



302
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享ev(G)是基本复杂度,是用来衡量程序非结构化程度的,非结构成分降低了程序的质量,增加了代码的维护难度,使程序难于理解。因此,基本复杂度高意味着非结构化程度高,难以模块化和维护。实际上,消除了一个错误有时会引起其他的错误。
Iv(G)是模块设计复杂度,是用来衡量模块判定结构,即模块和其他模块的调用关系。软件模块设计复杂度高意味模块耦合度高,这将导致模块难于隔离、维护和复用。模块设计复杂度是从模块流程图中移去那些不包含调用子模块的判定和循环结构后得出的圈复杂度,因此模块设计复杂度不能大于圈复杂度,通常是远小于圈复杂度。
v(G)是圈复杂度,用来衡量一个模块判定结构的复杂程度,数量上表现为独立路径的条数,即合理的预防错误所需测试的最少路径条数,圈复杂度大说明程序代码可能质量低且难于测试和维护,经验表明,程序的可能错误和高的圈复杂度有着很大关系。
| Method | CogC | ev(G) | iv(G) | v(G) |
|---|---|---|---|---|
| BinOpNode.BinOpNode(Node, String, Node) | 0 | 1 | 1 | 1 |
| BinOpNode.evaluate() | 1 | $\color{red}{\text{5}}$ | 5 | 5 |
| BinOpNode.getLeft() | 0 | 1 | 1 | 1 |
| BinOpNode.getOp() | 0 | 1 | 1 | 1 |
| BinOpNode.getRight() | 0 | 1 | 1 | 1 |
| FuncNode.FuncNode(Node, Poly) | 0 | 1 | 1 | 1 |
| FuncNode.evaluate() | 0 | 1 | 1 | 1 |
| FunctionManager.containsFunction(String) | 0 | 1 | 1 | 1 |
| FunctionManager.containsRecursiveFunction(String) | 0 | 1 | 1 | 1 |
| FunctionManager.getFunction(String) | 0 | 1 | 1 | 1 |
| FunctionManager.getRecursiveFunction(String, int) | 0 | 1 | 1 | 1 |
| FunctionManager.putFunction(String, Poly) | 0 | 1 | 1 | 1 |
| FunctionManager.putRecursiveFunction(String, RecursiveFunc) | 0 | 1 | 1 | 1 |
| FunctionParser.FunctionDefinition.FunctionDefinition(String, Poly) | 0 | 1 | 1 | 1 |
| FunctionParser.FunctionDefinition.getName() | 0 | 1 | 1 | 1 |
| FunctionParser.FunctionDefinition.getValue() | 0 | 1 | 1 | 1 |
| FunctionParser.FunctionParser(FunctionManager) | 0 | 1 | 1 | 1 |
| FunctionParser.ParsedHead.ParsedHead(String, String) | 0 | 1 | 1 | 1 |
| FunctionParser.RecursiveFunctionDefinition.RecursiveFunctionDefinition(String, RecursiveFunc) | 0 | 1 | 1 | 1 |
| FunctionParser.RecursiveFunctionDefinition.getName() | 0 | 1 | 1 | 1 |
| FunctionParser.RecursiveFunctionDefinition.getValue() | 0 | 1 | 1 | 1 |
| FunctionParser.materializeRecursiveIndices(String, int) | 3 | 1 | 3 | 3 |
| FunctionParser.parseFunction(String) | 0 | 1 | 1 | 1 |
| FunctionParser.parseHead(String) | 0 | 1 | 1 | 1 |
| FunctionParser.parseRecursiveFunction(String[]) | 12 | $\color{red}{\text{4}}$ | 3 | 7 |
| Lexer.Lexer(String) | 0 | 1 | 1 | 1 |
| Lexer.getNumber() | 2 | 1 | 3 | 3 |
| Lexer.getString() | 2 | 1 | 3 | 3 |
| Lexer.next() | 7 | 3 | 4 | 7 |
| Lexer.peek() | 0 | 1 | 1 | 1 |
| Lexer.peekNext() | 0 | 1 | 1 | 1 |
