


309
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享U3最终作业整体架构如下图所示:
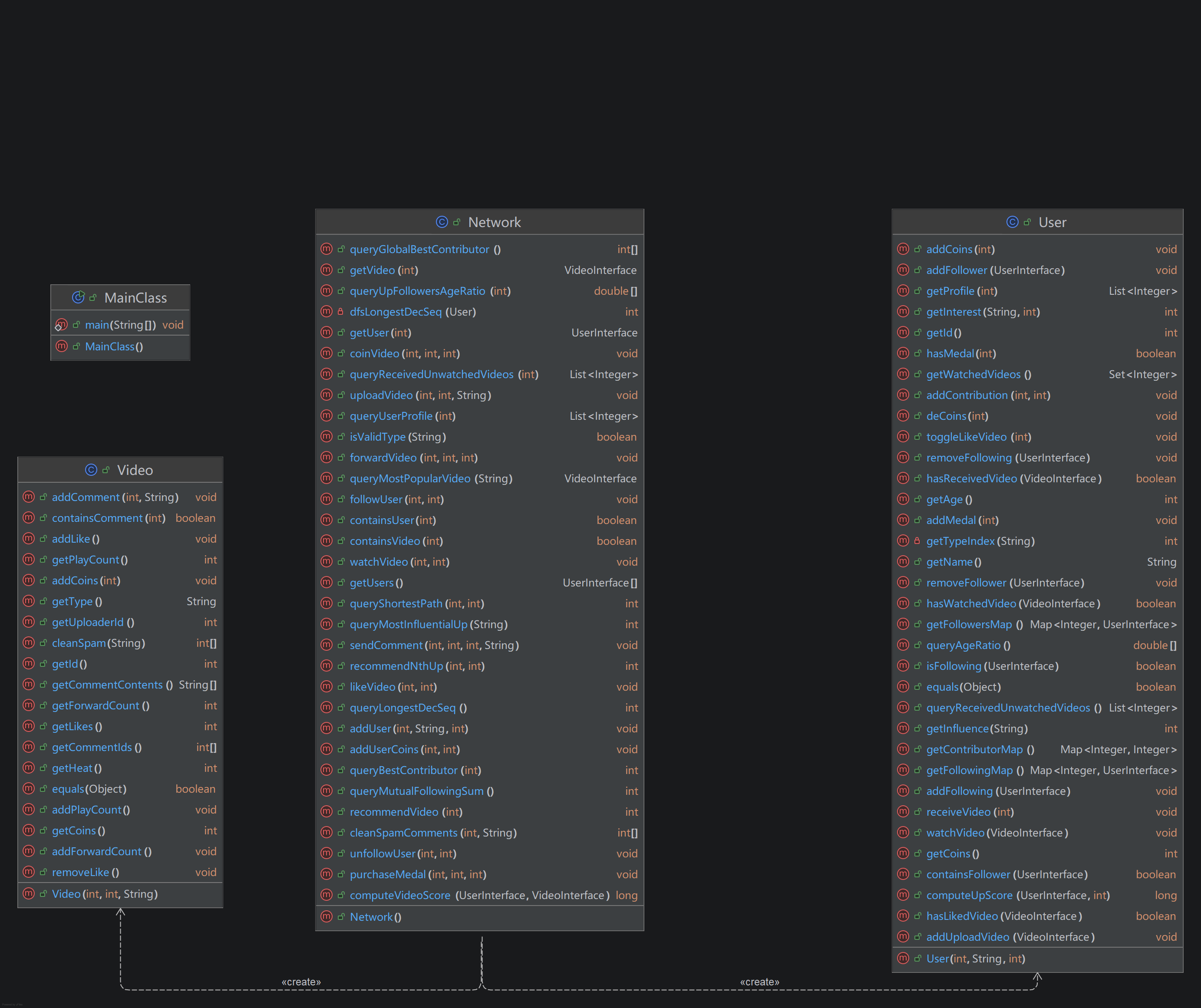
架构相比前两个单元简单太多了...
