133,121
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享英伟达桌面超算,邪修玩法来了!
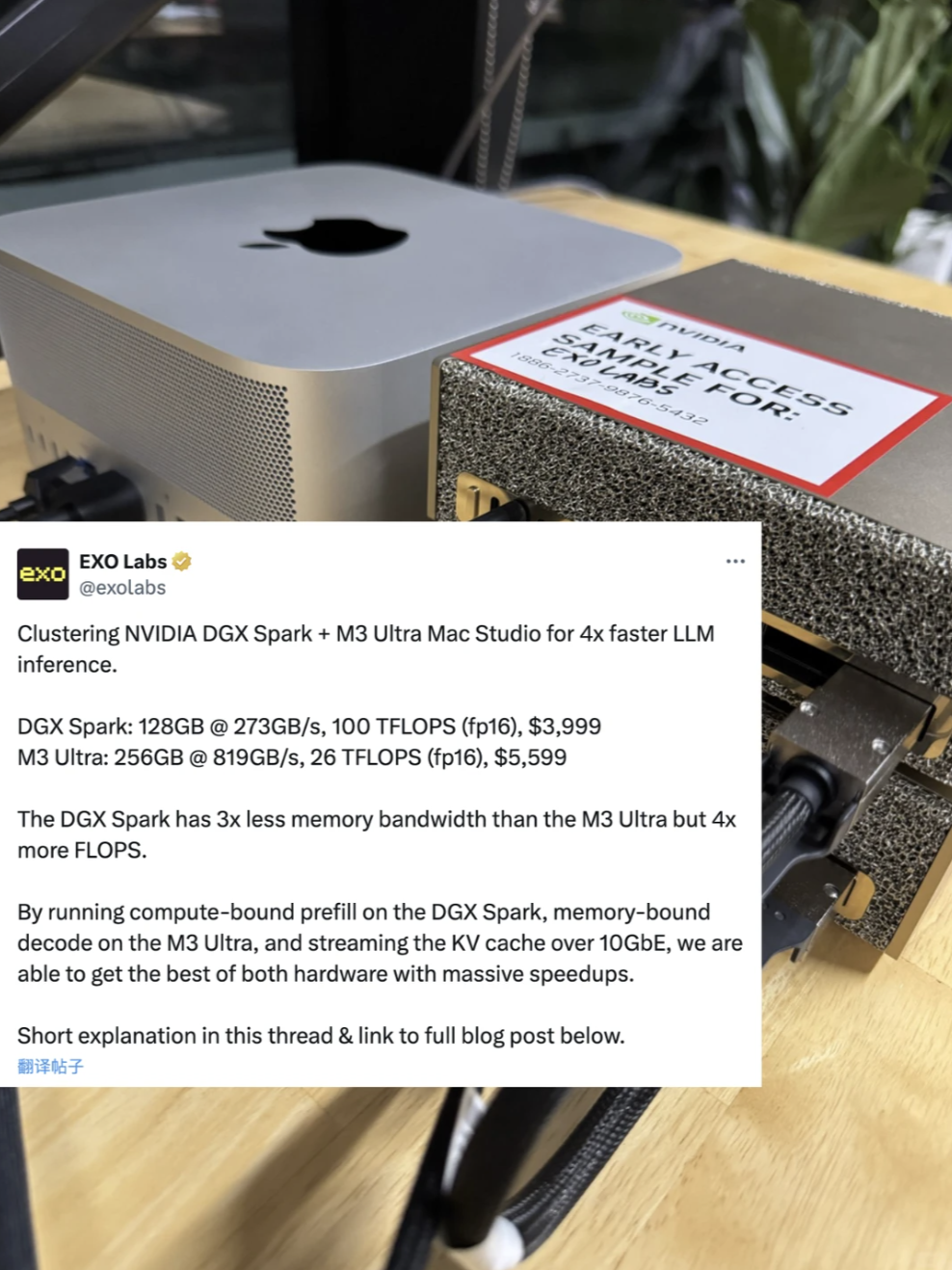
两台DGX Spark串联一台苹果Mac Studio,就能让大模型推理速度提升至2.77倍。 这是GitHub三万星大模型框架作者EXO Lab团队发布的最新成果。 这个EXO Labs,专门研究把大模型放到各种家用设备上运行。
团队将DGX Spark和搭载M3 Ultra的Mac Studio进行组合,利用它们各自的优势,在大模型部署上整出了新活。 那么,这套邪修组合具体是如何实现的呢? —— ⚙️ 要理解其原理,需要先看大模型推理的两个阶段:Prefill和Decode。
- Prefill阶段:处理用户输入Prompt,为每个Transformer层构建KV缓存。这一步计算量巨大,主要瓶颈是算力。
- Decode阶段:基于已构建的KV缓存,逐个生成token。这一步的计算量相对较小,主要瓶颈是内存带宽。 EXO Labs手里的两种设备,正好形成了性能互补。
- DGX Spark:算力强,但内存带宽较低。
- Mac Studio:算力相对较弱,但内存带宽极高。 所以,EXO Labs的思路就是把Prefill和Decode阶段分开,分别分配给擅长的设备,DGX Spark负责Prefill,Mac则负责Decode,这也就是AI Infra业界常说的PD分离。
🔗 关键挑战在于两个阶段之间的KV缓存传输 如果简单地等Prefill全部完成后再传输,通信开销会抵消性能优势。 EXO Labs的解决方法是流式传输 (Streaming)。类似于在线看视频,不需要等整个文件下载完。 大模型的KV缓存可以逐层进行传输。
第1层的Prefill在DGX上完成后,其KV缓存就立刻开始流式传输给Mac Studio进行Decode,与此同时,
第2层的Prefill在DGX上启动。这样,后续层的计算就与前序层的通信发生了重叠,极大地隐藏了延迟。 EXO框架还能自动完成这一切:启动时,它会自动发现并分析所有连接设备的算力、带宽、内存等特性,然后智能规划任务分配和数据流。
📊 最终实验结果 在DGX Spark和Mac Studio的组合下,运行Llama-3.1 8B模型: - Prefill速度是单独使用Mac Studio的3.79倍。 - Decode速度是单独使用DGX Spark的3.37倍。 - 整体推理速度是单独使用Mac Studio的2.77倍。 #ai #硬件 #邪修 #推理