


305
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享说实话,第三单元刚开始的时候我是有点懵的。前两个单元我已经慢慢适应了面向对象的思维,结果Unit3直接给我扔来一堆@requires、@ensures、@signals,整个人都不好了。不过回过头来看,这一单元确实让我对"设计先行"有了完全不同的感受。
另外我个人原因第十次作业没有提交,所以这篇博客主要聊第九次和第十一次作业,以及研讨课上那个"击鼓传花"游戏。
JML是什么感觉
刚看到JML的时候,我第一反应是:这不就是注释吗?写这个有什么用?
后来才慢慢明白,JML不是普通注释,它是可以被工具验证的契约。一个方法的@ensures子句,严格规定了这个方法成功执行后,世界是什么样子的;@signals子句规定了什么情况下抛什么异常。它的精髓在于:你写代码是在实现这份契约,而不是在凭感觉猜测业务逻辑。
举个我踩过的坑:likeVideo这个方法,我最初想当然地认为"点赞就是+1",结果JML里写的是toggle。如果我一开始认真读规格,就不会在这里栽跟头。规格就是说明书,不看说明书就动手,是我前几次的通病。
还有一个让我印象很深的细节:getInterest计算公式里有个(totalVideos - watchedVideos.size() + 1),那个+1是JML明确写出来的。这种细节如果靠"猜",十次有九次猜错。
规格驱动开发的实际体验
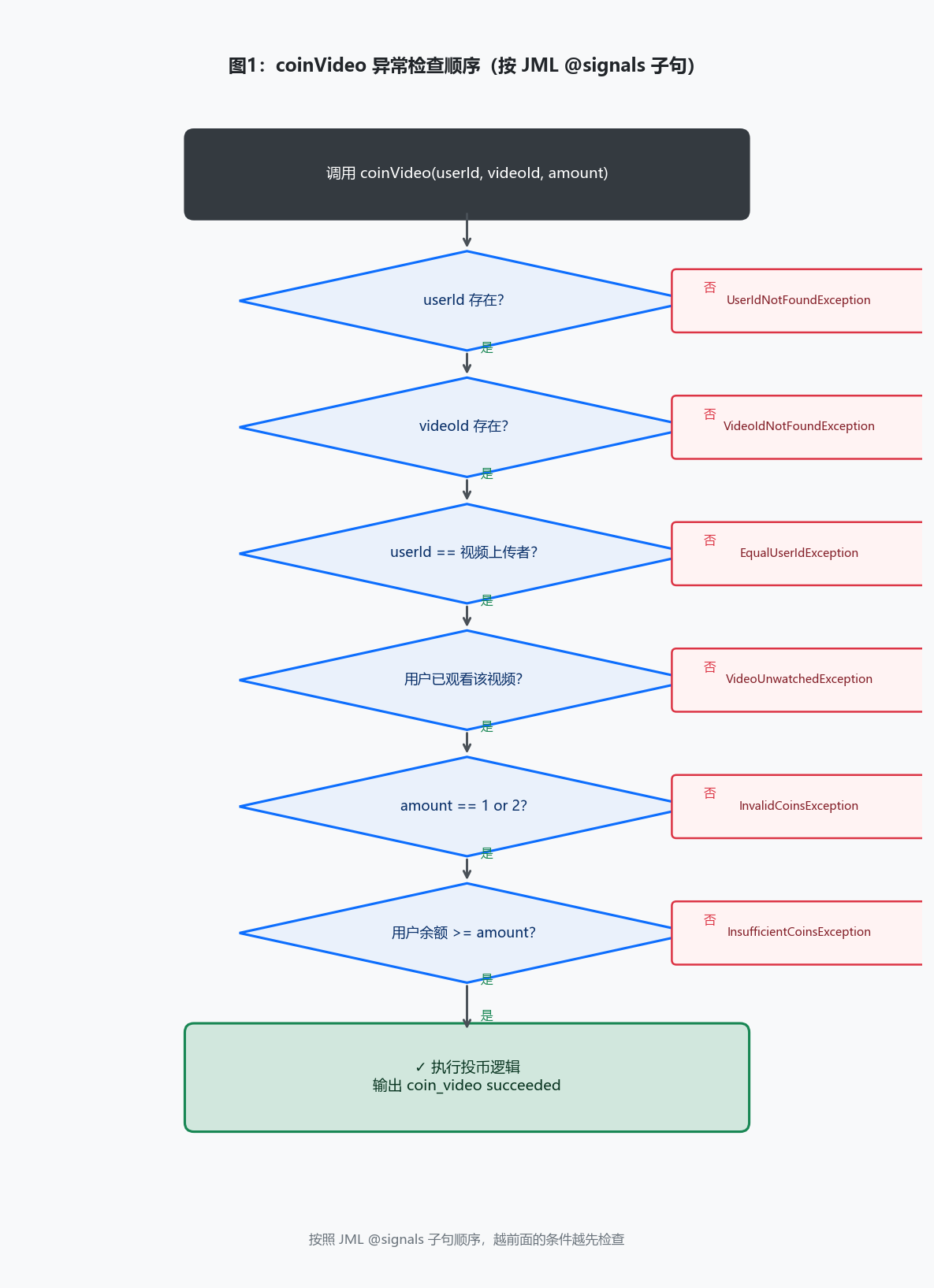
我现在的习惯是:先把所有@signals子句列出来,确认异常的触发条件和抛出顺序,再看@ensures后置条件,最后再动手写代码。@signals和@ensures不是并列关系,而是分支关系,这一点很重要。
写测试的"正确姿势"
最开始我想:直接构建一个场景,调用一下,看返回值对不对,不就行了?
后来发现这样写的测试其实很脆弱,因为它只验证了"答案对不对",没有验证"副作用有没有"。对于标注了pure(纯查询)的方法,调用前后网络状态不能有任何改变,这才是最容易被实现者忽略的地方。
所以我的测试里加入了镜像网络对比:调用前建一个状态完全相同的镜像网络,调用后用strictEquals逐一对比每个用户的状态。
这里有个坑:我最开始想直接调network.getVideos()来对比视频状态,但评测机的Network类里没有这个方法(因为它不在官方接口里),编译直接报错。最后改成用UserInterface.getInfluence(type)来间接感知视频状态的变化——因为influence等于用户上传视频的heat总和,如果视频状态变了,influence也会变。
