


302
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享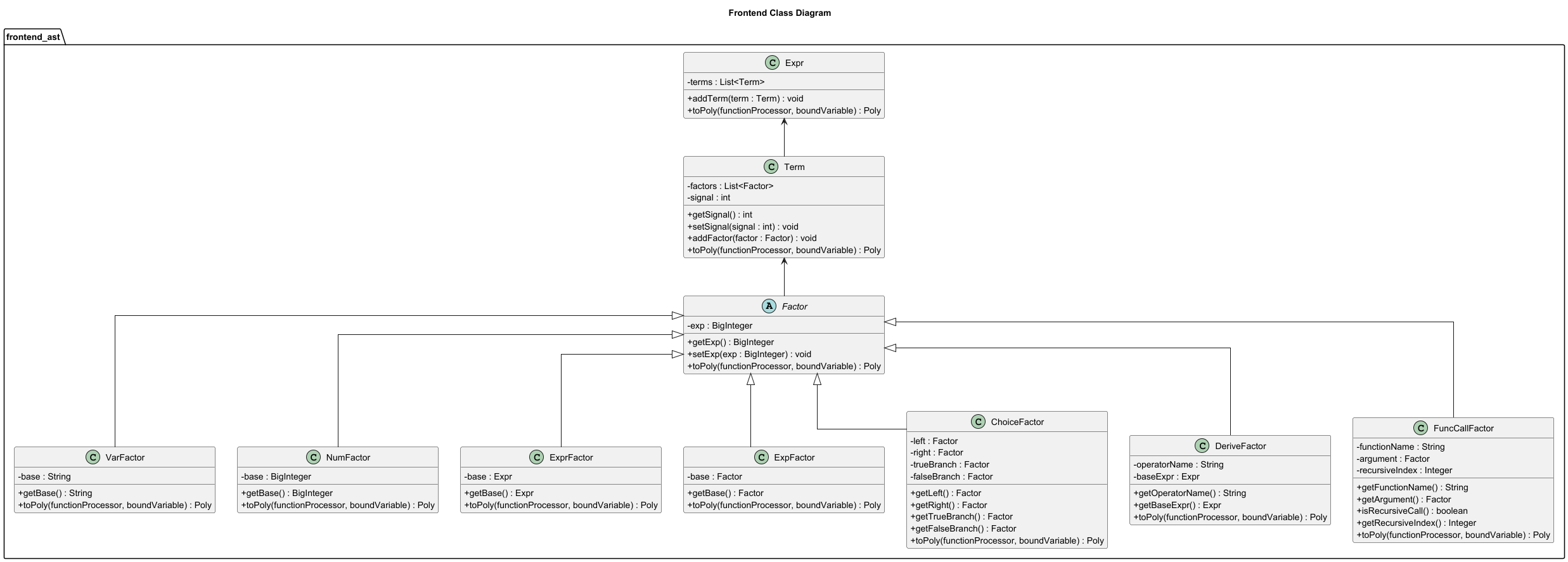

| 类名 | 主要属性 | 主要方法 |
|---|---|---|
MainClass | 无 | main(String[] args) |
Processor | expressionFormatter: ExpressionFormatter | process() |
| 类名 | 主要属性 | 主要方法 |
|---|---|---|
Preprocessor | 无 | preprocess(String input) |
ProgramInput | normalFunctionLines recursiveFunctionDefs expressionLine | getter 系列 |
| 类名 | 主要属性 | 主要方法 |
|---|---|---|
Parser | lexer: Lexer | parseExpr() parseNormalFunctionDefinition() parseFactor() |
Expr | terms: ArrayList<Term> | addTerm() toPoly(FunctionProcessor, Poly) |
Term | factors: ArrayList<Factor> signal: int | addFactor() toPoly(FunctionProcessor, Poly) |
FunctionDef | functionName parameterName body: Expr | getter 系列 |
RecursiveFunctionDef | baseZeroLine baseOneLine recurrenceLine | getter 系列 |
| 类名 | 主要属性 | 主要方法 |
|---|---|---|
Factor | exp: BigInteger | getExp() setExp() toPoly() |
NumFactor | base: BigInteger | toPoly(FunctionProcessor, Poly) |
VarFactor | base: String | toPoly(FunctionProcessor, Poly) |
ExprFactor | base: Expr | toPoly(FunctionProcessor, Poly) |
ExpFactor | base: Factor | toPoly(FunctionProcessor, Poly) |
FuncCallFactor | functionName argument recursiveIndex | toPoly(FunctionProcessor, Poly) |
ChoiceFactor | left/right/trueBranch/falseBranch | toPoly(FunctionProcessor, Poly) |
DeriveFactor | operatorName baseExpr | toPoly(FunctionProcessor, Poly) |
| 类名 | 主要属性 | 主要方法 |
|---|---|---|
Lexer | tokens: ArrayList<Token> index: int | getCur() next() |
Token | type: TokenType content: String | getType() getContent() |
TokenType | 无 | 词法枚举 |
| 类名 | 主要属性 | 主要方法 |
|---|---|---|
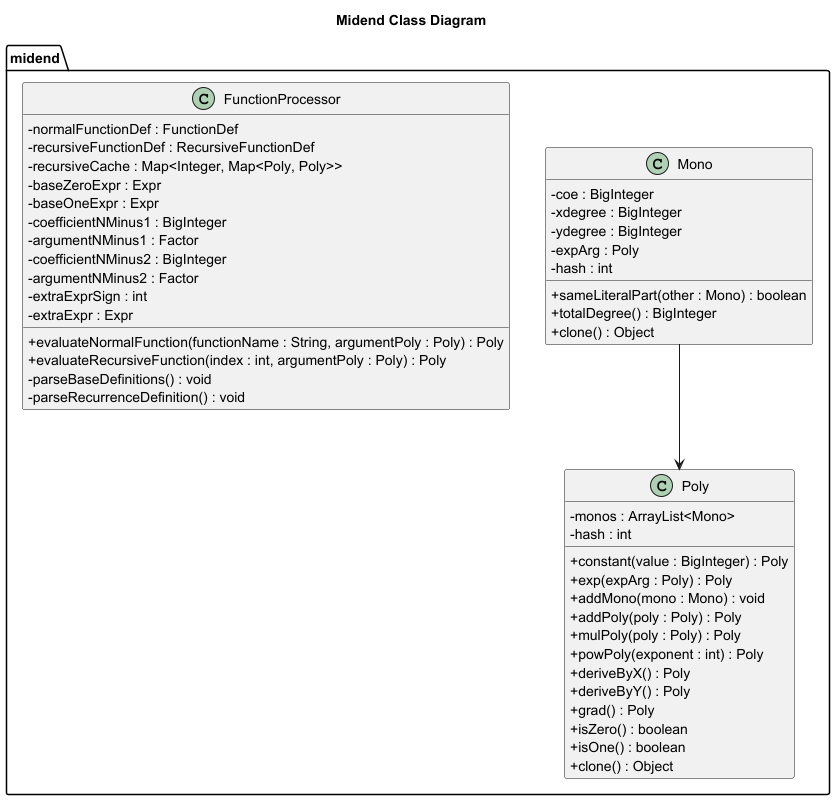
Poly | monos: ArrayList<Mono> hash: int | addMono() addPoly() mulPoly() powPoly() scale() deriveByX() deriveByY() grad() |
Mono | coe xExp yExp expArg | getter 系列 sameLiteralPart() clone() |
