



302
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享架构设计在三次迭代中始终保持有三个低耦合工作模块:
1. 词法分析和语法分析:输入->有意义的抽象语法数据结构
2. 结果值的计算:语法结构->结果值
3. 打印输出:结果值->输出字符串
第一部分:词法和语法分析
词法分析将输入的字符流进行分割,提取出词元。
语法解析对词元流进行解析,形成存储着语义的语法数据结构树,主要采用递归下降的方法。
第二部分:结果值的计算
“值”表示由抽象的语法树中的元素计算得到的结果。
“值”的实现是树形结构的:
由于最简的结果一定是由c*x*y*exp()这样的项相加或相减组合而成,而不同的exp()不能合并(加减),x,y也是。因此构建树形结构,ExpItem,YItem,XItem分别表示不同的单元,等于对表达式如下表示:
( (2*x+3*x\^2)*y+(4*x^3-5*x^4)*y^2 ) * exp(1) + ( (6*x^5+7*x^6)*y^3+(8*x^7-9*x^8)*y^4 ) * exp(2)
对一第一层,XPolynomial:XItem是其单元(键),Coe是其系数(值)。对于更高一层Polynomial:YItem是其单元(键),而XPolynomial作为其系数(值)。同理再高一层Simplest:ExpItem是其单元(键),此时又Polynomial作为其系数(值)。
对于每一层来讲,其只需考虑其基本单元Item,和系数,而不需考虑这个系数究竟是什么,反正系数实现了加减乘除求导等一系列运算,就将其当成数即可。对于一层,应实现各种所需的运算,同时它也可以作为上一层的“系数”。
“值”对外部是线性的:
Simplest的public初始化方法采用Object[] {Coe, XItem, YItem, ExpItem}作为输入参数,相当于“展开”后的一项,同时其unpack方法可以将每一项拆开,返回List<Object[]>。这种方式方便了外部(如语法树计算,输出处理)的使用。
“值”实现了运算:
就像正真的数值一样,“值”实现了加减乘除求导等运算,当语法树计算值时,需使用这些运算。
“值”的产生由语法树的结构实现:
代表语法结构的对象都实现了Computable接口,该接口要求实现Simplest compute() 方法,使语法结构能够被计算出结果。具体计算时,采用自上而下计算的方法,例如计算Expression时先调用其包含的Term的compute()方法。
第三部分:打印输出
将“值”打印出来,注意指数因子的优化。
依据上面的综述,程序的主要结构如下
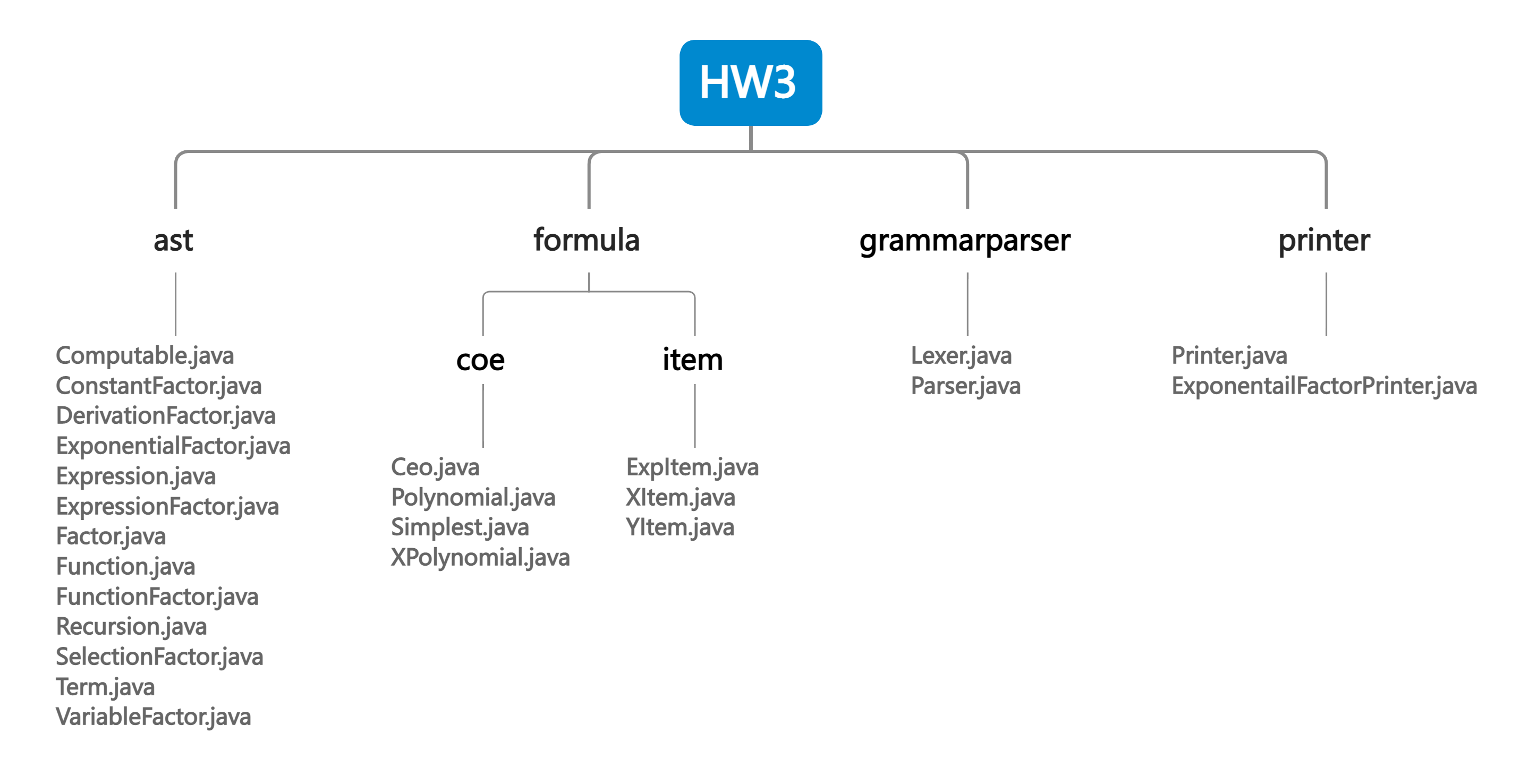
ast包里的类是代表语法结构的类,对应第一部分。
formula包的类是表示值的相关类。
| 类 | 属性个数 | 方法个数 | 类长度(行) |
| ConstantFactor | 1 | 4 | 32 |
| DerivationFactor | 2 | 4 | 24 |
| ExponentialFactor | 2 | 4 | 38 |
| Expression | 2 | 5 | 54 |
| ExpressionFactor | 2 | 4 | 22 |
| Factor | 0 | 2 | 11 |
| Function | 1 | 2 | 11 |
| FunctionFactor | 4 | 4 | 29 |
| Recursion | 6 | 2 | 39 |
| SelectionFactor | 4 | 4 | 32 |
| Term | 2 | 5 | 38 |
| VariableFactor | 2 | 4 | 34 |
| Coe | 3 | 17 | 66 |
| Polynomial | 3 | 16 | 167 |
| Simplest | 3 | 16 | 167 |
