


302
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享第一单元的三次作业,核心是围绕 “表达式的解析、展开、化简与语义计算” 层层递进:第一次作业聚焦单变量多项式的括号展开,第二次作业新增指数函数、自定义函数、选择式因子,第三次作业进一步扩展双变量支持、求导算子与递归函数。整个过程对我而言,与其说是在写一个表达式解析器,不如说是在需求的不断迭代中,被迫完成了从 “面向过程堆逻辑” 到 “面向对象做架构” 的思维转变。
| 作业轮次 | 类数量 | 总代码行数 | 方法总数 | 平均 CBO(耦合度) | 平均 WMC(复杂度) | 最大 WMC 所在类 |
|---|---|---|---|---|---|---|
| 第一次作业 | 3 | 217 | 16 | 0.87 | 22.13 | Parser(34) |
| 第二次作业 | 24 | 976 | 107 | 2.08 | 8.52 | TokenStream(38) |
| 第三次作业 | 27 | 1328 | 142 | 2.69 | 10.74 | Normalizer(51) |
从数据能看出非常清晰的变化趋势:
第一次作业:类少但复杂度高度集中整个程序只有Main、Parser、Poly三个类,核心逻辑全部压在Parser和Poly里,两个类的 WMC 分别达到 34 和 32,平均复杂度是三次作业里最高的。这种结构的问题非常明显:解析和计算强耦合,一个方法要处理多个分支,后续新增语法只能在原有方法里堆 if-else,扩展性几乎为零。
第二次作业:重构后复杂度分散,结构最均衡类数量从 3 个涨到 24 个,但平均 WMC 反而从 22.13 降到 8.52,说明我把原来集中在两个大类里的逻辑,拆分到了多个职责单一的小类中。这一次重构把程序分成了词法层、语法层、语义归一化层、输出层,每个层的职责清晰,耦合度也控制在合理范围,是三次作业里结构最健康的一版。
第三次作业:功能扩展后,复杂度重新向核心类集中我在第二次作业的框架上新增了双变量、求导、递归函数的支持,没有推翻重写,也证明了第二次的架构是有扩展性的。但代价是Parser、Normalizer、RecursiveFuncDef这些核心类的复杂度明显上升,因为我把函数替换、求导计算、递归展开、选择式判断的逻辑都堆在了这个类里,职责边界又开始模糊。
Poly:这个类的内聚性始终是最强的,它的职责非常单一——负责表达式的标准化表示、代数运算、同类项合并和恒等判断,所有方法都围绕这个核心职责,几乎不依赖其他业务类,耦合度极低Parser:这个类的耦合度始终是最高的,因为它需要同时依赖词法解析的TokenStream、语法结构的Expr节点、函数定义的FuncDef、语义归一化的NormalForm,还要处理所有因子类型的分支判断Expr/Term/Factor:第二次作业引入的这一套分层,是整个架构的核心。它们和题目给的文法定义完全一一对应,每个子类只负责自己的语法结构和语义计算,新增因子只需要新增子类,完全符合开闭原则。RecursiveFuncDef:第三次作业新增的类,职责是处理递归函数的三行定义、记忆化展开和调用替换。第二次作业的分层架构是最符合 OO 思想、最均衡的设计;第一次作业是原型,第三次作业是功能完整但局部设计妥协的产物。架构的核心价值,从来不是类越多越好,而是职责拆分越清晰,后续迭代的成本越低。
1. 第一次作业类图
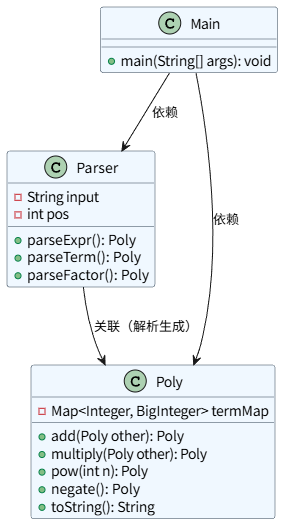