| Lexer.readTokenAt(int) | 11 | $\color{red}{\text{4}}$ | 6 | 10 |
| Main.main(String[]) | 2 | 1 | 3 | 3 |
| NumberNode.NumberNode(Poly) | 0 | 1 | 1 | 1 |
| NumberNode.evaluate() | 0 | 1 | 1 | 1 |
| NumberNode.getValue() | 0 | 1 | 1 | 1 |
| Parser.Parser(Lexer, FunctionManager) | 0 | 1 | 1 | 1 |
| Parser.expect(String) | 1 | 2 | 2 | 2 |
| Parser.parseAtom() | 3 | 1 | 3 | 3 |
| Parser.parseExpression() | 2 | 1 | 3 | 3 |
| Parser.parseFactor() | 8 | $\color{red}{\text{8}}$ | $\color{red}{\text{9}}$ | 9 |
| Parser.parseFunctionCall(String) | 0 | 1 | 1 | 1 |
| Parser.parseParenthesizedExpression() | 0 | 1 | 1 | 1 |
| Parser.parsePower() | 1 | 1 | 2 | 2 |
| Parser.parseRecursiveFunctionCall(String) | 0 | 1 | 1 | 1 |
| Parser.parseTerOp() | 0 | 1 | 1 | 1 |
| Parser.parseTerm() | 1 | 1 | 2 | 2 |
| Parser.parseUnary() | 3 | 2 | 3 | 3 |
| Parser.parseUnaryFunctionCall(String) | 0 | 1 | 1 | 1 |
| Poly.Poly() | 0 | 1 | 1 | 1 |
| Poly.Poly(int) | 0 | 1 | 1 | 1 |
| Poly.add(Poly) | 0 | 1 | 1 | 1 |
| Poly.addTerm(TermKey, BigInteger) | 3 | 2 | 1 | 3 |
| Poly.appendAllTerms(StringBuilder, List<Entry<TermKey, BigInteger>>, int) | 4 | 3 | 3 | 4 |
| Poly.appendExpPart(StringBuilder, Poly) | 0 | 1 | 1 | 1 |
| Poly.appendTerm(StringBuilder, Entry<TermKey, BigInteger>, boolean) | 7 | 2 | 7 | 9 |
| Poly.appendVariable(StringBuilder, String, BigInteger) | 1 | 1 | 2 | 2 |
| Poly.appendVariablePart(StringBuilder, TreeMap<String, Variable>, boolean, boolean, boolean) | 7 | 1 | 5 | 6 |
| Poly.compareTermEntries(Entry<TermKey, BigInteger>, Entry<TermKey, BigInteger>) | 2 | 3 | 1 | 3 |
| Poly.compareVariableExponent(Entry<TermKey, BigInteger>, Entry<TermKey, BigInteger>, String) | 4 | $\color{red}{\text{4}}$ | 2 | 5 |
| Poly.computeExpInsideGcd(Poly) | 3 | 3 | 2 | 3 |
| Poly.derivative(String) | $\color{red}{\text{18}}$ | 1 | 7 | 7 |
| Poly.divideExpInside(Poly, BigInteger) | 1 | 1 | 2 | 2 |
| Poly.equals(Object) | 2 | 3 | 1 | 3 |
| Poly.findFirstPositiveIndex(List<Entry<TermKey, BigInteger>>) | 3 | 3 | 2 | 3 |
| Poly.getSortedEntries() | 0 | 1 | 1 | 1 |
| Poly.getTerms() | 0 | 1 | 1 | 1 |
| Poly.grad() | 0 | 1 | 1 | 1 |
| Poly.hashCode() | 0 | 1 | 1 | 1 |
| Poly.isComplex() | 8 | $\color{red}{\text{5}}$ | 4 | 8 |
| Poly.isZero() | 0 | 1 | 1 | 1 |
| Poly.mul(Poly) | 0 | 1 | 1 | 1 |
| Poly.pow(BigInteger) | 8 | $\color{red}{\text{4}}$ | 5 | 7 |
