


302
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享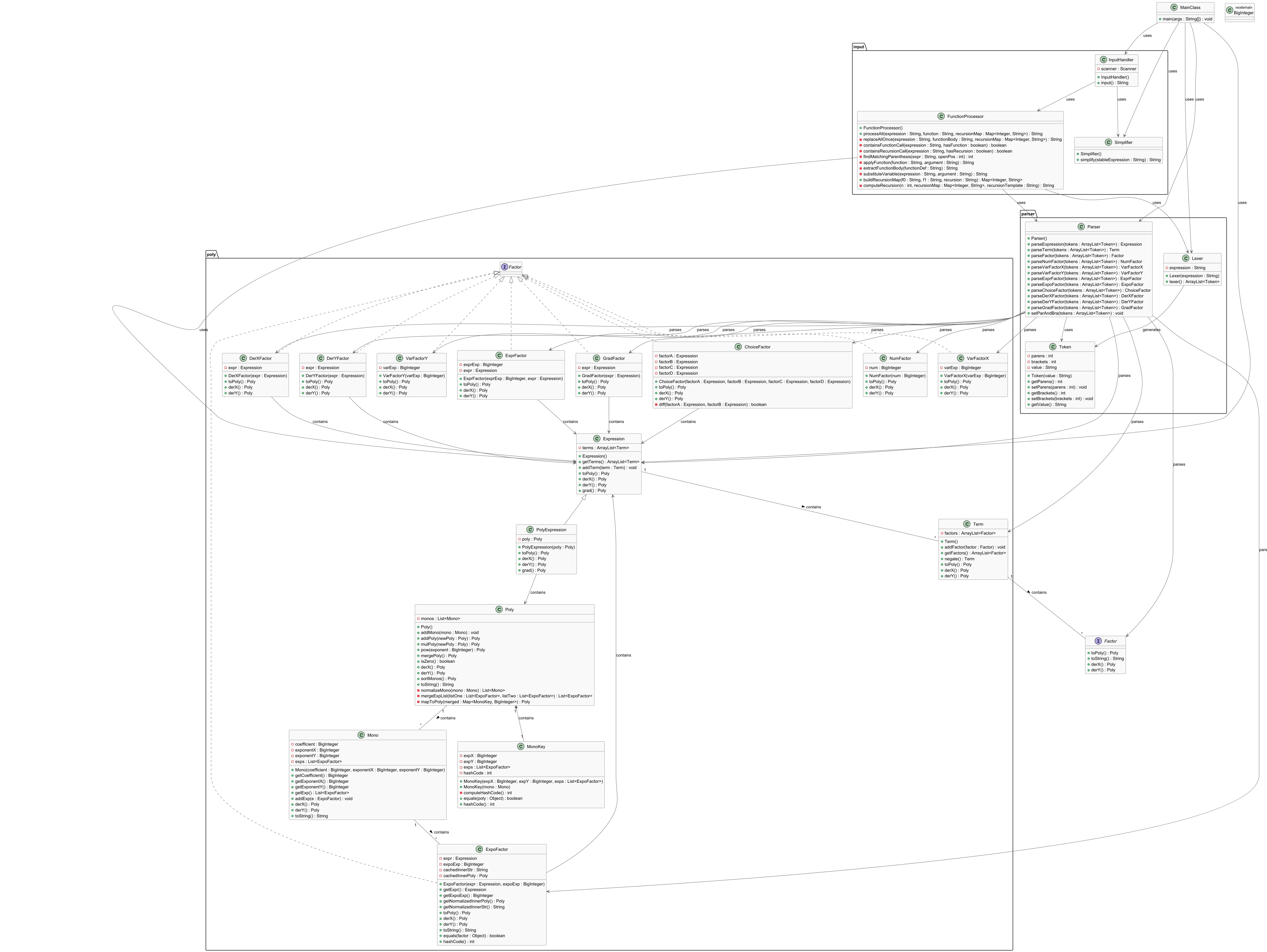
| Extension | Files Count | Total Size (KB) | Min Size (KB) | Max Size (KB) | Avg Size (KB) | Total Lines | Min Lines | Max Lines | Avg Lines | Code Lines |
|---|---|---|---|---|---|---|---|---|---|---|
| java | 22 | 53.48 | 0.15 | 11.21 | 2.43 | 1630 | 11 | 279 | 74 | 1400 |
| Total Statistics: | ||||||||||
| Total | 22 | 53.48 | 0.15 | 11.21 | 2.43 | 1630 | 11 | 279 | 74 | null |
大部分类的内聚度较高,以数据耦合为主
代码有重复,在实现双变量时没有抽象父类;Parser, FunctionProcessor和InputHandler的内聚度较低且耦合多类
在第一次作业中需要完成含有常数因子、变量因子、表达式因子的多项式化简,将这三种因子统一在一个因子接口下。建立项类,其中储存因子,建立表达式类,其中储存项。实现lexer类,将输入的表达式分解为token,再实现parser类,将输入的token构建为含有表达式、项、因子三层的表达式树。实现Mono类Poly类,通过对每个因子实现toPoly方法将表达式树转化为Poly类对象,在转化过程中自然完成括号的展开,再通过Poly类中实现的mergePoly方法合并同类项,以及其中重写的toString方法将多项式转化为处理后的表达式字符串进行输出。
在第二次作业中新增指数函数、选择式因子和自定义函数。为处理自定义函数,实现了输入处理功能模块,用字符串替换的方式将表达式中的函数引用直接替换为展开后的函数。在Factor接口下实现了指数函数和选择式因子两个类并在lexer和parser中新增对应功能。对于选择式因子的条件判断功能,调用Poly类中的合并同类项功能实现,并且考虑到新增指数函数,对合并同类项的判断条件进行修改。
在第三次作业中新增递推函数、求导因子和变量y。由于递推函数序号最多到5,因此在输入处理功能模块直接进行递推函数序号从2到5的展开,将展开后的模板存储,按照和自定义函数同样的逻辑进行替换。新增求导因子在Factor接口下,对于构成表达式树的每个类都实现求导方法,形成递归调用,但是在我的设计总求导一次后返回Poly类型,因此需要再Mono类和Poly类中同样实现求导方法以支持高阶求导。由于变量y和变量x地位相同,因此实现对称的y变量因子类,在其他类中存储x变量因子相关属性的位置新增存储y变量因子的相关属性,并且对相应方法进行修改。
以上架构不能处理递推函数序号不限大小的情况,在研讨课上我意识到可以将函数也当作因子处理,在toPoly时再具体展开处理,通过HashMap存储已经展开过的递推函数以提升性能,这样的架构可以更方便地实现函数相关功能的扩展。
第一单元作业完成得非常坎坷,三次作业分别因为不同的原因没进互测。
在第一次作业中我没有认真阅读指导书,系数类型全部使用int而非BigInteger导致几乎全部强测数据点都错误;
在第二次作业中我出现了版本管理的问题,导致在截止时只能提交一个中测bug还未全部修改完的残缺版本,第二次作业的bug具体有以下2个:
以上bug可以分为以下几类
以后应当尽量使用节省时间和空间的思路和设计,尽量提前完成作业,在提交前花充分的时间枚举各种情况进行更完备的本地测试
第一单元作业在遇到性能bug时采取了一下方式进行优化:
第一单元作业中主要在以下两个地方使用了大模型:
希望在第二单元作业时能够在进行设计时就注意时间和空间开销,注意认真审题分析各种输入可能,对程序进行完本的本地测试,以后应当多参考oolens和学长学姐博客
建议可以多出一些oolens公众号文章提供思路和参考