第一次作业的结构极其简单,Parser负责递归下降解析输入字符串,在解析的同时直接计算出Poly多项式对象,Poly内部完成多项式的加减乘幂运算和输出。优点是实现快、代码量少、调试路径短,出错了只需要查Parser和Poly两个类。但缺点也很明显,比如解析和计算强耦合,没有显式保存表达式的语法结构,后续新增任何因子类型,都要修改Parser的核心逻辑,扩展性几乎为零。
2.第二次作业类图
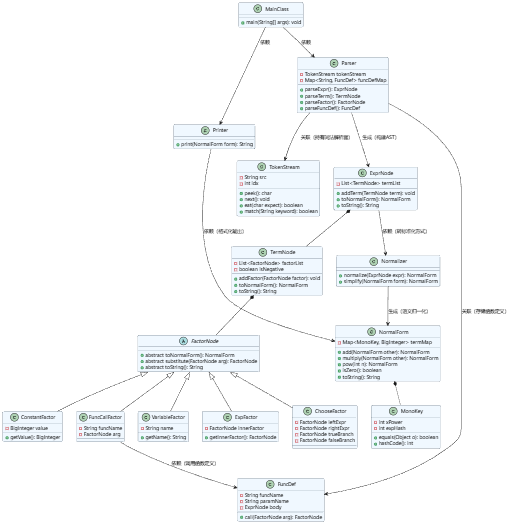
第二次作业是我整个单元最关键的一次重构,完全推翻了第一次的 “边解析边计算” 的模式,改成了先构建 AST 语法树,再做语义归一化,最后格式化输出的分层架构。
这个设计的优点有两个:
Expr/Term/Factor的分层和题目给的 BNF 文法一一对应,代码结构完全贴合人的理解逻辑。新增一种因子类型,只需要新增一个FactorNode的子类,不用修改原有解析逻辑,完美符合开闭原则。Parser只负责建树,不参与任何计算;Normalizer只负责语义归约,不关心输入是怎么解析的;Printer只负责输出,和计算逻辑完全隔离。这种拆分让 bug 的定位变得极其简单,也让后续迭代的成本大幅降低。当然这个设计也有不足:Normalizer和Parser的耦合度还是偏高,成为了系统的调度中心,后续新增语义规则时,这两个类很容易膨胀。
3. 第三次作业类图
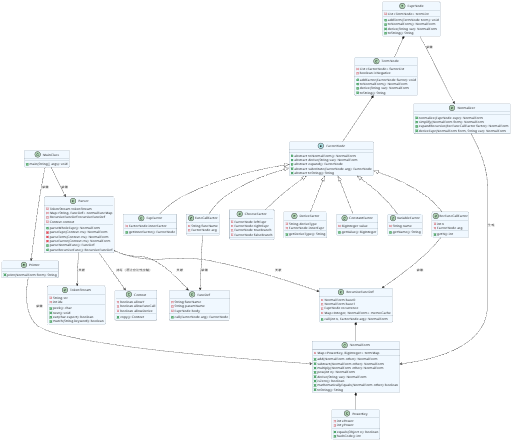
第三次作业的架构完全延续了第二次的分层框架,只做了扩展。这个设计的优点是充分利用了原有架构的扩展性,用最小的改动完成了新增需求;但代价是Parser和Normalizer的职责进一步加重,尤其是Normalizer,同时承担了函数替换、求导计算、递归展开、选择式判断、化简合并的职责,复杂度飙升,成为了整个程序里最容易出 bug 的地方。
1. 三次作业中架构如何逐步成型
第一次作业:需求只有单变量多项式展开,我想的是怎么快怎么来,直接用了递归下降解析时直接计算多项式的方式,没有任何分层,只求能跑通测试点。现在回头看,这就是典型的面向过程思维,完全没有考虑后续迭代。
第二次作业:需求一下子新增了exp、自定义函数、选择式因子,第一次的架构完全撑不住了,parseFactor()方法要加无数个分支,改一个地方就影响全流程。这时候我才真正理解了分层的意义,重构出了Expr/Term/Factor的 AST 分层架构,把语法结构和语义计算拆分开,架构真正成型。
第三次作业:需求新增双变量、求导、递归函数,这时候第二次的架构优势就体现出来了 —— 我只需要新增对应的因子子类,扩展归一化的语义规则,就完成了核心功能,完全不用推翻重写。只是在实现过程中,为了赶进度,把太多语义逻辑堆进了Normalizer里,导致复杂度回潮,留下了隐患。
这个过程让我明白,架构的选择不是为了看起来高级,而是为了应对需求的变化。好的架构,能让我在需求迭代时,只需要做增量拓展,不用推翻重来。
2. 重构前后的体验
重构后的优势是十分明显的,首先,代码层次完全清晰了,我能非常明确地分清楚,一个问题是出在词法解析、语法解析、语义计算还是输出格式化,bug 定位的效率提升了不止一个量级。其次,扩展性得到大幅提升,第一次作业新增一个因子,要改Parser的核心代码,还要动Poly的运算逻辑;第二次作业新增一个因子,只需要加一个子类,实现对应的接口方法,原有代码一行都不用动。再然后就是可维护性极强,每个类的职责单一,代码可读性极高,过了一周再回头看,依然能快速理解每个类的作用,而不是像第一次的代码,过了三天就看不懂自己写的分支逻辑了。