| XPolynomial | 3 | 16 | 167 |
| ExpItem | 2 | 7 | 40 |
| XItem | 2 | 7 | 49 |
| YItem | 2 | 7 | 50 |
| Lexer | 3 | 6 | 78 |
| Parser | 3 | 15 | 282 |
| Printer | 0 | 7 | 87 |
| ExponentailFactorPrinter | 9 | 13 | 31 |
在三次迭代中,对于语法分析模块,每次都加入了一些新的因子类和其对应的解析方法,总体方法不变,仅随着作业要求的增加而增加新的因子类型即可。
对于值的表示和计算模块:在迭代中加入新的“单元”,将之前的顶层值作为系数,而对值的运算方法均相同,不用做改变。对于值的计算:在新的因子语法结构中实现对应的compute接口即可。
若有新一次迭代,添加的新的语法结构,添加的新的值运算,均能依照前几次迭代同理进行。
长度优化主要集中在指数因子上:有exp((c*x))=exp(x)^c,exp((a+b))=exp((a))*exp((b))
假设exp(因子)中的因子为F,仅考虑F为表达式因子
若F中仅有一项,则若系数非1,将系数提到指数位置上。
若F不止一项:则需利用exp((a+b))=exp((a))*exp((b))对里面的项进行合理的拆分,然后对每一个拆分出的进行提公因数。
1. 先考虑对F不拆分时,应提出的公因子
*引理1:在十进制下,若b的位数为l,b整除a,则a/b相较于a所减少的位数为l或l-1。
此时若a的位数为m,若b*10^(m-l)>a,则减少的位数为l。*
若提出的公因子为t,t有l位,那么增加的字符为’^’和t,增加长度t+1。减少的字符长度可由引理1计算,注意当提出后系数变为一,则还可以减少”1*”两个字符。
先考虑t = gcd:设gcd位数为l,则减少的长度最小值为k*(l-1)(每一项都只减少l-1位,且没有提出后系数变为一的项)。
考虑少提一些t = gcd/m:若此时t的位数为l,则不会更好,因为t变小,减少的长度值是不增的;若此时t的位数为l-1,则减少的长度最大值为k*(l-1)(t比gcd小时,不可能有提出后系数变为一的项),若取等条件同时成立,则此时可比t = gcd时优化1位;t的位数更小时,一定更劣。
2. 考虑对F拆分
若拆分出的一项是非表达式因子,则可省去括号;
若拆分出的两项均有正项,则可省去一个+号;
设F中的表达式中项的集合为S。对于S的一个子集S0,由该子集形成的F0,有一个对应的长度值。问题变为找到S的一个划分,使子集长度和最小。可采用状态压缩DP进行求解。
3. 求解过程的优化
求gcd时寻找参数集合的两个最大的覆盖;并将求出的gcd存储;
求F0长度时,将已经求出的值存储。
时间优化主要集中在递推函数的计算上。
有两种方法:
1. 把f{n}()当成未知函数,先运用函数的运算计算出f{n}这个函数,再代入值。
2. 把f{n}()当成已知函数,直接代入参数值,在运算中逐层求值,不涉及函数的运算,只有值的运算。
对于第一种思路优化的方法为:惰性求值和记忆化:当需要f{n}时才计算这个函数,一旦计算出来便进行存储,方便复用。
在互测中被找到2个bug。
1. 在对指数因子输出的优化中超时
2. 指数因子的指数部分因子是指数因子时,指数拆开,形成表达式因子,但打印时少了一层括号
前者只能通过减小优化的项数的阈值来避免,后者加入一个条件检测即可。改动非常小,不会对复杂度造成影响。
编写程序时,要先设计好架构,一个好的架构不仅可读性好、易于理解,而且能避免很多bug的产生。好的设计条理清晰,依照设计将代码写完就不会有太多bug,即便有,由于模块设计合理,耦合度低,可以很快将bug定位。
如何高效的调试是一个很重要的问题。如何依据设计决策断点和合理的观测变量需要很多的思考。
希望可以提供一些可能用到的相关语法知识和易错点供参考

