



302
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享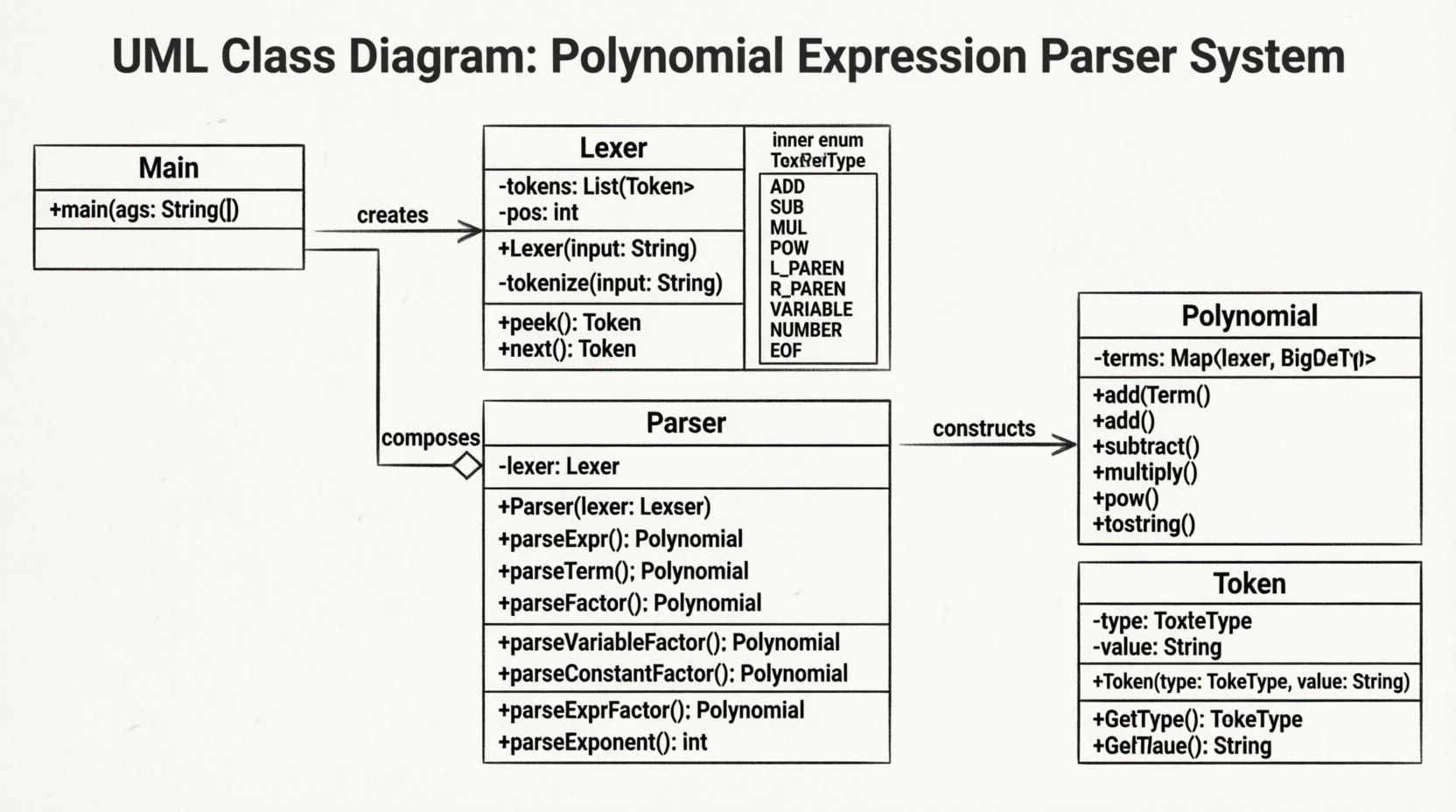
| 类名 | 属性个数 | 方法个数 | 总代码规模 (LOC) | 主要逻辑复杂度 (Cyclomatic Complexity) |
| `Main` | 0 | 1 | ~15 | 低 (仅包含基本的输入输出控制流) |
| `Lexer` | 2 | 4 | ~70 | 中 (核心方法 `tokenize` 包含 9 个分支) |
| `Parser` | 1 | 8 | ~119 | 中 (递归下降方法平均 2-5 个分支) |
| `Polynomial` | 1 | 9 | ~150 | 高 (输出逻辑 `appendTerm` 包含 9 个分支) |
Main.java
Total Methods: 1
Total Complexity: 2
Methods Details
|
Method Name |
Line |
Complexity |
Status |
Nesting Depth |
|
main |
4 |
2 |
simple |
1 |
Lexer.java
Total Methods: 7
Total Complexity: 24
Methods Details
|
Method Name |
Line |
Complexity |
Status |
Nesting Depth |
|
Token |
18 |
1 |
simple |
0 |
|
getType |
23 |
1 |
simple |
0 |
|
getValue |
27 |
1 |
simple |
0 |
|
Lexer |
32 |
1 |
simple |
0 |
|
tokenize |
36 |
18 |
complex |
3 |
|
peek |
63 |
1 |
simple |
0 |
|
next |
67 |
1 |
simple |
0 |
Parser.java
Total Methods: 8
Total Complexity: 38
Methods Details
|
Method Name |
Line |
Complexity |
Status |
Nesting Depth |
|
Parser |
6 |
1 |
simple |
0 |
|
parseExpr |
10 |
13 |
complex |
3 |
|
parseTerm |
40 |
6 |
moderate |
2 |
|
parseFactor |
62 |
8 |
moderate |
2 |
|
parseVariableFactor |
76 |
2 |
simple |
1 |
|
parseConstantFactor |
86 |
4 |
simple |
2 |
|
parseExprFactor |
100 |
2 |
simple |
1 |
|
parseExponent |
112 |
2 |
simple |
1 |
Polynomial.java
Total Methods: 9
Total Complexity: 56
Methods Details
|
Method Name |
Line |
Complexity |
Status |
Nesting Depth |
|
Polynomial |
9 |
1 |
simple |
0 |
|
Polynomial |
13 |
2 |
simple |
1 |
|
addTerm |
20 |
5 |
simple |
2 |
|
add |
33 |
2 |
simple |
1 |
|
subtract |
42 |
2 |
simple |
1 |
|
multiply |
51 |
4 |
simple |
2 |
|
pow |
63 |
5 |
simple |
2 |
|
toString |
81 |
10 |
moderate |
2 |
|
appendTerm |
116 |
25 |
complex |
3 |
类设计考虑说明
