


307
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享第三单元的主题是JML规格驱动开发。与前两单元的"根据自然语言需求实现程序"不同,本单元要求我们严格依据形式化规格(JML)实现接口,并利用 JUnit 进行合约验证。学习目标是掌握契约式设计(Design by Contract)思想、理解规格与实现的关系、以及如何在迭代中维护规格一致性。
本单元经历了三次作业的迭代:
HW9(spec1):基础社交网络,用户关注/取关、视频上传/观看、最短路径查询,初步接触 JML 规格实现。
HW10(spec2):引入视频热度、点赞/投币/转发/评论/勋章、最长下降子序列、最佳贡献者查询,规格复杂度大幅提升。
HW11(spec3):引入推荐系统(视频推荐、UP主推荐)、用户画像、全局最佳贡献者,规格规模达到顶峰。
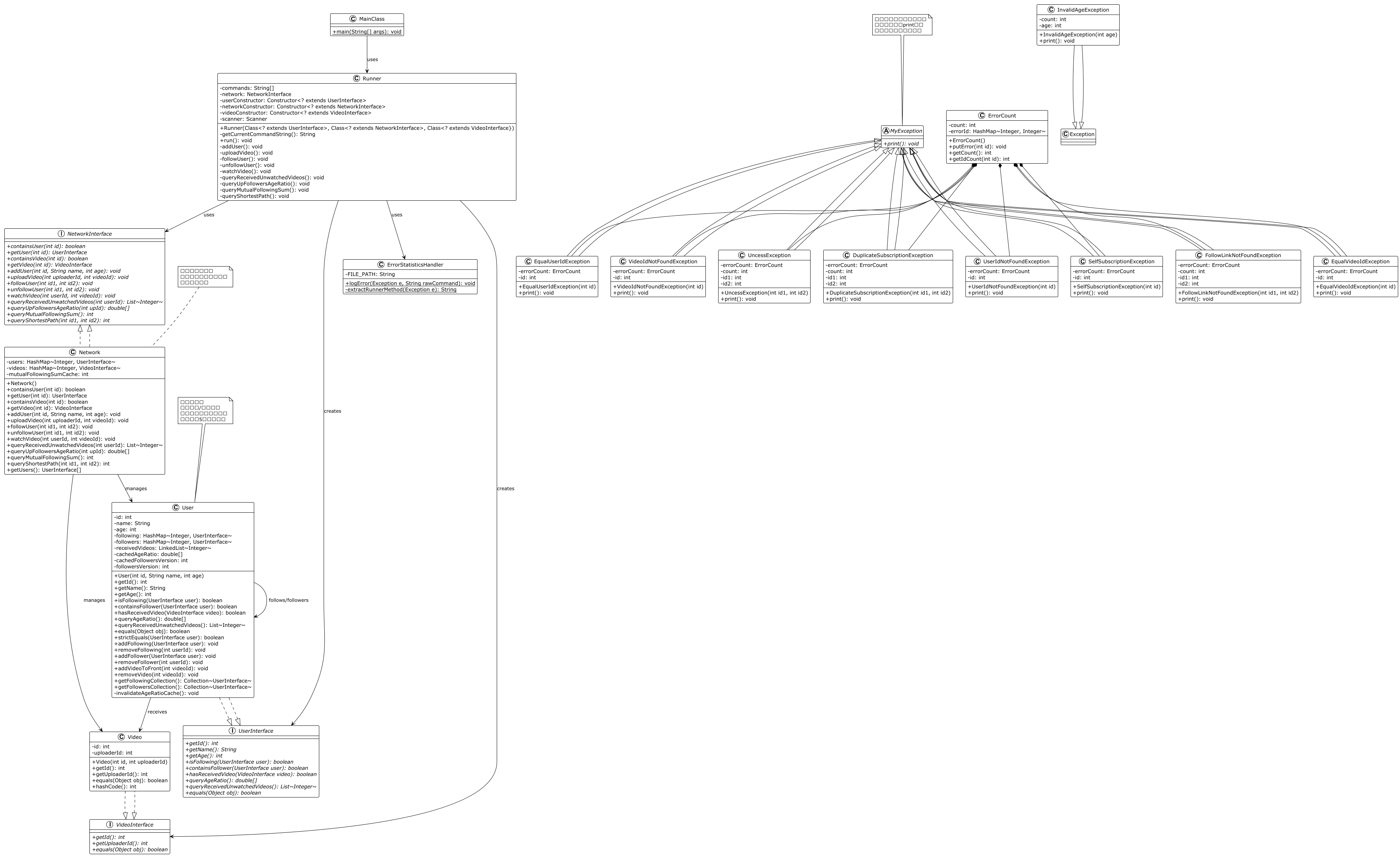
HW9 实现了基础的社交网络原型。核心架构为三层模型:
数据模型层(User / Video):封装用户和视频的原子属性与简单操作。
业务逻辑层(Network):实现所有接口方法,管理 users / videos 两个全局容器。
异常处理层(Exception 体系):共 10 种异常类,继承自 MyException。
| 决策 | 方案 | 理由 |
|---|---|---|
| 查询最短路径 | BFS + HashMap 距离表 | 图规模不大,BFS 保证 O(V+E) |
| 互关缓存 | mutualFollowingSumCache 增量维护 | follow/unfollow 时 O(1) 更新,避免全量遍历 |
| 年龄比缓存 | 版本号 + 惰性失效 | followers 变化时才重新计算 |
HW9 在强测中出现了 CPU TLE。根因在于 queryMutualFollowingSum 的初始实现是全量遍历:
// 问题版本:O(n²) 全量遍历所有用户对
public int queryMutualFollowingSum() {
int sum = 0;
for (UserInterface u1 : users.values()) {
for (UserInterface u2 : users.values()) {
if (u1.getId() < u2.getId() &&
u1.isFollowing(u2) && u2.isFollowing(u1)) {
