


302
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享| 类 | 文件 | 类总行数 | 属性数 | 方法数 |
|---|---|---|---|---|
MainClass | src/MainClass.java | 72 | 0 | 1 |
Parser | src/Parser.java | 364 | 3 | 17 |
Lexer | src/Lexer.java | 50 | 3 | 5 |
Fx | src/Fx.java | 14 | 1 | 2 |
Fnx | src/Fnx.java | 58 | 8 | 2 |
Polynomial | src/expr/Polynomial.java | 418 | 1 | 17 |
Key | src/expr/Key.java | 52 | 3 | 6 |
| 方法 | 规模(行) | 控制分支数 | 备注 |
|---|---|---|---|
Polynomial() | 2 | 0 | 构造 |
Polynomial(Polynomial) | 8 | 0 | 构造 |
equals | 18 | 2 | |
hashCode | 3 | 0 | |
add(Key,BigInteger) | 9 | 1 | |
add(Polynomial) | 6 | 1 | for×1 |
multi | 25 | 2 | for×2 |
div | 8 | 2 | if×1,for×1 |
power | 16 | 2 | if×1,for×1 |
subst | 39 | 2 | for×2 |
negate | 6 | 1 | for×1 |
derive | 40 | 3 | for×1,if/else if×2 |
isExprFactor | 30 | 1 | if/else×1 |
toString | 33 | 6 | if×2,for×2,loop内 if×2 |
toString_subF | 57 | 9 | |
toString_subF_opt1 | 47 | 6 | |
toString_subF_opt2 | 37 | 3 |
| 方法 | 规模(行) | 控制分支数 | 备注 |
|---|---|---|---|
Parser(Lexer) | 3 | 0 | 构造 |
Parser(Lexer,Fx) | 4 | 0 | 构造 |
Parser(Lexer,Fnx) | 4 | 0 | 构造 |
Parser(Lexer,Fx,Fnx) | 5 | 0 | 构造 |
parseFnx | 42 | 5 | for×2,while×1,if×2 |
parseExpr | 27 | 5 | if/else if×3,if×1,do-while×1 |
parseTerm | 11 | 1 | while×1 |
parseFactorWithSign | 12 | 2 | if×2 |
parseFactor | 25 | 6 | if/else if 链×6 |
parseExprFactor | 22 | 3 | if×3 |
parseVarFactor | 24 | 3 | if×2 + if/else×1 |
parseExpFactor | 21 | 2 | if×2 |
parseCondFactor | 26 | 1 | if/else×1 |
skipCondBranch | 18 | 6 | while×1 + if/else if 结构×5 |
parseFuncFactor | 28 | 2 | if/else if×2 |
parseDeriveFactor | 30 | 2 | if/else if×2 |