几个测试心得
recommendNthUp有四种异常,每一种都要单独测。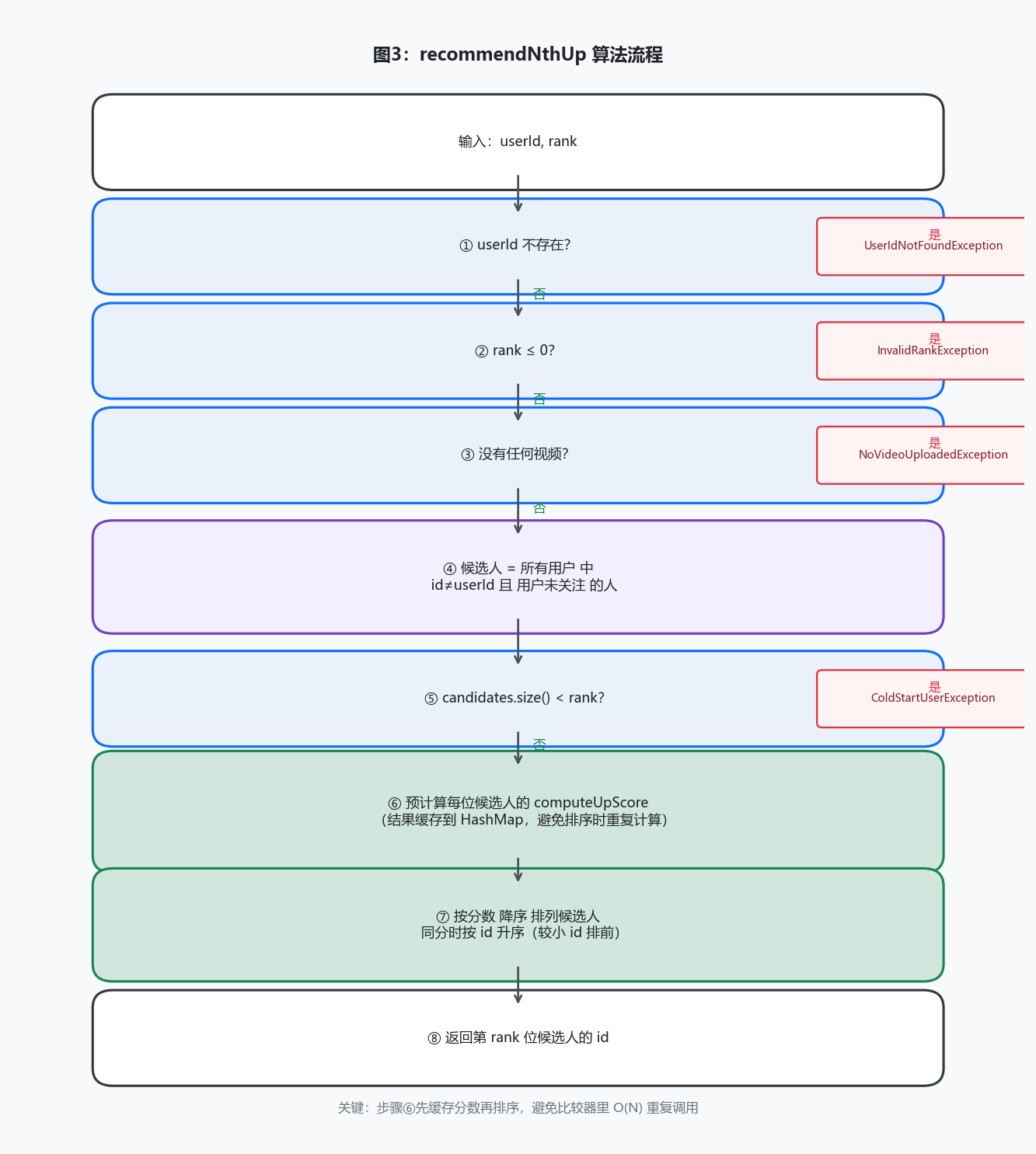
容器选择在迭代中的重要性
第九次作业到第十一次作业,方法数量几乎翻了一倍。最直接的感受是:容器的选择在迭代中变得非常重要。
比如receivedVideos(用户收到的视频列表),最初用ArrayList,每次往前插入(prepend)都是O(N)。到hw11新增了大量的uploadVideo和forwardVideo操作,换成了LinkedList,addFirst()变成O(1)。
还有following集合,ArrayList的isFollowing()每次要遍历是O(N),换成LinkedHashSet后查询O(1),还保留了插入顺序。
如何发现性能瓶颈
主要靠三个方法:
queryMutualFollowingSum如果每次查询都双重遍历用户,是O(N²)。改成在followUser/unfollowUser时维护动态计数器,查询变O(1)。queryLongestDecSeq是图上的DFS,加了备忘录(memoization)之后每个节点只算一次。