


302
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享在这三次作业中,我的代码架构发生了颠覆性的变化。以下分别对三次作业的代码规模与复杂度进行度量分析。
HashMap<Integer, BigInteger> 进行单变量多项式的运算,没有引入真正的词法与语法分析,且没有使用真正的 Lexer,解析强依赖于 String.substring。
| 类名 | 属性个数 | 方法个数 | 平均方法规模(LOC) | 最大控制分支数 $v(G)$ (对应方法) | 类总行数 |
|---|---|---|---|---|---|
MainClass | 0 | 1 | 5 行 | 1 (main) | 10 行 |
Operator | 0 | 5 | 11 行 | 4 (mutiply) | 55 行 |
Parser | 1 | 9 | 24 行 | 18 (processSigns) | 220 行 |
1. 类的内聚性
Operator (高内聚)**:这是我第一次作业中最具“面向对象”思维的类。它将多项式严格抽象为 HashMap<Integer, BigInteger>,所有的方法(plus, minus, mutiply, power)都严格围绕这个数据结构进行纯代数运算,没有任何越界操作。Parser (低内聚)**:内聚性较差。它承担了太多本不属于它的职责:removeWhitespace, processSigns 等逻辑)。substring 强行分割 Expr, Term, Factor)。solve 方法负责极其复杂的打印逻辑)。2. 类的耦合度
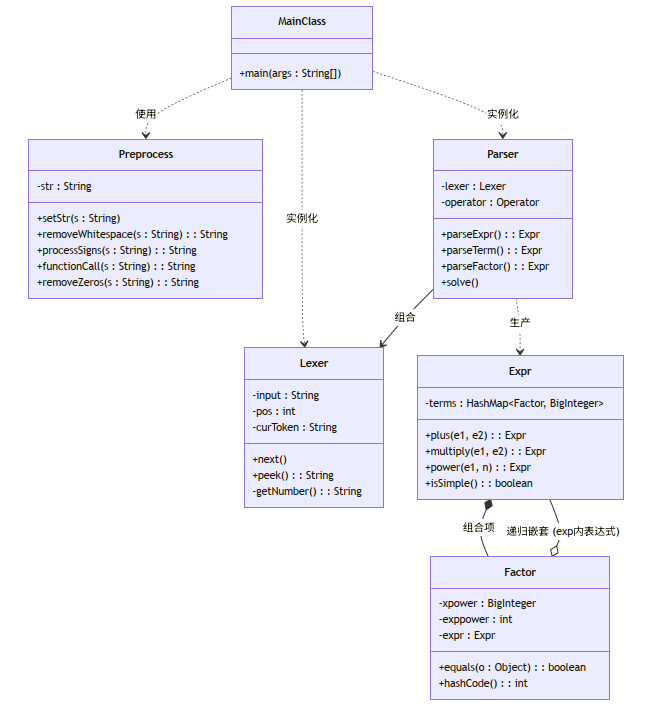
Parser 与 Operator (单向数据耦合)**:Parser 依赖 Operator 进行数学计算。这是一个相对健康的耦合,Parser 只负责将字符串拆解为 HashMap,然后扔给 Operator 处理,获取结果。Parser 内部逻辑 (高度耦合)**:在 parseExpr 和 parseTerm 中,我通过手动维护 pos 游标、括号计数器 flag 以及起始点 start 来进行字符串截取。这种解析逻辑与字符串的绝对位置绑定,一旦遇到异常符号,极易发生 StringIndexOutOfBoundsException。 架构特征:引入了 Lexer ,彻底重构了真正的词法和语法分析,并将第一次作业的预处理操作和强行展开自定义函数的方法融为了 Preprocess 类。将之前完全基于 HashMap<Integer, BigInteger> 进行的运算,改为了HashMap<Factor, BigInteger>,并包装为了一个新的类Expr,与Factor类递归嵌套。
类图:
| 类名 | 属性个数 | 方法个数 | 平均方法规模(LOC) | 最大控制分支数 $v(G)$ (对应方法) | 类总行数 |
|---|---|---|---|---|---|
Lexer | 3 | 4 | 12.0 | 6 (next) | 48 |
MainClass | 0 | 1 | 19.0 | 2 (main) | 19 |
Parser | 1 | 7 | 35.7 | 18 (solve) | 250 |
Preprocess | 1 | 6 | 26.5 | 12 (processSigns) | 159 |
Expr | 1 | 12 | 15.4 | 9 (plus) | 185 |
Factor | 3 | 6 | 8.0 | 5 (equals) | 48 |
内聚性衡量一个模块内部各个元素彼此结合的紧密程度。本项目整体达到了较高的功能内聚和通信内聚。
Lexer(功能高内聚):
Preprocess(高内聚):
removeWhitespace, processSigns, functionCall)都操作相同的输入数据流。虽然处理逻辑多样,但目标一致,为后续解析提供规范化字符串。Expr & Factor(高内聚):