虽然思考设计架构难度降低了很多,但是依然有这个单元独有的难点
这个单元和之前最大的不同就是从 面向实现编程 变成了 面向规格编程,这其实也是我第一次真正接触到JML这类规格语言。
对JML的理解是它是一份调用者和实现者之间的契约,逻辑非常严谨。在写代码时如果用自然语言描述任务,很多需求会非常模糊,需要大量解释,像之前两个单元按照指导书完成代码时,讨论群总会有同学有各种各样的疑问。但是JML会明确规定要求,使得实现内容更加清晰。
JML明确规定了
requires,也就是调用者必须满足的条件assignable,是否能修改内部数据ensures,方法需要返回什么样的结果JML不对实现的具体方法作出要求,不关注实现方式,只是对需要满足的条件、实现的结果进行严格约束。
规格驱动开发让架构的职责切分变得更清晰了。
从实现者的角度出发,不需要再猜测这个方法的实际功能和应用场景,只需要满足所有的前置、后置、副作用条件就可以。
规格驱动开发一定程度上可以避免很多误解和歧义,也为单元测试提供了方向。(虽然我还是考虑不全面...)
本单元的Junit测试非常不顺利...第二次作业踩线提交了10次,第三次作业甚至超过了10次...后面大模型板块再进行展开,但也侧面说明写出一份全面的测试代码难度并不非常小(?)
部分心得如下:
hw11中,recommendNthUp(999, -1)这一个点,既满足用户不存在,应当抛UserIdNotFound,又满足名次非法,应当抛InvalidRank。如果只做单点测试,很容易漏掉代码中 if顺序写反的Bug。所以要对异常优先级做出全面的组合考虑测试pure相关测试pure这里屡战屡败QAQ,除去基本属性外每次都会漏掉一些其他属性导致无法通过。JML,执行待测方法前后记录下所有人的所有属性,依次进行断言对比。三次作业是从基础关系图搭建 到 引入经济与互动系统 再到引入推荐算法等
在第一次作业中,系统的核心只是一个纯粹的有向图结构。User包含了following和followers的HashMap,以及一个简单的ArrayList来存放收到的视频。
这一阶段的方法主要是图的基本操作,比如followUser、unfollowUser,以及一个基于BFS的queryShortestPath最短路查询。
此时数据量小,业务逻辑也比较简单。
第二次作业引入了经济、互动与复杂图查询等内容。Video增加了点赞、投币、转发、评论、热度等一系列属性;User增加了硬币、点赞列表、勋章等状态。
在此阶段,最大的架构变化发生在图算法的升级,新增了queryLongestDecSeq查询最长递减序列,促使我在代码中第一次引入了缓存架构。
第三次作业引入了各类评分机制,以及基于这些综合得分的推荐算法 recommendNthUp和recommendVideo。
此外,JML对旧有公式进行了微调,比如Video的getHeat计算公式改变且返回值从double变成了int。
在JML相关的迭代开发中,具体用什么容器,怎么写方法都需要仔细阅读JML描述和业务场景中的需求。
在我的代码中,变化主要体现在以下两点:
receivedVideos为例,在HW9中,我最初使用private List<Integer> receivedVideos = new ArrayList<>(); 来存储用户收到的视频,因为当时只涉及简单的末尾添加。HW10,阅读JML后发现,receiveVideo明确要求新视频必须放在列表最前面,而且watchVideo需要频繁地删除特定视频,同时伴随大量contains查询。HW10和HW11中,将其改变为了private final LinkedList<Integer> receivedVideosList;和private final Set<Integer> receivedVideosSet; 前者用于O(1)的头部插入和维持顺序;后者用于O(1)的去重和存在性校验Heat为例,HW10中,getHeat() 的公式带有浮点数,返回值是double。但在HW11,JML更新了公式,全变成了整数权重,且明确需要返回int。diff比对两次JML可以及时发现了这一变化进行修正。由于JML不关注实现方式,只是对需要满足的条件、实现的结果进行严格约束,所以如果只是简单地直接翻译JML,很容易出现超时等问题导致无法通过测试。