FunctionProcessor | normalFunctionDef recursiveFunctionDef recursiveCache | evaluateNormalFunction() evaluateRecursiveFunction() |
| 类名 | 主要属性 | 主要方法 |
|---|---|---|
ExpressionFormatter | 无 | format(Poly) formatExpArgumentOnly(Poly) |
| 类/模块 | 关系说明 |
|---|---|
Parser -> Lexer | Parser 从 Lexer 中读取 token 流 |
Expr -> Term | Expr 由多个 Term 组成 |
Term -> Factor | Term 由多个 Factor 组成 |
Factor -> 各具体因子子类 | 各具体因子统一继承 Factor |
FunctionDef -> Expr | 普通函数定义右部保存为 Expr |
RecursiveFunctionDef -> String | 递推函数定义先保留三行原始文本 |
Poly -> Mono | Poly 由规范化后的若干 Mono 组成 |
Mono -> Poly | Mono 通过 expArg 引用指数函数参数 |
FunctionProcessor -> FunctionDef/RecursiveFunctionDef | 函数处理器统一处理普通函数与递推函数 |
ExpressionFormatter -> Poly/Mono | backend 负责最终字符串输出 |
核心度量结果
复杂度最高的几个类如下:
| 类 | 字段 | 方法 | LOC | WMC | CBO(近似) | 结论 |
|---|---|---|---|---|---|---|
| ExpressionFormatter | 1 | 19 | 288 | 67 | 2 | 输出规则集中点,内聚高,但复杂度最高 |
| Poly | 2 | 28 | 281 | 60 | 1 | 中间表示核心类 |
| Lexer | 2 | 9 | 159 | 42 | 0 | 局部复杂度高,主要集中在分支识别 |
| Mono | 5 | 16 | 175 | 39 | 0 | 承担了部分格式化责任 |
| Parser | 1 | 17 | 208 | 37 | 14 | 负责构造 AST 数 |
| FunctionProcessor | 12 | 14 | 213 | 37 | 6 | 统一函数处理器,递推解析集中点 |
| Processor | 1 | 10 | 144 | 28 | 10 | 流程控制类 |
规模和分支最突出的几个方法:
我代码工作的主流程可以概括为:
Processor 读取 n 个普通函数定义、m 组递推函数定义和最终主表达式。Preprocessor 对所有输入行进行空白和连续正负号归一化。Parser 解析普通函数定义和主表达式,完成前端建树。FunctionProcessor 统一接收普通函数定义和递推函数定义,并在 midend 中承担函数调用处理。toPoly(FunctionProcessor, Poly) 递归求值为规范化的 Poly。Poly/Mono 负责代数运算、单项合并、偏导、递推展开后的结果表示。ExpressionFormatter 在 backend 中对最终 Poly 进行字符串格式化和显示级优化。输入 -> 预处理 -> 词法 -> 语法 -> AST -> midend 求值 -> backend 输出
我参考了 s7h 同学在博客中的架构设计,设计的总体流程按4步走,分别是:预输入处理 -> 语法解析 -> 合并项 -> 生成并输出字符串。
预处理模块到的功能是:
解析模块按照 parseExpr -> parseTerm -> parseFactor 建立。将 token 解析成 ast 语法树。
Expr ::= Term {( '+' | '-' ) Term}
Term ::= [ '+' | '-' ] Factor { '*' Factor }
Factor ::= NumFactor | VarFactor | ExprFactor
NumFactor ::= [ '+' | '-' ] NUMBER
VarFactor ::= VARIABLE [Exp]
ExprFactor ::= '(' Expr ')' [Exp]
Exp ::= '^' ['+'] NUMBER | ε