Expr 类维护 HashMap<Factor, BigInteger>,而 Factor 描述因子的具体属性,x的幂、exp项、嵌套表达式。Expr.plus(), Expr.isSimple()。Parser:(中内聚)
Parser 类通过递归下降算法,parseExpr, parseTerm, parseFactor,实现了从 Token 到表达式对象的转换。Lexer 的输出,执行步骤具有严格的顺序性。2. 类的耦合度
MainClass 与各组件:(低数据耦合)
MainClass仅负责实例化对象并按流程调用方法(preprocess -> lexer -> parser)。Parser 与 Lexer:(中耦合)
Parser 内部有一个 Lexer 引用。Parser 的解析逻辑完全依赖于 Lexer 提供的 peek() 和 next() 接口。Lexer 的 Token 定义发生重大变化,Parser 必须同步修改。Expr 与 Factor:高耦合,递归依赖
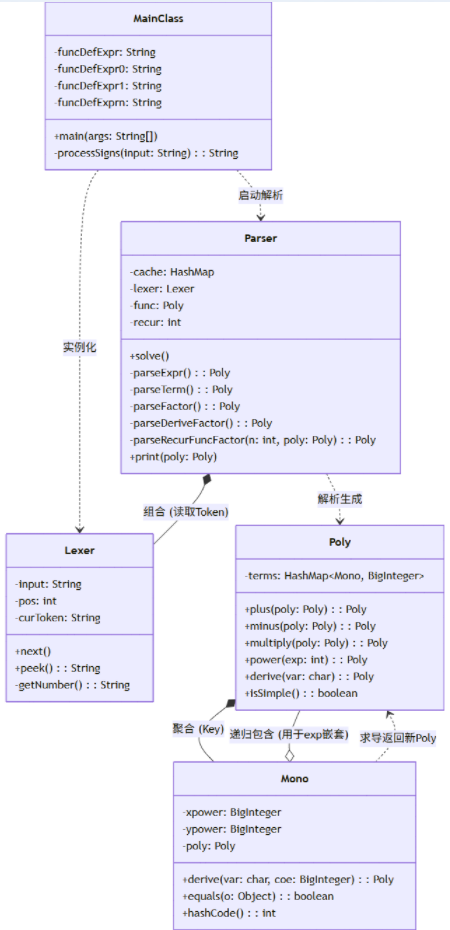
Expr 由多个 Factor 组成,而 Factor 内部可能又包含一个 Expr用于处理exp(...)。 架构特征:抛弃预处理类,抛弃直接替换自定义函数字符串,完全依赖递归下降和基于 HashMap 的标准化多项式存储(更名为Poly + Mono)。支持双变量和递归函数记忆化。
度量数据表:
| 类名 | 属性个数 | 方法个数 | 平均方法规模(LOC) | 最大控制分支数 $v(G)$ (对应方法) | 类总行数 |
|---|---|---|---|---|---|
Lexer | 3 | 4 | 15 | 10 (next) | 65 |
MainClass | 4 | 6 | 10 | 5 (main) | 63 |
Mono | 3 | 7 | 12 | 6 (derive) | 69 |
Parser | 4 | 15 | 20 | 14 (parseFactor) | 277 |
Poly | 1 | 14 | 15 | 10 (isSimple) | 165 |
Mono 和 Lexer 达到了极高的内聚。Lexer 只负责游标移动,Mono 只负责封装单项式的基本属性(指数与嵌套的 Poly)并提供微观求导法则。它们不关心外界的逻辑。Parser 的耦合度依然偏高。它不仅需要调用 Lexer 获取信息,还要实例化 Poly,并在解析函数因子f 或 f{n}时递归实例化新的 Parser。在第一次作业早期,我就直接使用了 HashMap<Integer, BigInteger> 来映射多项式。它可以摆脱了同类项合并的文本处理难题,但整个系统的脆弱性全部集中在 processSigns 方法中,我试图在“解析之前”用纯文本替换的方式解决所有符号优先级和结合律的问题,这种 “面向过程的暴力破解” 违背了树形结构的解析规律。没有 Lexer 充当缓冲层,导致第一次作业的 Parser 在处理 + 和 - 时,无法区分它们到底是“加减运算符”还是“正负号因子”,最终导致逻辑重构。
第二次作业通过 Lexer 词法分析与 Parser 语法分析的分离,遵循了经典结构。Factor 类中包含了对 Expr 的引用,能够通过递归下降法处理嵌套括号和 exp() 内部的复杂表达式。使用 HashMap<Factor, BigInteger> 作为多项式的存储结构,简化了项的合并逻辑。但是Parser.solve 中包含了过多的打印优化逻辑,并且Preprocess 中的字符串频繁 replace 和 delete 在极端数据下可能有性能瓶颈。
HW2 最大的教训是,只基于字符串替换的架构在面对递归与嵌套时是不堪一击的。
在 HW2 中,为了处理多层函数调用(如 $f(f(f(x)))$),我原本的 Preprocess 类会将表达式展开成难以置信的长度,导致严重超时TLE。痛定思痛后,我在 HW3 彻底删除了 Preprocess。