| Poly.pow(int) | 8 | $\color{red}{\text{4}}$ | 5 | 7 |
| Poly.renderExpLiteral(Poly) | 2 | 2 | 1 | 2 |
| Poly.renderExpOptimized(Poly) | 5 | 1 | 3 | 5 |
| Poly.renderGroupedExp(Poly) | 7 | 2 | 5 | 6 |
| Poly.sub(Poly) | 0 | 1 | 1 | 1 |
| Poly.substitute(Poly) | 5 | 1 | 4 | 4 |
| Poly.toString() | 2 | 3 | 1 | 3 |
| RecursiveFunc.RecursiveFunc(RecursiveFuncStructure) | 0 | 1 | 1 | 1 |
| RecursiveFunc.getFunction(int) | 1 | 2 | 2 | 2 |
| RecursiveFuncStructure.RecursiveFuncStructure(RuleBuilder) | 0 | 1 | 1 | 1 |
| RecursiveFuncStructure.getRoot(int, RecursiveFunc) | 0 | 1 | 1 | 1 |
| TerOpNode.TerOpNode(Node[], String) | 0 | 1 | 1 | 1 |
| TerOpNode.evaluate() | 3 | 2 | 3 | 3 |
| TerOpNode.getSon(int) | 0 | 1 | 1 | 1 |
| TermKey.addVariable(Variable) | 0 | 1 | 1 | 1 |
| TermKey.equals(Object) | 4 | 3 | 3 | 5 |
| TermKey.getExpInside() | 0 | 1 | 1 | 1 |
| TermKey.getVariables() | 0 | 1 | 1 | 1 |
| TermKey.hashCode() | 0 | 1 | 1 | 1 |
| TermKey.mul(TermKey) | 0 | 1 | 1 | 1 |
| TermKey.pow(BigInteger) | 0 | 1 | 1 | 1 |
| TermKey.setExpInside(Poly) | 0 | 1 | 1 | 1 |
| TermKey.toString() | 6 | 1 | 5 | 5 |
| TermKey.valueOf(Poly) | 0 | 1 | 1 | 1 |
| TermKey.valueOf(String) | 0 | 1 | 1 | 1 |
| UnaryOpNode.UnaryOpNode(String, Node) | 0 | 1 | 1 | 1 |
| UnaryOpNode.evaluate() | 4 | 1 | 2 | 6 |
| UnaryOpNode.getExpr() | 0 | 1 | 1 | 1 |
| UnaryOpNode.getOp() | 0 | 1 | 1 | 1 |
| Variable.Variable(BigInteger, String) | 0 | 1 | 1 | 1 |
| Variable.equals(Object) | 4 | 3 | 3 | 5 |
| Variable.getVariableName() | 0 | 1 | 1 | 1 |
| Variable.getXexp() | 0 | 1 | 1 | 1 |
| Variable.hashCode() | 0 | 1 | 1 | 1 |
| Variable.mul(Variable) | 1 | 2 | 1 | 2 |
| Variable.pow(BigInteger) | 0 | 1 | 1 | 1 |
| Variable.toString() | 0 | 1 | 1 | 1 |
Parser Lexer 内部方法复杂度高符合期望,且改进空间小,因为通常这部分代码不会过多的修改
但是值得注意的一点是 Poly.derivative 的设计较差,没有较好的分离逻辑(这是因为 Poly 设计有一定的问题,没有很好的分层结构)
有很多代码的 ev(G) 较高,这类问题会增加维护负担,值得注意
OCavg Average Operation Complexity (平均操作复杂度)类中所有方法的平均复杂度,即 $WMC \div 方法数量$。它反映了该类方法的平均逻辑密集度。
OCmax Maximum Operation Complexity (最大操作复杂度)类中逻辑最复杂(分支最多)的那个方法的复杂度分值。
WMC Weighted Methods per Class (类加权方法数)该类中所有方法的复杂度(通常指循环复杂度)之和。它代表了维护该类所需的总体工作量。
| Class | OCavg | OCmax | WMC |
|---|---|---|---|
| BinOpNode | 2.00 | 6 | 10 |
| FuncNode | 1.00 | 1 | 2 |
| FunctionManager | 1.00 | 1 | 6 |
| FunctionParser | 2.60 | 3 | 13 |
| FunctionParser.FunctionDefinition | 1.00 | 1 | 3 |