1. Lexer : 采用预处理方式一次性完成Token化,内部维护一个 List<Token> 和 pos 指针,使其可以自由地 peek 和 next 。
2. Parser : 采用递归下降子程序法。每一个非终结符对应一个方法,结构直观地对应了形式文法。
3. Polynomial : 核心数据结构为 Map<Integer, BigInteger> ,其中Key为指数,Value为系数。利用Map的特性可以非常方便地处理合并同类项。
内聚及耦合性
高内聚 : 各个类的职责定义清晰。
松耦合 : Polynomial 类不依赖于解析逻辑,可以独立用于任何数学计算场景。
紧耦合: Parser 必须依赖 Lexer 来获取输入流,同时也依赖 Polynomial 来生成结果。
优点:
核心运算使用 BigInteger ,能够处理任意精度的整数运算,避免了溢出风险。
递归下降的解析结构使得后续增加新的运算符或函数较为容易。
缺点:
Polynomial.toString和appendTerm的逻辑过于臃肿,维护难度较高。
HW1
采用了经典的 Lexer + Parser 结构。 逻辑相对线性,解析器直接在解析过程中完成同类项合并。
HW2
新增了指数函数和自定义函数。这意味着多项式的“项”中可以嵌套另一个完整的多项式。我重构了 MonomialKey 类,将其从一个简单的整数扩展为一个复合对象。
HW3
引入了求导运算和复杂的递归函数定义。
得益于 HW2 的递归架构,HW3 的求导功能变成了一个简单的“内部规则添加”,由于 Polynomial 本身具备递归性,求导过程也通过递归调用自身轻松完成。
设定新情景 :增加三角函数支持
1. 数据层扩展 :在 MonomialKey 中增加字段。Key为函数名,Value 为括号内的多项式。
2. 代数层扩展 :在 Polynomial.derive() 中增加规则
3. 解析层扩展 :仅需在 Parser.parseFactor() 中增加对 sin 和 cos 关键字的识别分支。
测评中有很多不足,此处难以详尽描述。
我主要采取了基于大模型的极端用例生成。
然而,实际效果表明大模型生成的用例强度不够,可能不能覆盖所有的情况。
这让我意识到,目前的大模型仍存在局限,不能完全依赖其进行测试覆盖。
我觉得要想发现深层次的架构与逻辑Bug,仍需对代码设计结构分析后,人工设计针对性的测试场景。
有一个典型的性能优化:快速幂算法
不采用简单的循环累乘,而是采用二进制快速幂算法。通过对指数进行二进制拆分,可大幅减少多项式乘法的次数。
能保证正确性,快速幂是成熟的方案,其正确性由算法逻辑保证。
局部牺牲了简洁性 ,快速幂比循环累乘的代码行数多,但在逻辑上依然是清晰的。
除了直接的代码生成外,大模型还存在以下的使用:
在面对指导书中一些表述较为晦涩的内容时,我会将相关段落输入大模型,要求其用通俗语言解释或举例说明。
利用大模型生成了特定测试用例及脚本。
在架构设计与大模型讨论不同模式的选择。
大模型有的时候能够解读的比较准确,有的时候可能还不如其他人的讨论更加有价值。在测认识用例设计方面,比单纯人脑的生成更加有效率,但是不一定覆盖所有的场景,架构设计方面我个人也不是专家,很难判断大模型的水平。
感觉很难判断互测房间中哪些同学在作业中大量的使用了 AI 生成的代码,因此假设他们都没有大量使用AI生成。
这一单元的内容感觉难度曲线还是有些陡峭,随着指导书需求的不断变更,许多初期未深入思考的细节问题逐渐暴露。此外,本单元的内容导向与往年经验存在显著差异,这种变化带来了一定的适应成本,对我个人来说存在挑战性,需要在之后更加努力。
希望未来在理论授课时,不要把大量篇幅放在一些高度凝练的规律之上,有些听起来十分正确有道理。但是等到面对指导书之后,往往会记不起来有哪些适用,即使记起来了也很少能够达到融会贯通的效果。此外,对于如何聪明使用大模型工具及如何挑选合适的大模型工具,也没有过多的指引,只能自行修炼相关的功力,或者私下小组研讨时产生些许交流。感觉这样并不利于顺应当下的前沿技术浪潮,无法助力全新世代下的人才培养。若能在此部分有所补充,虽然未必能让顶尖学生的上限更高,但对于提升整体学生的水平的下限,应当会有显著的帮助。
以上就是我的部分思考,我深知自己的水平与能力只能敲敲键盘写下个人的一些见解,衷心祝愿此课程能够让所有人(课程团队及课程学生)的体验都更加美好。