recommendNthUp排序时先把所有候选人的分数缓存到HashMap,避免比较器里重复调用computeUpScore。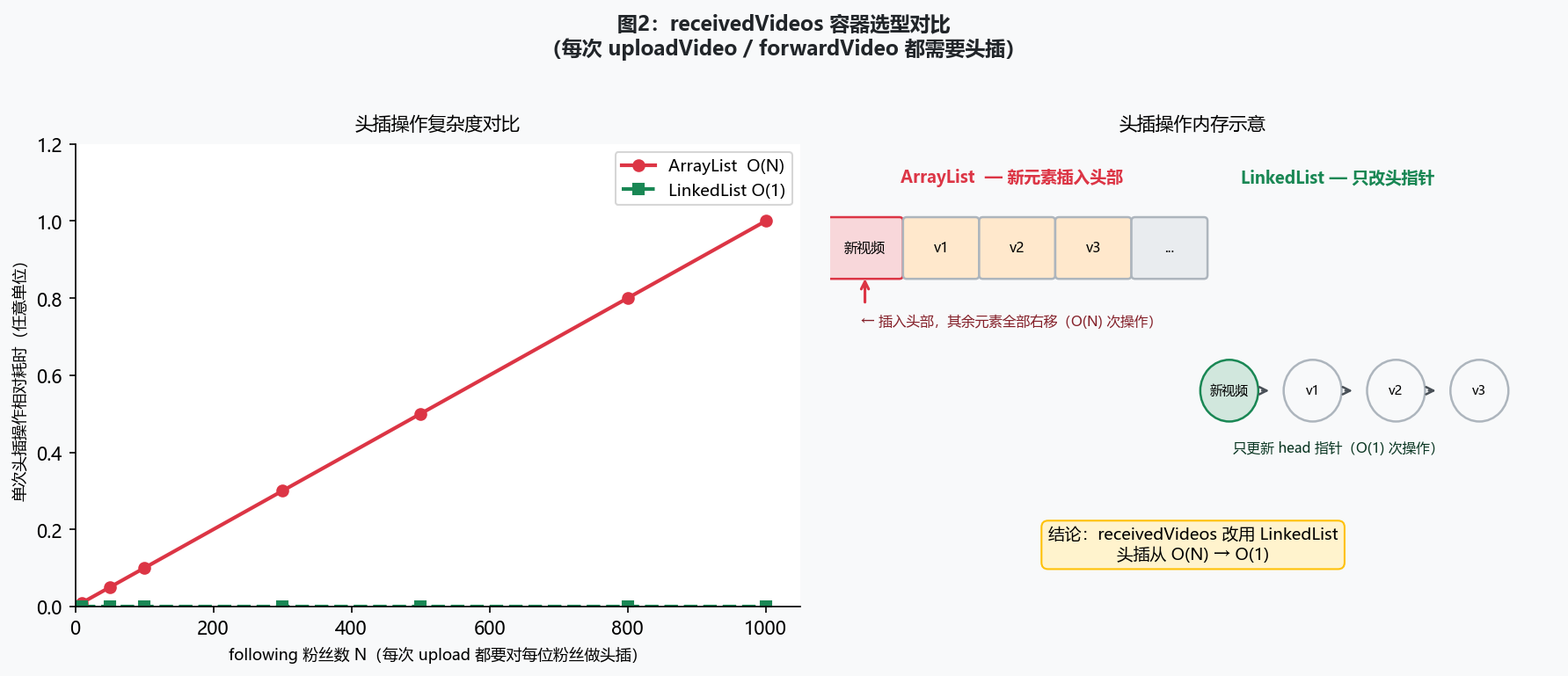
Bug 1:年龄上限写错了
addUser的年龄校验写的是age > 200,但JML写的是age > 110。
根本原因:数据生成范围不等于业务逻辑边界。规格是规格,数据是数据,不能混为一谈。
Bug 2:likeVideo实现成了单纯+1
没仔细看JML,以为点赞就是点赞。结果是toggle,已经点过赞再点一次是取消。互测被人抓到了,挺尴尬的。
Bug 3:watchVideo的typeCount逻辑
最初的实现:如果之前没看过这个视频才让typeCount+1。
JML的意思:每次watchVideo都让typeCount+1,不管有没有看过。watchedVideos列表里不允许重复,但typeCount是累计的。
这个区别直接影响所有推荐算法的分数计算。
Bug 4:id1==id2时自作聪明
queryShortestPath在id1==id2时我跑了一遍BFS试图找环。JML明确规定:直接返回0。