| FunctionParser.ParsedHead | 1.00 | 1 | 1 |
| FunctionParser.RecursiveFunctionDefinition | 1.00 | 1 | 3 |
| Lexer | 2.86 | 7 | 20 |
| Main | 3.00 | 3 | 3 |
| NumberNode | 1.00 | 1 | 3 |
| Parser | 2.08 | 8 | 27 |
| Poly | $\color{red}{\text{3.03}}$ | 7 | $\color{red}{\text{94}}$ |
| RecursiveFunc | 1.50 | 2 | 3 |
| RecursiveFuncStructure | 1.00 | 1 | 2 |
| TerOpNode | 2.00 | 4 | 6 |
| TermKey | 1.45 | 4 | 16 |
| UnaryOpNode | 2.50 | 7 | 10 |
| Variable | 1.38 | 3 | 11 |
Poly 类经过多次重构,在设计上有很严重的问题,逻辑链条过长,没有很好的分离
接下来在架构设计体验中会详细说明 Poly 的设计以及我是如何给自己挖了一个巨大的天坑的
总的来说,多项式计算和自定义函数属于耦合较高的代码,维护起来相当麻烦
我比较喜欢的是AST树的设计,代码维护简单,结构清晰
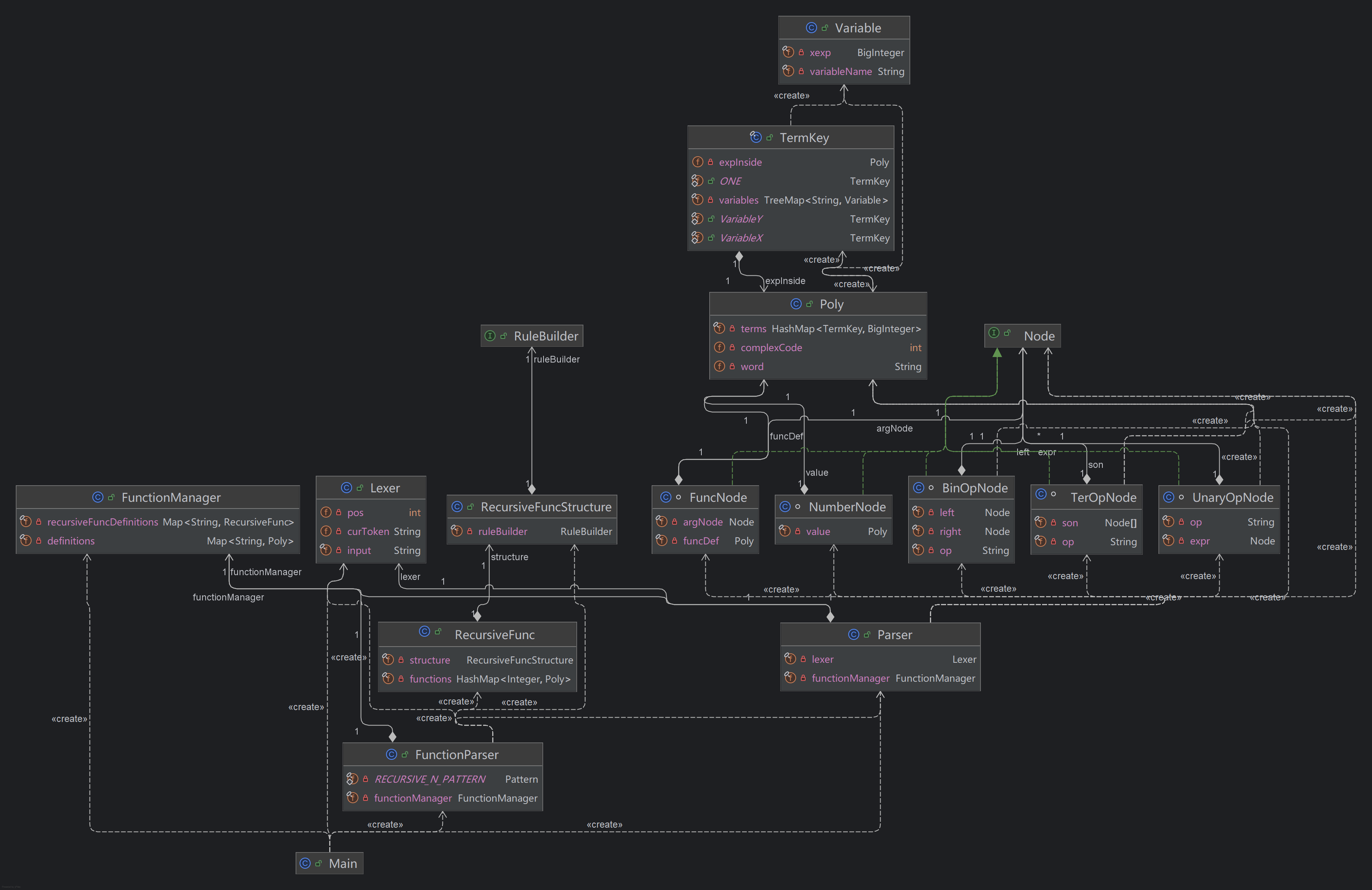
通过观察类图我们发现, AST 树的部分基本遵循高内聚低耦合的性质。但是 Poly 类内部方法太复杂,应当分离对象。Function 的类大致为一个独立整体。
题外话:发现博客应当每周写点,不然写这部分会忘掉当初的思路
第一次作业主要难度在表达式的解析,于是我设计了 Poly 类用于计算,设计了 Node 接口用于实现不同种类的 AST 语法树节点,设计了 Parser 和 Lexer 用于解析。
其中 Node、Parser 和 Lexer 一直用到最后,但是 Poly 在后续进行了 2 次重构。
原因是设计 Poly 时偷懒,并没有抽象出合理的结构,导致每次增加新功能需要对这个类所有代码修改。
这次加入的选择式因子和函数并没有费太多的力气,因为 Node 高度抽象,我可以很轻松的组建不同的计算节点。
但是 exp 的加入使得我开始时设计的 HashMap<Integer, BigInteger> 跟不上时代,其实当时就应该抽象出 Term 。
于是我换成了 HashMap<TermKey, BigInteger> 进行管理,这种改变相当麻烦,因为我一开始没有抽象出 GetExponent 这样的接口。
都是直接对 HashMap 查询的。导致涉及到查询的地方代码都要更改。
但是我的 TermKey 由于设计不够优雅导致后面加入多个变量时又有很多麻烦。
这次加入的递推函数设计起来我感到有点吃力,因为我希望代码能够在递推层数足够多的时候或者表达式足够复杂的时候都能保证高效性。不过最终引入了结构接口和新的 FunctionParser 使得问题得到解决。扩展变量导致对 TermKey 进行了一定的修改,同时我模仿 BigInteger 的代码修改了各个类的构造函数使得其他地方用到构造函数的时候能够更加方便。扩展计算就是新增了一种计算节点。总之这次迭代还算比较轻松。
从这几次迭代来看,每次重构引起的麻烦都是没有设计好 Getter 和 Setter 导致的,出现了跨级管理内部数据的情况,使得重构代码不能限制在小的范围内。应当引起注意。
只有一个 BUG 就是被人卡了提取公因式的优化
代码中有两个方法会互相调用,经过多层 exp 嵌套将会形成庞大的搜索树
其实交之前发现了,但是没来得及加缓存并且有侥幸心理以为不会出事(
这个 BUG 很好找,你只需要随便搞个边界数据,然后使用 Profile 分析,看火焰图或者调用树就能发现异常
出现 BUG 的代码往往是在代码迭代的时候加入的代码,因为会更加缺少全局的考虑。而且直接塞到原来方法的代码风险更高,因为会更难进行 Junit 测试。
首先盲测一些有概率出错的数据,例如
// 卡没去符号的
0
0
exp(x)^+02
// 卡选择式短路和字符串替换展开
1
f(x)=exp(exp(exp(exp(exp(exp(x)^2)^2)^2)^2)^2)^3
0
[x==x?0:f(f(f(f(f(f(f(f(f(f(f(f(f(f(x))))))))))))))]
// 卡提取公因式优化
1
f(x)=exp(exp(exp(exp(exp(exp(x)^2)^2)^2)^2)^2)^3
0
f(f(f(f(x))))
然后再针对代码检查
在这次作业中主要检查 Parser 和 Poly.toString()
比如我就卡掉了一个在 $n$ 较小的时候进行 dp 优化的,但是他的复杂度为 $2^n$,嵌套两层他就爆炸了
0
0
(1+x+x^2+x^3+x^4+x^5+x^6+x^7+x^8+y+y^2)*exp((x+x^2+x^3+x^4+x^5+x^6+x^7+x^8+y+y^2+y^3+y^4+y^5+y^6))
有很多人的代码没人叉成功可能是因为没有细看
所以针对代码检查是有必要的,同时构造样例可以使用 AI 帮助,虽然 AI 不见得能发现这些位置的 BUG ,但是经过提醒就可以快速构造合法且针对的高强度样例。