sum++;
}
}
}
return sum;
}
当用户数量增大时,双重循环 O(n²) 的性能问题被放大,直接导致超时。修复方案:改为增量维护——在 followUser 和 unfollowUser 时 O(1) 更新缓存值,queryMutualFollowingSum 直接返回缓存。
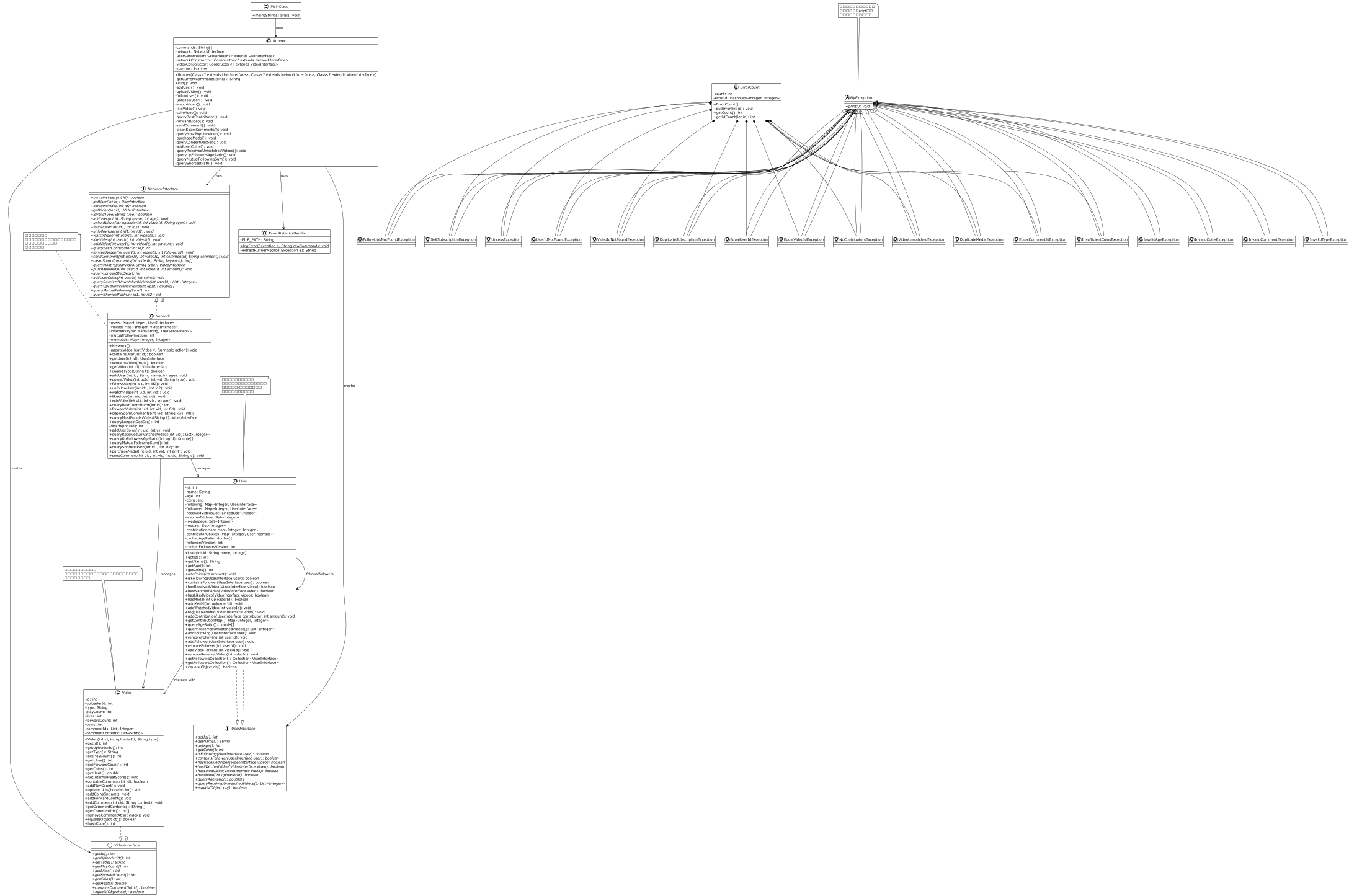
HW10 在 HW9 基础上新增了 8 个异常类、近 20 个新方法,包括视频类型、热度排序、点赞反转、投币贡献、转发推送、评论垃圾过滤、勋章购买、最长下降子序列等。规格复杂度呈指数级增长。
热度排序:引入 videosByType(TreeSet<Video>),按热度降序 + id 升序排列。每次热度变化时通过 updateVideoHeat 删除再插入以触发重排。
最长下降子序列(LDS):DFS + 记忆化搜索,memoLds 在用户关系变化时失效。
评论垃圾过滤:正向扫描匹配关键词,反向遍历删除,避免索引错位。
HW10 因三个方法实现与 JML 规格不符,进入 o 房(互测被 hack)。
Bug 1:addVideoToFront 不应检查重复性
JML 要求无条件将视频加入队列头部(允许重复条目——同一视频可被多次转发或上传推送)。但我的早期版本错误地检查了 receivedVideosSet 和 watchedVideos,导致重复视频被抑制:
// 错误版本:不应拦截重复视频
public void addVideoToFront(int videoId) {
if (!watchedVideos.contains(videoId)) { // 错误的过滤
receivedVideosList.addFirst(videoId);
}
}
根因:将"去重"的业务直觉错误地应用到规格中。JML 规格明确要求 addFirst,没有过滤条件。
Bug 2:removeReceivedVideo 应用 removeAll 而非 remove
JML 要求移除所有值为 videoId 的条目。单次 remove(Object) 只移除第一个匹配项:
// 错误版本:只移除第一个 receivedVideosList.remove(Integer.valueOf(videoId)); // 正确版本:移除所有 receivedVideosList.removeAll(java.util.Collections.singleton(videoId));
