
|
20 |
3 |
1 |
4 |
2 |
|
|
18 |
1 |
1 |
2 |
3 |
|
|
16 |
3 |
1 |
2 |
2 |
|
|
12 |
2 |
1 |
2 |
2 |
|
|
12 |
2 |
1 |
1 |
2 |
|
|
12 |
2 |
1 |
2 |
2 |
|
|
11 |
2 |
1 |
2 |
2 |
|
|
9 |
1 |
1 |
1 |
2 |
|
|
5 |
1 |
0 |
0 |
1 |
避免了类过度臃肿:项目中类的平均行数约为 55 行。
最高耦合度的类:Parser (CBO = 15)
分析:解析器类 Parser 是整个项目中耦合度最高的。它不仅依赖了 Tokenizer,还包含了所有的AST节点。若要进一步优化,可以引入工厂模式 (Factory Pattern),让 Parser 仅负责语法推导逻辑。
最庞大的类:Polynomial (LOC = 215, CSO = 33)
分析:多项式类拥有 33 个方法。它承担了多项式的加、减、乘、乘方、求导等重任。因此必须拆分足够多的辅助方法。
| 方法名 (Method) | LOC (代码行数) | v(G) (圈复杂度) |
|
|
4 |
1 |
|
|
6 |
1 |
|
|
3 |
1 |
|
|
4 |
1 |
|
|
4 |
1 |
|
|
10 |
3 |
|
|
3 |
1 |
|
|
7 |
1 |
|
|
8 |
1 |
|
|
8 |
1 |
|
|
11 |
2 |
|
|
13 |
4 |
|
|
26 |
4 |
|
|
16 |
5 |
|
|
4 |
1 |
|
|
6 |
1 |
|
|
7 |
1 |
|
|
3 |
1 |
|
|
4 |
1 |
|
|
16 |
3 |
|
|
10 |
2 |
|
|
8 |
2 |
|
|
16 |
4 |
|
|
15 |
5 |
|
|
7 |
1 |
|
|
10 |
3 |
|
|
22 |
5 |
|
|
14 |
1 |
|
|
9 |
2 |
|
|
6 |
2 |
|
|
1 |
1 |
|
|
1 |
1 |
|
|
6 |
3 |
|
|
18 |
6 |
|
|
11 |
4 |
|
|
7 |
2 |
|
|
11 |
7 |
|
|
13 |
6 |
|
|
3 |
1 |
|
|
9 |
3 |
|
|
15 |
6 |
|
|
13 |
3 |
|
|
24 |
6 |
|
|
6 |
2 |
|
|
5 |
1 |
|
|
4 |
1 |
|
|
5 |
1 |
|
|
7 |
1 |
|
|
10 |
2 |
|
|
7 |
1 |
|
|
35 |
10 |
|
|
3 |
1 |
|
|
16 |
4 |
|
|
23 |
7 |
|
|
4 |
1 |
|
|
4 |
1 |
|
|
14 |
6 |
|
|
3 |
1 |
|
|
3 |
1 |
|
|
3 |
1 |
|
|
3 |
1 |
|
|
8 |
1 |
|
|
7 |
1 |
|
|
8 |
1 |
|
|
18 |
6 |
|
|
4 |
1 |
|
|
3 |
1 |
|
|
3 |
1 |
|
|
3 |
1 |
|
|
51 |
25 |
|
|
7 |
3 |
|
|
5 |
2 |
整体来看,项目中方法的平均圈复杂度为 2.7,平均代码行数为 9.8 行。可深入数据后,发现以下几个方法严重超标:
| 危险方法 (Method) | LOC (行数) | v(G) (圈复杂度) | 缺点 |
|
|
51 |
25 |
严重超标。方法内部堆砌了大量的
|
|
|
35 |
10 |
在控制多项式输出格式时,为了处理省略前导符号、系数为 1 等边界情况,导致
|
|
|
22 |
5 |
在处理基本因子时逻辑分支过多。
|
|
|
13 |
6 |
逻辑判断条件略微复杂,包含过多复合布尔表达式。 |
内聚性:在所有核心类中,绝大多数类的 LCOM 都接近于 1。
多态的运用:各类 AST 节点(AddNode, MulNode, ExpNode 等),它们的方法代码行数极短(均在 15 行以内),且圈复杂度基本为 1。
以下为第三次作业(HW3)的类图:
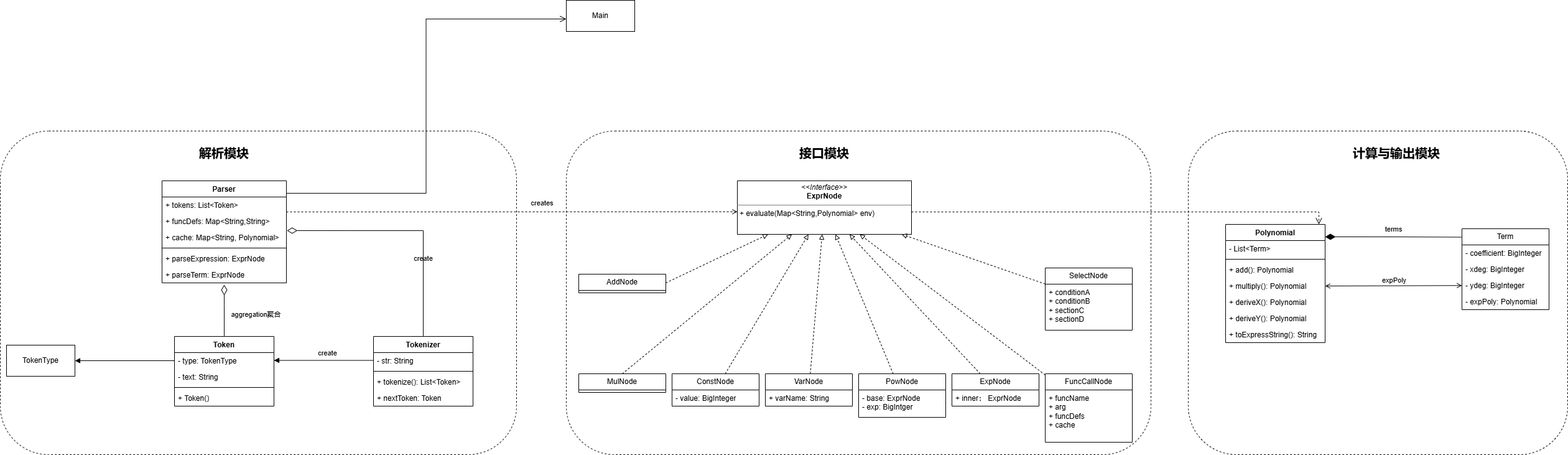
流水线:词法分析 -> 语法解析 -> 抽象语法树(AST) -> 计算求值。
词法分析 (Tokenizer, Token, TokenType)
将字符流转化为具有特定语义的 Token 单元。TokenType 枚举规范化了所有的输入种类。
语法解析 (Parser)
实现了递归下降解析器。
抽象语法 (ExprNode 接口及其实现类)
定义了统一的 ExprNode 接口。
输出 (Polynomial, Term)
Term (单项式):负责处理单项式的乘法和合并。
Polynomial (多项式):内部维护一个 Term 的集合(通常使用 HashMap 加速同类项合并),对外提供加减乘等代数运算接口。
优点:
职责划分清晰与易扩展性:解析阶段(构建 AST)与求值阶段(多项式运算)完全解耦。AST 节点面向 ExprNode 接口编程,在第三次作业新增求导算子和函数调用时,我只需新增 DeriveNode 和 FuncCallNode 即可。
缺点:
部分方法过度臃肿:正如度量分析指出的,Tokenizer.nextToken() 的圈复杂度过高。
HW1:确立递归下降解析,用HashMap处理单变量x的基础运算。
HW2:引入的指数与嵌套函数,因而采用Term和Polynomial组合的模式。
HW3:与HW2在架构没太大的差别。
HW1: parser类再读取指数时,应可以读取多重的“+”,但那时候忽略了这个细节。
HW2: 指数类型若是为int的话,范围根本不够,应为BigInteger(没有仔细读指导书的后果)
本地评测机测试:利用 Python 编写脚本自动生成大规模随机测试数据,除了可以测试自己的代码也可以顺便测试别人的。
AI测评机:由于本地评测机有时候生成的随机数据范围较小,因此有时候会直接把AI当测评机来用,从而找出自己程序中的漏洞或者是用来分析有可能存在的bug或是忽略的细节,并把从自己这发现的漏洞直接用在他人的程序上。(同一个房间往往忽略的细节或bug都有相似性)
HW1: 实现了正项提前(避免输出首项的 - 号前缀),并省略了所有无用的 1* 和 ^1 部分。
HW2 & HW3:主要实现 exp() 相关的深度优化。
内部简单时:若 exp 内部只有一项,尝试去括号消解。
内部复杂时:尝试通过提取公因数至外部来缩短整体长度。
结论是:过度优化不仅不能保证代码的简洁性,反而极容易反噬正确性与时间性能。
适度优化:“适度优化益脑,过度优化伤身”。时间是瓶颈的概率远远比空间高,尽量不要用极其复杂的时间复杂度去换取一点点空间的输出长度缩减。
第一次作业:一个暑假没碰代码遗忘了许多 Java 语法。因此主要把AI用于框架的构建,至于内部方法都是独立编写的,直接使用 AI 代码的比率较低。
第二次与第三次作业:新加功能模块我通常都是先大概写一遍然后直接丢给AI优化,写的好的话就没差,写不好的话就有AI帮我改写。(整体 AI 使用率 ~40%)
评测机搭建:非常依赖 AI。我的本地评测机主要是 AI 生成的。AI 在生成合法测试数据上表现极佳,但在进行 Python 校验端时常出逻辑错漏,仍需人工调试。
辅助找 Bug 与 Code Review:在一个功能完成后,我会让 AI 进行代码审查。但实践证明,AI 生成不出具有攻击性的测试用例,难以找出深层的架构 Bug。所以绝对不能认为 AI 的审查结果就一定正确。
说实话OO第一单元的难度还是挺高的,手搓代码的时间成本非常的高,但只有在自己手搓的过程中才能学到一些“自动化生成代码”(其实就是AI生成)学不到的东西。不是说“自动化生成代码”不好,只能说各自有各自的好处,只有两者并行,才能在这个AI高速发展的时代下,既不会与时代脱节,同时又能掌握基础技能。
除了学习方法以外,OO这门课的作业提交时间可能有点短的原因。因此莫名的让人会有种刺激感与上瘾(也有可能就是压力),彷佛无时无刻都想要搓一下代码。
可能以后可以开一个互测大排名,也就是第一单元结束后就展出一个名单说谁在互测中成功hack别人次数最多,成功防御别人hack最多,谁的平均性能分最高等等然后再分享代码之类的?