HW2 中对输出做了优化,简单提取公因式优化输出长度
HW2 BUG 修复对程序性能做了优化,加入了缓存。
HW3 对输出做了优化,加入分组公因式优化输出长度。
可以保证简洁性和正确性,因为原本设计中遵循了低耦合的原则,在优化的过程中仅仅改变了一些方法的内部实现,优化仅仅需要测试更改的方法即可。
使用大模型辅助了 FuncManager 的架构,这部分业务需求实在是有点混乱邪恶。
性能优化上,AI 能够提出一些小巧思,感觉让 AI 设计搜索的估价函数会很有说法,不过我没尝试,实在是不放心 AI 代码的运行效率。
使用了大模型进行代码的检查,结果差强人意,能够看出一些明显的错误:查出来了一个 exp(x*y) 的错误,根据互测中大模型的表现,我认为大模型在该题目中检查代码有一定的局限性。
评测机搭建非常完美,几分钟搞出来一个带测试数据合法性用 numpy 检查结果的评测机。(不过用 numpy 有点变态了)在批量测试中有很大的帮助。
本次作业感觉做的有点糙了(
在 HW1 中本来想要第一次编写代码时就加入对多变量的支持,还有 Poly 类的扩展性,由于时间紧张就没加入,结果在后续的作业吃了很多亏,基本上每次代码都需要进行或大或小规模的重构。
可以发现一个好的框架是好的作业的基础。
不过由于笔者代码底子尚可,代码基本都是一边过,强测也没出过问题,仅仅在 HW2 因为程序性能被叉了一次。
但正是一边过让我在互测阶段很难拿到一些易错的样本进行批量测试,笔者基本上都是对着代码设计的叉人数据(好费时间)。以至于在互测阶段总是对着某个 **星上来交了一发 Hack 一穿四百思不得其解。
互测非常有趣味,但是太费时间,本人也没看太多。不过让 AI 帮忙看代码基本都看不出问题,还得手搓。
以后可以在设计的时候就想好可能会出现的问题来方便进行互叉。
一个比较好的互测流程:
conclusion: CAS 是一个不错的课题,我认为目前的题目过于简单,对一些方面的涉及有些过于浅显,可以多加一点东西。
toString 的设计上,我认为 toString 其实是本单元不太优雅的地方,性能分的要求是输出字符串最短,这个东西的性质太少,且与多项式本身相关性太差,我认为性能值部分应当重新设计,应当给出标准的 AST 树构建方法,并设计性能值为一些树上和 如点权和、size ,这样设计的性能值我认为会更加优雅。Poly)如何检查输入是否符合要求?包括空格,连续符号等。
严格按照文法做递归下降即可
如何精准计算一个合法输入的Cost?
可以发现此题中的 Cost 计算和原本的符号计算差不多,只需要更改 AST 树节点中 Interface 内的 evaluate 方法支持 Cost 计算即可。
搞了个 GoLang 的
package main
import (
"bufio"
"fmt"
"math"
"os"
"strconv"
"strings"
"unicode"
)
const CostLimit = 5000
func sAdd(a, b int) int {
if a >= CostLimit || b >= CostLimit || a+b >= CostLimit {
return CostLimit + 1
}
return a + b
}
func sMul(a, b int) int {
if a == 0 || b == 0 {
return 0
}
if a >= CostLimit || b >= CostLimit || a*b >= CostLimit {
return CostLimit + 1
}
return a * b
}
func sPow(base, exp int) int {
if exp == 0 {
return 1
}
if base >= CostLimit {
return CostLimit + 1
}
res := math.Pow(float64(base), float64(exp))
if res >= float64(CostLimit) {
return CostLimit + 1
}
return int(res)
}
type TermKey struct{ X, Y int }
type Poly map[TermKey]int64
func NewPoly() Poly { return make(Poly) }
func (p Poly) Add(q Poly) Poly {
res := NewPoly()
for k, v := range p {
res[k] += v
}
for k, v := range q {
res[k] += v
}
return res
}
func (p Poly) Mul(q Poly) Poly {
res := NewPoly()
for k1, v1 := range p {
for k2, v2 := range q {
res[TermKey{k1.X + k2.X, k1.Y + k2.Y}] += v1 * v2
}
}
return res
}
func (p Poly) Equals(q Poly) bool {
p1, q1 := NewPoly(), NewPoly()
for k, v := range p {
if v != 0 {
p1[k] = v
}
}
for k, v := range q {
if v != 0 {
q1[k] = v
}
}
if len(p1) != len(q1) {