发现性能瓶颈主要靠时间复杂度分析和对指令频度的预判。
HW10中需要实现queryLongestDecSeq来求最长年龄递减序列,这是有向图中寻找最长路径的问题。如果用单纯的DFS,当图极度稠密时,时间复杂度会非常大。Network中使用了记忆化搜索数组longestDecSeqMemo。在DFS遍历时,一旦某个节点的最长序列已经算过,就直接return,大大降低复杂度。DFS,即使有记忆化也依然费时。addUser新增用户、没有改变关注关系,最长序列结果就不会改变。所以在Network中使用了脏标记缓存系统。private int cachedLongestSeq = -1; private boolean isGraphDirty = true;在测试中没有发现别人的bug,自己也没有被测试出bug。
在HW10时第6个测试点曾经有CTLE,不过重新测试之后通过了测试点。课上听了关于KMP为什么没有凸显出优势的讲解,有了一些收获。
课下自己实现代码的时候遇到过一些小小的问题:
Network.java中处理uploadVideo指令时,只把视频放进了全局的videosMap里,忘记调用uploader.addUploadVideo(video),导致后续统计该用户影响力时,名下的视频列表永远为空。(蠢蠢的...)receiveVideo时莫名其妙多写了一行receivedVideosList.add(videoId),导致每次存入都被加了两次。后续清理或排序时都会出问题。(这个听起来更蠢...)本次作业主要使用的是gemini pro进行辅助,没有尝试Code Agent
优势
大模型在编写src时优势很明显,因为JML本身严谨的写法就很适合给AI理解,所以大模型会对上百行的JML快速给出自然语言的对应功能,能大大加快我对于每个方法功能的理解。
另外只要提示词中加上“注意时间复杂度以及性能”等等要求,大模型会采用较为合理的架构和算法,并不会导致大幅超时等问题。
缺点
缺点是对test相关功能的撰写。大模型会快速给出一版看似正确的代码,但是如果按照大模型给出的实现通常无法通过全部的test case。大模型对于pure等关键字的检查往往不够全面,会漏掉很大一部分,数据也往往不够强,有时会出现修改后正确错误情况相同导致误判的情况。
在test方面依赖大模型给出的结果大大增加了提交次数,在最后一个单元我一定会注意批判性地使用大模型QAQ...
然而...在第一位同学翻译给定
int型数组,输出数组中元素大小位于u和2u之间的元素总数,其中u为平均数。
JML的时候就把u为平均数的条件丢掉了,导致后面所有人都少传了一部分,如果是在实际应用中感觉平均数应该会是一个很重要的条件但是我在翻译输入一个数
x,保证x是正整数且在int范围内,后面对x做一些操作。
JML的时候只写了大于0和小于整数最大值的条件,并没有在前提条件明确x是整数,导致了部分条件的缺失基本上每一道题都发生了或多或少的变化。
但是有一道题印证了JML语言比自然语言更具有严谨性
自然语言是
在
u和2u之间,
但是由于JML要写出具体的符号,所以“中间”就变成了更清晰的$\ge$和$\le$ ,虽然语义边界发生了一些变化,但是需求确实更清晰了。也许是比自然语言更严谨的体现。
不能依靠纯口头或模糊的自然语言来交代需求。
Review:开发前必须先把抽象接口和规格以类似JML的形式定死。任何人在实现具体类之前,双方必须就前后置条件进行交叉Review。第一次接触到JML其实还蛮新奇的,读JML莫名有种破译密码的感觉,从每个约束条件中读懂这个方法到底想做什么。
刚开始面对一长串数学符号的JML会感觉难以下手,但习惯之后,发现这种开发模式很有安全感。只要我的代码符合了JML,暂且不考虑性能,它的正确性大概是没问题的,不用像上单元那样总是担心会有太空电梯凭空出现...
但是相比读懂来说自己写感觉就困难很多,总是会漏掉一部分约束条件。
深深的话我们浅浅地说,
长长的路我们慢慢地走。
感谢U3所有老师和助教的辛苦付出~