Bug 3:queryReceivedUnwatchedVideos 不应过滤 watchedVideos
因为观看视频时已经通过 removeReceivedVideo 从列表中移除了对应条目,列表中天然只剩未观看的视频。额外用 watchedVideos 过滤反而是画蛇添足,且可能导致返回数量不足 5 个:
// 错误版本:多余的过滤 return receivedVideosList.stream() .filter(v -> !watchedVideos.contains(v)) .limit(5) .collect(Collectors.toList()); // 正确版本:直接取前 5 个 int limit = Math.min(receivedVideosList.size(), 5); return new ArrayList<>(receivedVideosList.subList(0, limit));
三个 bug 的共同特征是"自作主张"——在 JML 规格之外自行添加了额外的业务逻辑假设。规格驱动开发的核心原则是:规格即契约,实现只需且必须精确满足规格,任何额外的"我认为应该这样"的过滤或检查都可能导致不一致。
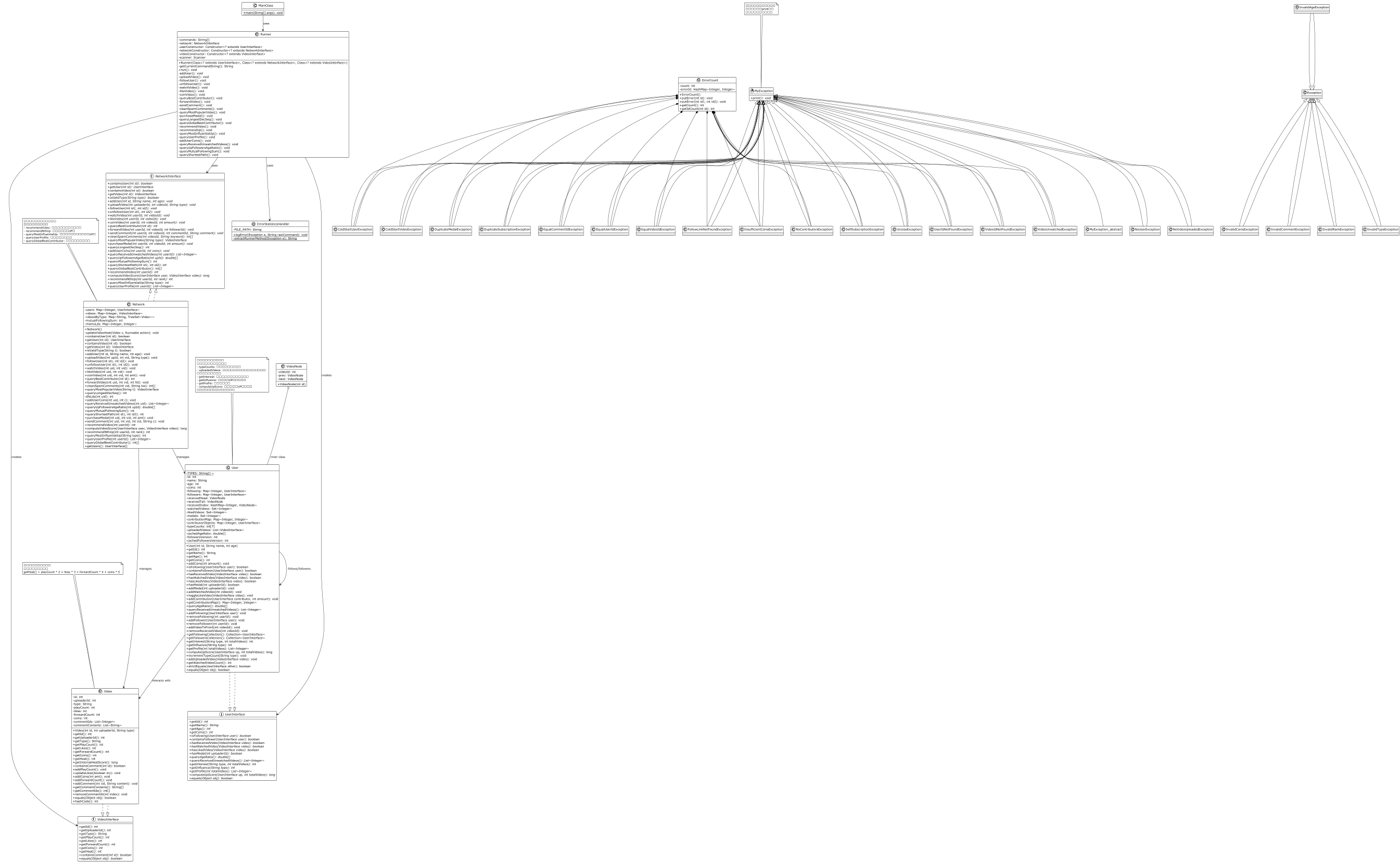
HW11 新增了推荐视频(recommendVideo)、推荐 UP 主(recommendNthUp)、用户画像(getProfile/getInterest)、影响力查询(queryMostInfluentialUp)、全局最佳贡献者(queryGlobalBestContributor)等功能。核心挑战在于冷启动(Cold Start)的边界条件处理。
自定义双链表(VideoNode):receivedVideos 从 LinkedList 升级为手动管理的双向链表,addVideoToFront 达到 O(1),removeReceivedVideo 通过 receivedIndex 哈希索引实现 O(1) 定位。
推荐算法:computeVideoScore = heat * interest,其中 interest = typeCount * (totalVideos - watchedCount + 1),实现个性化排序。
UP 主评分:computeUpScore = Σ interest(type) × influence(type),综合用户兴趣与 UP 主产出。
strictEquals:实现深度 equals 对比,用于 JUnit 验证全部字段一致性。