return false
}
for k, v := range p1 {
if q1[k] != v {
return false
}
}
return true
}
type Node interface {
Cost() int
EvalPoly() Poly
String() string
Substitute(repl Node) Node
}
type VarNode struct{ Name string }
func (n *VarNode) Cost() int { return 1 }
func (n *VarNode) EvalPoly() Poly {
p := NewPoly()
if n.Name == "x" {
p[TermKey{1, 0}] = 1
} else {
p[TermKey{0, 1}] = 1
}
return p
}
func (n *VarNode) String() string { return n.Name }
func (n *VarNode) Substitute(repl Node) Node {
if n.Name == "x" {
return repl
}
return n
}
type NumNode struct {
Raw string
Val int64
}
func (n *NumNode) Cost() int {
s := strings.TrimLeft(n.Raw, "0")
if s == "" {
return 1
}
return len(s)
}
func (n *NumNode) EvalPoly() Poly {
p := NewPoly()
p[TermKey{0, 0}] = n.Val
return p
}
func (n *NumNode) String() string { return n.Raw }
func (n *NumNode) Substitute(repl Node) Node { return n }
type BinNode struct {
Op string
L, R Node
}
func (n *BinNode) Cost() int {
if n.Op == "*" {
return sMul(n.L.Cost(), n.R.Cost())
}
return sAdd(n.L.Cost(), n.R.Cost())
}
func (n *BinNode) EvalPoly() Poly {
if n.Op == "+" {
return n.L.EvalPoly().Add(n.R.EvalPoly())
}
if n.Op == "-" {
neg := n.R.EvalPoly()
for k := range neg {
neg[k] *= -1
}
return n.L.EvalPoly().Add(neg)
}
return n.L.EvalPoly().Mul(n.R.EvalPoly())
}
func (n *BinNode) String() string { return fmt.Sprintf("(%s%s%s)", n.L, n.Op, n.R) }
func (n *BinNode) Substitute(repl Node) Node {
return &BinNode{n.Op, n.L.Substitute(repl), n.R.Substitute(repl)}
}
type PowNode struct {
Base Node
Exp int
}
func (n *PowNode) Cost() int {
if _, isVar := n.Base.(*VarNode); isVar {
return 1
}
if _, isExp := n.Base.(*ExpNode); isExp {
return sAdd(sPow(2, n.Exp), n.Base.Cost())
}
return sPow(max(n.Base.Cost(), 2), max(n.Exp, 1))
}
func (n *PowNode) EvalPoly() Poly {
res := NewPoly()
res[TermKey{0, 0}] = 1
base := n.Base.EvalPoly()
for i := 0; i < n.Exp; i++ {
res = res.Mul(base)
}
return res
}
func (n *PowNode) String() string { return fmt.Sprintf("%s^%d", n.Base, n.Exp) }
func (n *PowNode) Substitute(repl Node) Node { return &PowNode{n.Base.Substitute(repl), n.Exp} }
type ExpNode struct{ Inner Node }
func (n *ExpNode) Cost() int { return sAdd(n.Inner.Cost(), 1) }
func (n *ExpNode) EvalPoly() Poly { return NewPoly() }
func (n *ExpNode) String() string { return fmt.Sprintf("exp(%s)", n.Inner) }