但显然重构也是有代价的,比如首先类的数量大幅增加,从 3 个类涨到 24 个类。其次就是开发周期变长,第一次作业我半天就写完了,第二次作业的重构花了我整整两天,才把整个分层架构搭起来,跑通基础用例。然后就是对象关系更复杂了,需要考虑类之间的依赖关系、继承关系,一旦职责边界没划清,复杂度就会重新集中到某个核心类里,比如我第三次作业的Normalizer。
这次重构让我最深的体会是,重构不是把代码拆成更多的类,而是重新分配职责。好的重构,是把原来一个大类要做的 N 件事,分给 N 个只做一件事的小类。
第三次作业中有两个bug印象深刻,第一个的输入如下
0
[((x-1)^2 == (x^2-2*x+1)) ? exp(x) : y]
我的程序错误地选择了y分支,但正确结果应该是exp(x)。我最开始判断A==B,是直接把A和B的字符串做对比,(x-1)^2和x^2-2*x+1的字符串显然不一样,所以被误判为不相等。这个 bug 的根源,是我没有理解 “表达式恒等必须建立在归一化的基础上”。字符串对比只能判断形式是否一致,不能判断语义是否相等。只有把两个表达式都转成统一的标准化多项式,再判断A-B是否为零多项式,才能真正实现恒等判断。最后我修改了选择式的判断逻辑:先把A和B都交给Normalizer转成NormalForm标准化多项式,再计算两个多项式的差,如果差是零多项式,就判定为相等,否则不相等。修复后,所有语义相等的表达式都能被正确识别。
第二个bug如下
3
f{0}(x)=x
f{1}(x)=x^2
f{n}(x)=f{n-1}(x)+f{n-2}(x)
0
f{20}(x)
我最开始实现递归函数展开时,没有做记忆化缓存,每次调用f{n}(x)都会重新递归计算f{n-1}(x)和f{n-2}(x),时间复杂度是 O (2^n),n=20 时就会出现大量的重复计算,不仅速度极慢,还会导致栈溢出。在RecursiveFuncDef类里新增了HashMap<Integer, NormalForm>缓存,把已经计算过的f{k}(x)的结果存起来,下次再调用时直接从缓存里取,不用重复递归计算。最后修复后,哪怕是f{100}(x)也能在毫秒级完成展开,完全不会出现栈溢出的问题。
我所有的 bug,本质上都来自比较同质化的问题,首先就是方法职责不清晰,圈复杂度太高了,所有出 bug 的方法,圈复杂度都在 20 以上,一个方法要处理多个分支、多个逻辑,自然容易漏判、错判。其次,我对底层数据表示的考虑比较不充分。然后就是语义规则的理解比较不到位,比如选择式的恒等判断,没有理解归一化是语义判断的基础。
如果要避免这些 bug,最好的方式不是写更多的测试用例,而是从设计上拆分职责,让每个方法只做一件事,同时在设计初期就把边界情况、数据范围考虑进去。
第一单元三次表达式作业,让我真正完成了从面向过程到面向对象的思维转变。起初我只追求功能实现,采用解析与计算耦合的结构,结果在需求迭代时难以扩展,不得不彻底重构。之后搭建的分层架构与 AST 树设计,让新增因子、求导、递归函数等需求都能以增量方式完成,充分体现了良好设计在扩展性与可维护性上的优势。
归一化处理更是让我受益匪浅,将各类表达式统一为标准多项式形式,极大简化了化简、合并与恒等判断,避免了大量冗余分支。同时我也深刻体会到,职责越单一的类和方法越不容易出 bug,复杂度过高、逻辑集中的模块则是问题高发区。
经过公测、强测与互测,我也树立了正确的测试意识,学会优先覆盖边界用例、针对性寻找设计漏洞。整体而言,这一单元不仅让我掌握了表达式处理与递归下降解析,更理解了分层、抽象、解耦的核心价值,为后续面向对象学习打下了重要基础。