结合 HW9 的 CPU TLE 教训和 HW10 的规格不符教训,HW11 在实现时坚持两条原则:
时间优先:所有方法预先评估时间复杂度,关键路径(如推荐视频遍历所有视频)确保 O(n) 可控。
规格优先:逐字对照 JML 规格实现,不添加任何规格之外的假设条件。
最终在强测和互测中均未出现 bug,进入 A 房。
JML(Java Modeling Language)是一种形式化的契约语言,通过前置条件(requires)、后置条件(ensures)和不变式(invariant)精确描述方法的行为。其核心价值在于:
消除歧义:自然语言的"如果用户已关注则抛出异常"可以有多种理解,JML 的 \old 和 \result 使语义唯一。
契约分离:规格制定者关注"做什么",实现者关注"怎么做",两者通过规格解耦。
自动化验证:配合 OpenJML 等工具可静态检查实现是否满足规格。
理解 JML 很容易,但把自然语言翻译成 JML 很难。JML 比自然语言更详细、更全面。
这是我在"击鼓传花"游戏中最深的体会。一个看似简单的"将视频加入队列头部",自然语言一句话就完了,但 JML 需要精确描述:
队列的变化(receivedVideosList 增加了元素)
新元素的位置(头部,即 receivedVideosList[0])
其他元素的位置变化(原有元素依次后移)
不受影响的内容(其他字段不变)
这种精确性在多人协作时尤为重要——当规格由一个人编写、另一个人实现时,JML 就是消除信息差的终极手段。
严格遵循规格:实现只需要满足规格描述,额外的"智能"往往是 bug 的温床。
防御性实现:在不违反规格的前提下,可以对输入做额外的检查(如异常抛出),但不能修改规格规定的结果。
规格即文档:规格代码是活的文档,永远不会像自然语言注释那样过时。
等价类划分:每个方法的正常路径和异常路径至少各一个测试用例。
边界值测试:重点关注容器为空、大小为 1、满容量等边界。
状态演化测试:模拟一系列操作的完整生命周期(注册 → 关注 → 上传 → 观看 → 点赞 → 投币 → 转发)。
回归测试:每次迭代后运行全部已有用例,确保新增功能不破坏已有逻辑。
HW11 引入了 strictEquals 方法,使得 JUnit 测试可以深度验证对象的全部字段。这比单纯比较 id 的 equals 严格得多——它能捕获到 typeCounts、uploadedVideos 等新增字段的不一致。