parseNumFactor | 18 | 2 | if×2 |
综上来看,由于所有的数据都在Polynomial类中存储,所以Polynomial类中的方法不可避免地很多。
一些优化函数的圈复杂度也不低。
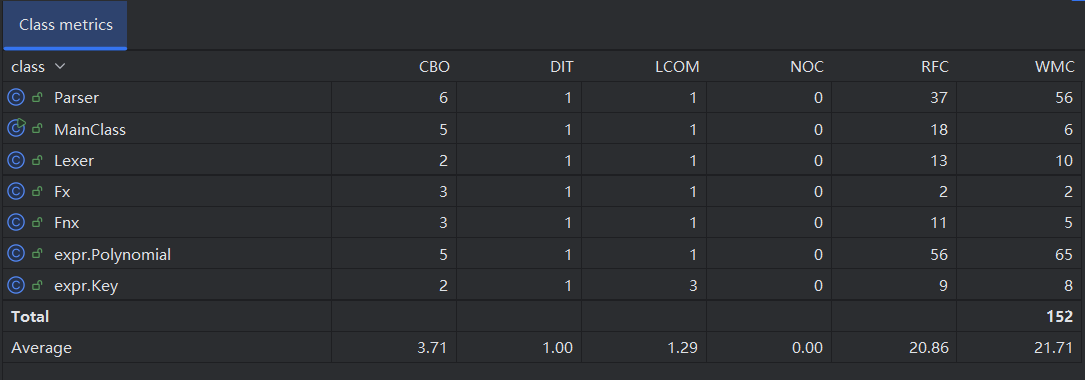
Parser和Polynomial类的RFC和WMC都很高,他们在这个题目里担任的职责较为单一,还是可以接受的。
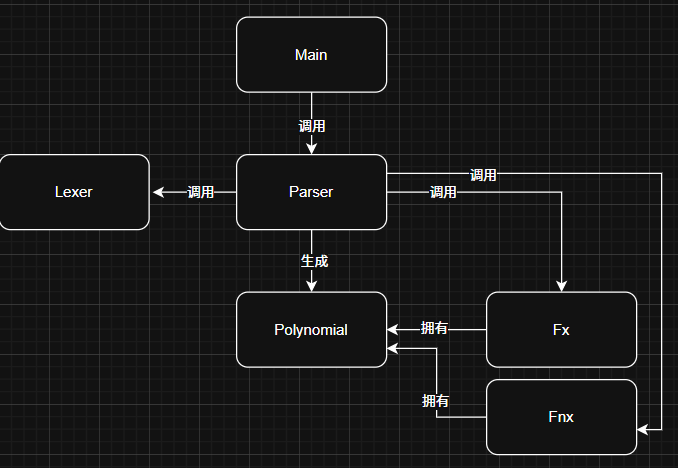
可以看到,虽然Parser是递归下降的写法,但是对应的Expr、Term、Factor都统一为Polynomial类了。
这样做:
Expr,Term,Factor类,第二次作业统一成了Polynomial类,之后写得还算顺风顺水)毕竟情景比较简单,直接无脑处理了Polynomial类,而且效果很差)可以看出这种架构没有可扩展性而言。ParseCondFactor方法。出现这样的问题是因为没有充分测试。toString方法的优化出错。出现这样的问题是优化写的控制语句比较复杂,而且没有经过充分测试。Parser类的ParseFnx方法。出现这样的问题是因为没有经过充分测试。Polynomial初始化时创建了不必要的对象,导致强测TLE。出现这样的问题是因为知识不充分,不了解创建对象的开销。没有设计压力测试。对于优化出错,对应代码的圈复杂度高,测试需要覆盖所有的情况,而且要在必要的时候引入子方法来减少方法的复杂度。
我在这两次作业犯了很多未充分测试的低级错误,以后要在易错的地方多搓数据点。
所谓测试能力和代码能力是息息相关的,测试应该被重视。
测试策略包括构造指导书提及的边界情况,例如exp(0)、x指数超过int64的情况。还有在规定cost范围内构造的嵌套样例。
第二次作业有exp双层括号和exp嵌套的问题,成功hack。
没有注意分析别人程序的架构。下次注意。
做的优化有:
常数因子*幂函数因子或常数因子*指数函数因子的形式,提出常数因子,去掉内层括号我的优化思路是在对应的位置替换为一个子函数,这样保证了我可以选择是否优化,我认为还挺简洁的。不过这样写的子函数更像是一个补丁。。。没有涉及代码复用。
copilot的代码补全,对于重复性的工作和代码纠错很有帮助。性能优化是手写的。cursor或claude code等上下文很长的ai,写出来的代码自己没有把握。。。我还是oop小白,更倾向于提问获得思路,然后手动实现。index成员变量保存幂函数的指数。个人认为这个index框架是AI写的。因为变量名和这个注释。// 第一次作业 开阳星
// Expr类
// ...
if (this.index >= 2) {
Poly forIndex = result.clonePoly();
// ! index<=8, we needn't fastPower for now.
for (int i = 1; i < this.index; i++) {
result = result.mul(forIndex);
}
}
// ...
按照助教给的思路,写下博客之后,发现我在以下几点做得非常不足:
虽然U1的题目内容并不复杂,但是设计的时候应该尽量体现OOP的设计思想,而不是写出能跑的代码就可以了)开闭原则,注入依赖,层次化设计等需要多磨练。另外构造数据测试的时候该构造也得构造,该学习别人架构的时候也得学习,不能摆烂。
建议让表达式的单项式变得更复杂,逼迫同学们放弃设计一个类就一劳永逸的想法。。。
在递归下降的结构里,严格按照写出的文法进行判断,{}中的内容用while循环,[]用if等等。如果不符合预期就抛出异常。
在递归下降的结构里一层一层回传cost,或者在递归下降的过程中建立语法树,遍历一遍