教训:任何时候都要相信规格,不要自作聪明加逻辑。
Bug 5:Checkstyle
Network.java超500行 → 抽出Recommender.javastrictEquals超60行 → 拆成三个私有方法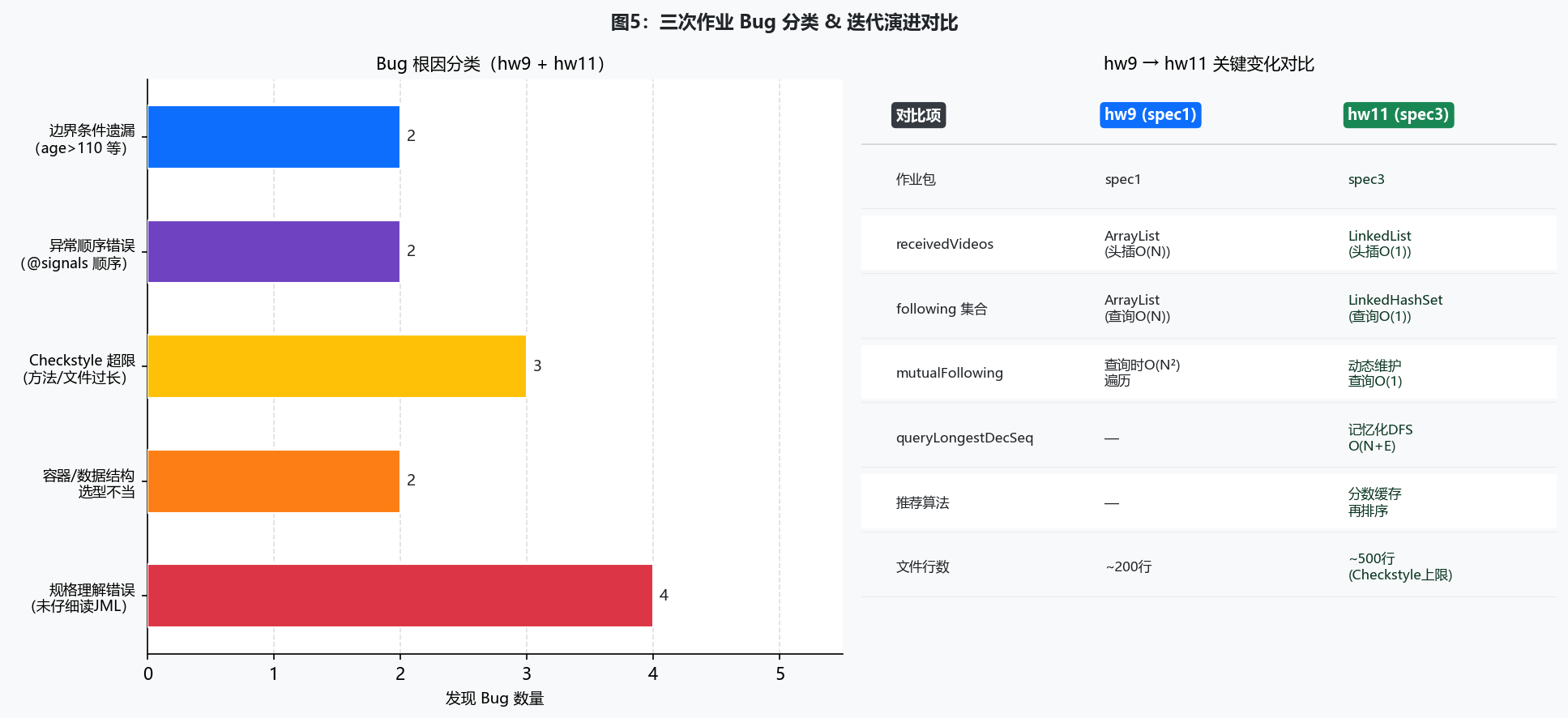
0
这次作业我用了Claude Code Agent来辅助开发,说几点真实感受。
优势:快速整理异常顺序
给它看JML,它能很快帮你整理异常的检查顺序,不会搞乱@signals子句的先后关系。这对像coinVideo这种有六个异常的方法来说,节省了大量精力。
会不会忽视效率?会,但可以修正
最初生成的代码里,排序比较器里直接调computeUpScore,导致同一个候选人的分数被计算很多次。我指出之后它马上加了分数缓存。
大模型不主动考虑大数据集下的性能,因为它"默认"场景是小数据量的。需要你主动提出性能要求。
会不会忽视容器选择?有一定概率
最初帮我选了ArrayList存following集合,我问"数据量大时isFollowing()会不会很慢",它立刻改成了LinkedHashSet,并解释了为什么选LinkedHashSet而不是普通HashSet。
总结:大模型需要你带着问题去用,不能直接相信第一版答案。它的第一版通常逻辑正确,但不一定最优。