func (n *ExpNode) Substitute(repl Node) Node { return &ExpNode{n.Inner.Substitute(repl)} }
type SelectNode struct{ A, B, C, D Node }
func (n *SelectNode) Cost() int {
var choose int
if n.A.EvalPoly().Equals(n.B.EvalPoly()) {
choose = n.C.Cost()
} else {
choose = n.D.Cost()
}
return sAdd(sAdd(n.A.Cost(), n.B.Cost()), sAdd(choose, 5))
}
func (n *SelectNode) EvalPoly() Poly {
if n.A.EvalPoly().Equals(n.B.EvalPoly()) {
return n.C.EvalPoly()
}
return n.D.EvalPoly()
}
func (n *SelectNode) String() string { return fmt.Sprintf("[(%s==%s)?%s:%s]", n.A, n.B, n.C, n.D) }
func (n *SelectNode) Substitute(repl Node) Node {
return &SelectNode{n.A.Substitute(repl), n.B.Substitute(repl), n.C.Substitute(repl), n.D.Substitute(repl)}
}
var funcTable = make(map[string]Node)
type FuncCallNode struct {
Name string
Arg Node
}
func (n *FuncCallNode) Cost() int {
def, ok := funcTable[n.Name]
if !ok {
return CostLimit + 1
}
if n.Arg.Cost() > 500 {
return CostLimit + 1
}
return sAdd(sAdd(n.Arg.Cost(), sMul(def.Substitute(n.Arg).Cost(), 2)), 5)
}
func (n *FuncCallNode) EvalPoly() Poly { return NewPoly() }
func (n *FuncCallNode) String() string { return fmt.Sprintf("%s(%s)", n.Name, n.Arg) }
func (n *FuncCallNode) Substitute(repl Node) Node {
return &FuncCallNode{n.Name, n.Arg.Substitute(repl)}
}
type Parser struct {
tokens []string
pos int
}
func (p *Parser) parseExpr() Node {
var node Node
sign := 1
if p.peek() == "+" || p.peek() == "-" {
if p.next() == "-" {
sign = -1
}
}
node = p.parseTerm()
if sign == -1 {
node = &BinNode{"-", &NumNode{"0", 0}, node}
}
for p.peek() == "+" || p.peek() == "-" {
op := p.next()
node = &BinNode{op, node, p.parseTerm()}
}
return node
}
func (p *Parser) parseTerm() Node {
var node Node
sign := 1
if p.peek() == "+" || p.peek() == "-" {
if p.next() == "-" {
sign = -1
}
}
node = p.parseFactor()
if sign == -1 {
node = &BinNode{"-", &NumNode{"0", 0}, node}
}
for p.peek() == "*" {
p.next()
node = &BinNode{"*", node, p.parseFactor()}
}
return node
}
func (p *Parser) parseFactor() Node {
var node Node
curr := p.next()
if curr == "" {
panic("Unexpected EOF")
}
switch {
case curr == "x" || curr == "y":
node = &VarNode{curr}
case unicode.IsDigit(rune(curr[len(curr)-1])):
v, _ := strconv.ParseInt(curr, 10, 64)
node = &NumNode{curr, v}
case curr == "(":
node = p.parseExpr()
p.expect(")")
case curr == "exp":
p.expect("(")
node = &ExpNode{p.parseFactor()}