通过 ast 节点的 toPoly 方法,将 ast 数转化成展开中间表达式,并在构建的过程中,实现规范化和合并。
通过中间表达式的 toString 方法生成表达式并输出。
工程中使用 ExpFactor 表示指数函数因子。
Parser 遇到 exp( 时会建立 ExpFactor 节点;ExpFactor.toPoly() 先递归求内部因子得到 Poly;0 或外部指数为 0,则直接返回常数 1;Poly.exp(inner.scale(exp))。在中间表示层,Mono 用一个可空的 expArg 表示规范化后的指数函数参数。
对 f(实参) 求值时,逻辑上并不需要修改函数体本身的结构,而只需要在函数体求值时临时规定:
x = 实参对应的表达式值
然后再用这个绑定后的语义环境去求整个函数体。
因此:
exp(a)^n 会在 ExpFactor.toPoly() 中求值为 exp(n*a);exp(a) * exp(b) 会在 Poly.mulPoly() 的单项乘法中自动折叠为一个新的 expArg = a + b。选择式的抽象求值过程可以写成:
A 和 B 的结果;(A-B);0,则选择 C;D。工程中使用 ChoiceFactor 表示选择式因子。
Parser 在读到 [(A==B)?C:D] 时建立 ChoiceFactor 节点;ChoiceFactor.toPoly() 先分别调用 left.toPoly(context) 与 right.toPoly(context);difference = leftPoly.addPoly(rightPoly.negate());difference.isZero(),则返回真分支的 toPoly(context);toPoly(context)。本次迭代的核心目标,是在 Homework2 的表达式系统上继续扩展三个能力:
x 拓展到双变量 x/y。dx/dy/grad。f{n}(x)。在 Homework2 中,一个单项 mono 可以抽象为:
coe * x^a * exp(f)
而在 Homework3 中,一个单项 mono 应被抽象为:
coe * x^a * y^b * exp(f)
因此,除了拓展前端的 token 定义和 ast 节点属性,更主要的是在中间层的 poly 和 mono 的运算、展开以及合并的处理上,做出以下的改变。
Poly.addMono() 的合并条件从“x 指数和 expArg 一致”变成“xExp、yExp 与 expArg 同时一致”。Poly.mulPoly()、powPoly()、equals()、hashCode() 等基础代数运算全部围绕新的双变量结构重写。本次迭代中,求导功能的核心设计思想是:求导属于表达式的语义运算,而不是语法节点的行为。
因此,我的设计思路是:
Poly。Poly 进行偏导运算。这样,dx(E)、dy(E)、grad(E) 就都变成了对中间表达式的进一步运算,而不是在初始语法树进行直接改写。
普通函数 f(x) 可以看作“只有一层函数体、没有序号依赖”的特殊递推函数定义。所以我在实现上选择普通函数和地推函数共享同一个函数处理入口,都由函数处理器负责形参绑定和函数体求值,只是递推函数多了自定义递推模板处理和求值展开。
Homework1 未出现 bug。
Homework2 的 bug 主要在性能优化不足导致的超时上,在下方的优化分析部分统一分析。
Homework3 出现的bug如下:
+/- 单独拆出来,再把剩余部分整体取反,这将 -exp(x)^8+exp(x) 误解成 -(exp(x)^8+exp(x))。现在改成从正负符号开始把整段都按一个 Expr 解析,求值时直接加回去。exp((x*y)) 错打成 exp(x*y)。Homework1 能做的只有展开、合并以及正数提前这些减少字符串长度的优化,并未在性能上有太大开销。
而到了 Homework2 以及 Homework3 我的代码频繁触发超时,因此,我做出了以下优化:
在 Homework2 以及 Homework3 实现过程中,实际暴露出的性能 BUG,是中间表示对象复制过程中的重复深拷贝。
问题触发点来自深层嵌套普通函数,例如:
exp(exp(...))。在这种情况下,Poly.clone() 会递归触发 Mono.clone(),而 Mono 又可能持有深层 expArg。如果复制链条中对同一层 expArg 做了重复深拷贝,那么实际拷贝量会呈指数级放大。
下面为优化方式:
Mono.clone() 只保留一次必要拷贝。