Code Agent的特殊体验
和普通聊天AI相比,Code Agent能直接读写文件,能主动发现问题(比如它读完Network.java后主动提醒"这个文件快到500行限制了,建议提前拆分")。但上下文有限,对话太长会忘记之前的内容,关键结论要及时写入文件。
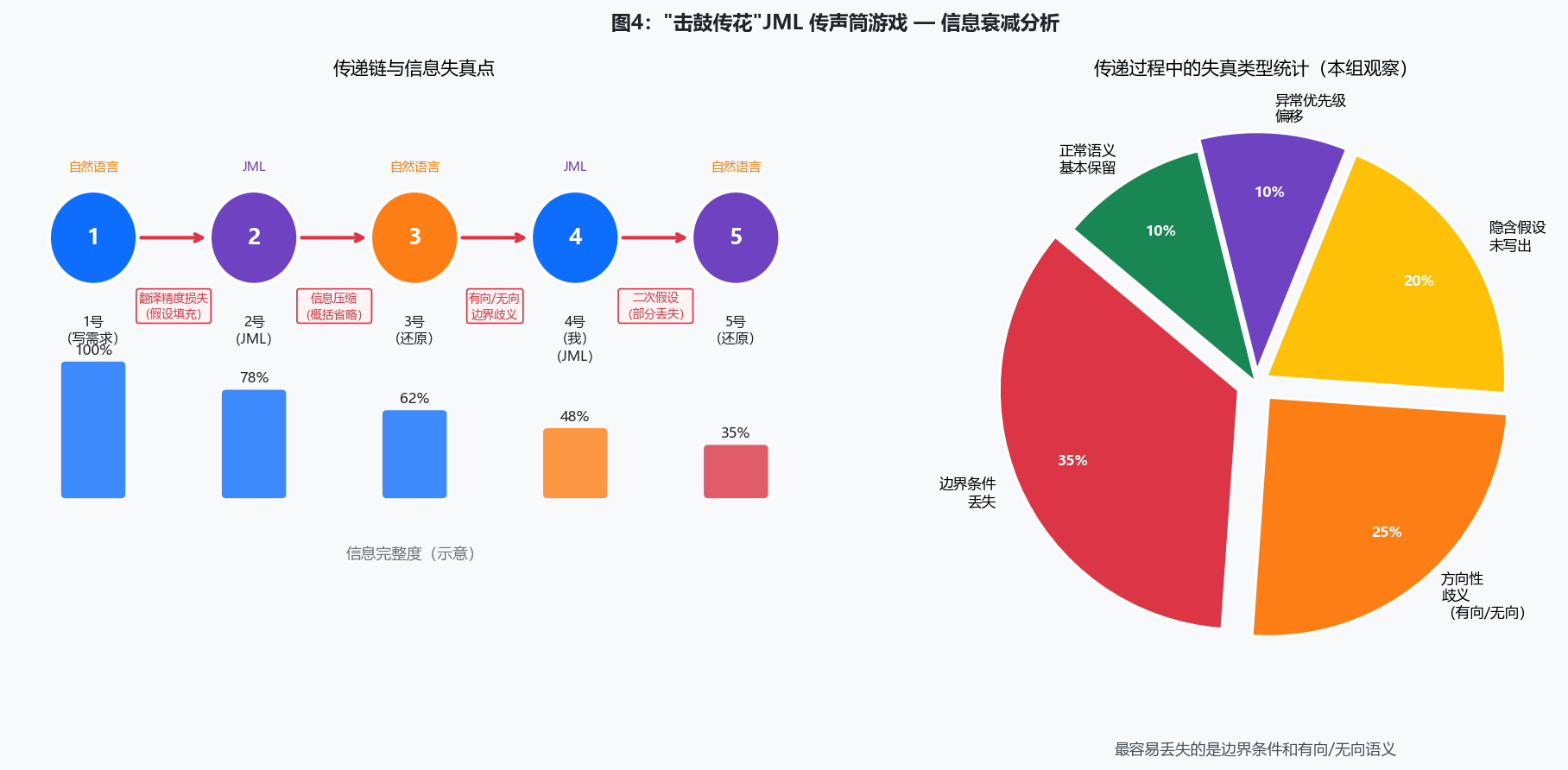
这是Unit3第二次研讨课上的一个游戏。我是4号,一共参与了5轮传递。
我发现的问题
Round 2中,"最大连续温度区间"的JML里没有覆盖数组为空的边界情况,实现者可能在空数组上抛出越界异常而不是返回0。
Round 4中,"删除边使图中任意三点不构成三角形"这个需求里,"三角形"在有向图上的定义是什么?这个信息在传递过程中完全丢失了,我只能按自己的理解写JML,但这可能已经和原始需求不是同一件事了。
信息为什么会失真
多人协作时如何统一理解
这一单元是我OO课上学习曲线最陡峭的一个单元。JML在刚接触的时候感觉很奇怪,但它代表的那种"说清楚再动手"的理念,在工程实践中是真的有价值的。
如果以后有机会参与大型项目,我希望自己能记住:
希望这篇博客对看到的同学有一点用处,也欢迎大家评论交流,一起期末不挂科(笑)。