p.expect(")")
case curr == "[":
p.expect("(")
a := p.parseExpr()
p.expect("==")
b := p.parseExpr()
p.expect(")")
p.expect("?")
c := p.parseFactor()
p.expect(":")
d := p.parseFactor()
p.expect("]")
node = &SelectNode{a, b, c, d}
case curr == "f":
name := "f"
if p.peek() == "{" {
p.next()
name = "f" + p.next()
p.expect("}")
}
p.expect("(")
arg := p.parseFactor()
p.expect(")")
node = &FuncCallNode{name, arg}
default:
panic("Invalid Factor at: " + curr)
}
if p.peek() == "^" {
p.next()
if p.peek() == "+" {
p.next()
}
e, _ := strconv.Atoi(p.next())
node = &PowNode{node, e}
}
return node
}
func (p *Parser) expect(s string) {
if p.next() != s {
panic("Expected " + s + " but got something else")
}
}
func (p *Parser) peek() string {
if p.pos < len(p.tokens) {
return p.tokens[p.pos]
}
return ""
}
func (p *Parser) next() string {
r := p.peek()
p.pos++
return r
}
func tokenize(s string) []string {
s = strings.ReplaceAll(s, " ", "")
s = strings.ReplaceAll(s, "\t", "")
ops := []string{"==", "exp", "f", "{", "}", "(", ")", "[", "]", "?", ":", "^", "*", "+", "-"}
for _, op := range ops {
s = strings.ReplaceAll(s, op, " "+op+" ")
}
return strings.Fields(s)
}
func max(a, b int) int {
if a > b {
return a
}
return b
}
func main() {
scanner := bufio.NewScanner(os.Stdin)
scanner.Scan()
n, _ := strconv.Atoi(scanner.Text())
for i := 0; i < n; i++ {
scanner.Scan()
line := scanner.Text()
parts := strings.Split(line, "=")
funcTable["f"] = (&Parser{tokens: tokenize(parts[1])}).parseExpr()
}
scanner.Scan()
m, _ := strconv.Atoi(scanner.Text())
for i := 0; i < 3*m; i++ {
scanner.Scan()
line := scanner.Text()
fName := "f" + line[strings.Index(line, "{")+1:strings.Index(line, "}")]
funcTable[fName] = (&Parser{tokens: tokenize(line[strings.Index(line, "=")+1:])}).parseExpr()
}
scanner.Scan()
exprStr := scanner.Text()
defer func() {
if r := recover(); r != nil {
fmt.Printf("\n>>> [REJECT] 文法不合规: %v\n", r)
}
}()
p := &Parser{tokens: tokenize(exprStr)}
ast := p.parseExpr()
cost := ast.Cost()
clean := strings.ReplaceAll(strings.ReplaceAll(exprStr, " ", ""), "\t", "")
fmt.Printf("\n--- 校验结果 ---\n")
fmt.Printf("解析结果: %s\n", ast.String())
fmt.Printf("有效长度: %d / 100\n", len(clean))
fmt.Printf("计算代价: %d / 5000\n", cost)
if len(clean) <= 100 && cost <= 5000 {
fmt.Println(">>> [SUCCESS] 数据合法")
} else {
fmt.Println(">>> [FAIL] 数据超标")
}
}