第三次作业再次重构后,函数调用变为“运行时解析”。当 Parser 遇到 f 时,实例化一个新 Parser 去解析函数定义式,并将当前解析出的实参 Poly 传递进去。遇到自变量 $x$ 时,直接返回该实参 Poly。这种“变量代换”的思想不仅彻底解决了 TLE,还让代码量不增反降,逻辑变得异常清晰。这让我感受到良好的对象模型本身就是最佳的性能优化。
假定新情景:引入符号积分算子 int(Expr, var)(假设仅对初等多项式进行积分,忽略无法解析的 $\exp$ 积分)。
扩展性评估:现有的 Poly + Mono 架构具有极强的扩展能力。
Lexer 增加对 int 的识别。Parser.parseFactor 中新增一行 parseIntegralFactor。Poly 和 Mono 中增加 integrate(char var) 方法。利用现成的 HashMap 遍历,针对对应变量的指数进行 $+1$ 即可。整个过程完全不需要侵入或修改现有的加减乘规则。Lexer 的交互上。由于预处理时专门把因子前的符号想处理掉而又漏了情况,导致出现类似 ^+ 反而无法处理的非法序列,使因子解析崩溃。Lexer 严格控制的 Token 流。Parser.parseChoiceFactor。[A==B?C:D] 时,无论条件是否成立,代码都将 C 和 D 完整解析为多项式对象后再做选择。若废弃分支极为复杂,则浪费极大算力。while 循环和 lexer.next() 跳过无用分支的代码流。exp 漏加括号exp(x*y),缺少必要的内层括号。问题在 Poly.isSimple() 方法。parseFactor 和 isSimple 方法,其圈复杂度(v(G))均超过 10,代码行数逼近 50 行,内部充斥着嵌套的 if-else。相反,未出现 Bug 的 Poly.multiply 或 Mono.derive,复杂度均低于 5,且逻辑高度线性。parseFactor 的高复杂度,应当引入多态或工厂模式。定义一个 Factor 接口,然后让 ExprFactor、VarFactor、DeriveFactor 各自实现 parse 逻辑。解析器只需查表或使用 Map 映射决定调用哪个具体的子类去解析,从而彻底解决庞大的 if-else 树。在互测中,我主要采用了以下策略:
print 优化的模块。如果看到对 $\exp$ 内部括号判断逻辑写得含糊的,直接构造边缘用例进行测试。---+++002*x),测试对方 Lexer 的鲁棒性。Poly.plus/minus 中,计算完后立刻判断系数是否为 BigInteger.ZERO 并将其从 HashMap 移除。这一优化保证了简洁性与正确性,因为它让多项式永远处于最简标准型,减少了后续运算与打印的遍历负担。isSimple 方法,省去 $\exp$ 内部冗余的括号。正号项提前需要先遍历一遍找到大于0项,先输出。基本都是0%,自己写的,要不然不会把架构写成一坨屎
我使用了 AI 辅助度量分析代码复杂度,帮忙给出了度量数据。并用大模型辅助找bug,但是最终效果不好,真正找到bug是在强测和互测中被发现。
效果评价:大模型辅助分析程序结构,给出度量数据,极大地提高了我复盘架构效率。然而,在辅助解决 Java 代码中深层递归状态的 Bug 时,AI 往往只能泛泛而谈,最终仍需我自行断点 Debug。
不少同学都有疑似AI生成的注释,但是忘了谁了,懒得把代码下载回来找了
第一单元是一场面向对象思维的洗礼。最初试图用面向过程的字符串替换思维,结果被 TLE 击垮。反复痛心删掉数百行旧代码进行彻底重构,到最终看着控制台准确输出表达式,有着巨大成就感。
OO 不能只是纸上谈兵的“封装、继承、多态”,而需要在面对需求爆炸、逻辑嵌套时,善用面向对象思维。主动思考解耦,提高扩展性,试图提高性能。需要我们对数学规律和思维逻辑的深刻建模。
建议明确性能优化的边界:许多同学为了微不足道的性能分,写了大量晦涩、极易出错的去括号逻辑,导致正确性崩盘。建议在指导书中明确限定“哪些化简是鼓励的,哪些是不必要的”,避免大家陷入无效的文本优化内卷。