使用 GLM 5.1 辅助生成测试数据和大规模随机测试脚本。AI 生成的测试框架能够覆盖大量边界组合,人工只需补充关键业务场景。
在三次作业迭代中,同一个方法在不同 spec 版本间的语义可能发生微妙变化。我的发现方法是:
diff 规格文件:逐行对比 NetworkInterface.java 在不同 spec 版本间的差异,圈出 requires/ensures/signals 的变化。
关注容器语义变化:例如 receivedVideos 从 HW9 的"不重复队列"演变为 HW10 的"允许重复队列"——这一变化体现在 uploadVideo 和 forwardVideo 的规格中。
回归测试:每次适配新版本前,先运行旧版本的测试用例,确认兼容性。
复杂度预估:实现前先估算最坏情况下的时间复杂度,标注在高频调用路径上。
评测机压力测试:编写 Python 脚本生成海量随机操作序列,观察运行时间。
热点分析:HW9 的 CPU TLE 就是通过本地压力测试发现的——queryMutualFollowingSum 的双重循环在用户数 > 1000 时性能急剧下降。
现象:强测超时
根因:queryMutualFollowingSum 全量双重循环遍历所有用户对,O(n²)
修复:改为 followUser/unfollowUser 时增量维护缓存
| Bug | 错误行为 | 正确行为 | 根因类型 |
|---|---|---|---|
addVideoToFront | 过滤重复/已看视频 | 无条件 addFirst | 额外假设 |
removeReceivedVideo | remove 单次移除 | removeAll 全部移除 | 方法语义误用 |
queryReceivedUnwatchedVideos | 用 watchedVideos 过滤 | 直接取前 5 个 | 画蛇添足的过滤 |
共同根因:没有严格遵循 JML 规格,而是凭借"我认为应该这样"的直觉添加了额外的业务逻辑。
规格理解:将 JML 片段输入 GLM,让其用自然语言解释规格含义,快速定位关键约束。
代码生成:基于自然语言描述生成基础方法骨架,人工调整后与 JML 逐行比对。
测试生成:GLM 生成的随机测试脚本覆盖了大量边界组合,极大提升了测试效率。
Bug 定位:将 JML 规格和有问题的实现一起提交,GLM 能快速指出实现与规格的不一致之处。
快速理解复杂规格:JML 的数学符号(\forall, \exists, \sum 等)对初学者有门槛,GLM 可以即时翻译为可读的自然语言。
生成测试框架:根据规格自动推导等价类和边界值,生成 JUnit 测试代码,减少人工遗漏。
反例调试:当实现与规格不符时,GLM 能指出具体的规格条款和实现行的对应关系。
不会主动考虑效率:GLM 生成的代码往往是最直白的"规格直译"版本,可能使用 O(n²) 算法。需要人工提醒它关注性能。
不会主动考虑架构:它倾向于把所有逻辑写在一个类里,而不是考虑如何拆分出辅助类、缓存策略等架构设计。
对容器选择的敏感度低:在需要 TreeSet 保持有序的场景,它可能给出 ArrayList + 手动排序的方案。
将 JML 规格的 requires/ensures 段直接作为 prompt 的一部分,要求模型:
为每个 signals 子句生成一个对应的异常测试
为 ensures 中的 \result 和 \old 表达式推导出具体的输入值
生成等价的自然语言描述以辅助理解
在研讨课上的"击鼓传花"环节,我发现自己写的 JML 存在两个问题:
前置条件遗漏:某个方法没有对 amount 的范围做约束,而自然语言需求中有明确说明。
后置条件过弱:只描述了"返回值正确",没有描述"方法执行后容器的状态变化"。
别人的 JML 也暴露了类似问题——尤其是多人写的规格之间不一致,同一个概念(如"已观看")在不同方法中的定义方式不同。
在传递过程中,需求确实在变化:
第一次传递时,需求是"将视频加入队列"(隐含不重复),第二次传递时澄清为"头部"(但不要求不重复)。
边界条件(如列表为空、id 不存在等)在不同人的实现中处理方式不同。
这让我深刻认识到:自然语言理解的偏差是不可避免的。即使同一个团队、同一个需求,不同人的理解也可能不同。
第三单元带给我的最大启示是:规格的精确性决定了软件质量的底线。在前两个单元中,错误往往表现为功能不正确或性能不达标;而在本单元中,错误表现为"规格违约"——程序运行正常,但内部状态不符合契约。这种错误更难发现,也更危险。
从 HW9 的 queryMutualFollowingSum 双重循环 CPU TLE → HW10 的 o 房翻车 → HW11 的 A 房逆袭,这条迭代曲线让我深刻理解了:
性能是可以度量的——只要做复杂度预估和压力测试,大部分性能问题都能在设计阶段发现。
规格是不可妥协的——任何"我觉得应该这样"的额外假设,都是潜在的 bug。
形式化方法是协作的基石——在多人协作中,JML 是唯一能消除自然语言歧义的沟通工具。
在接下来的单元中,我会继续坚持"规格驱动"的开发习惯,将 JML 的精确思维带入更复杂的系统设计中。

