社区
Spark
帖子详情
为什么spark sql有些任务特别慢?基本同样的input和shuffle数据量,大多数任务不到10几分钟就结束了,但有几个任务要30分钟以上?
flyaga
2017-10-08 11:40:03
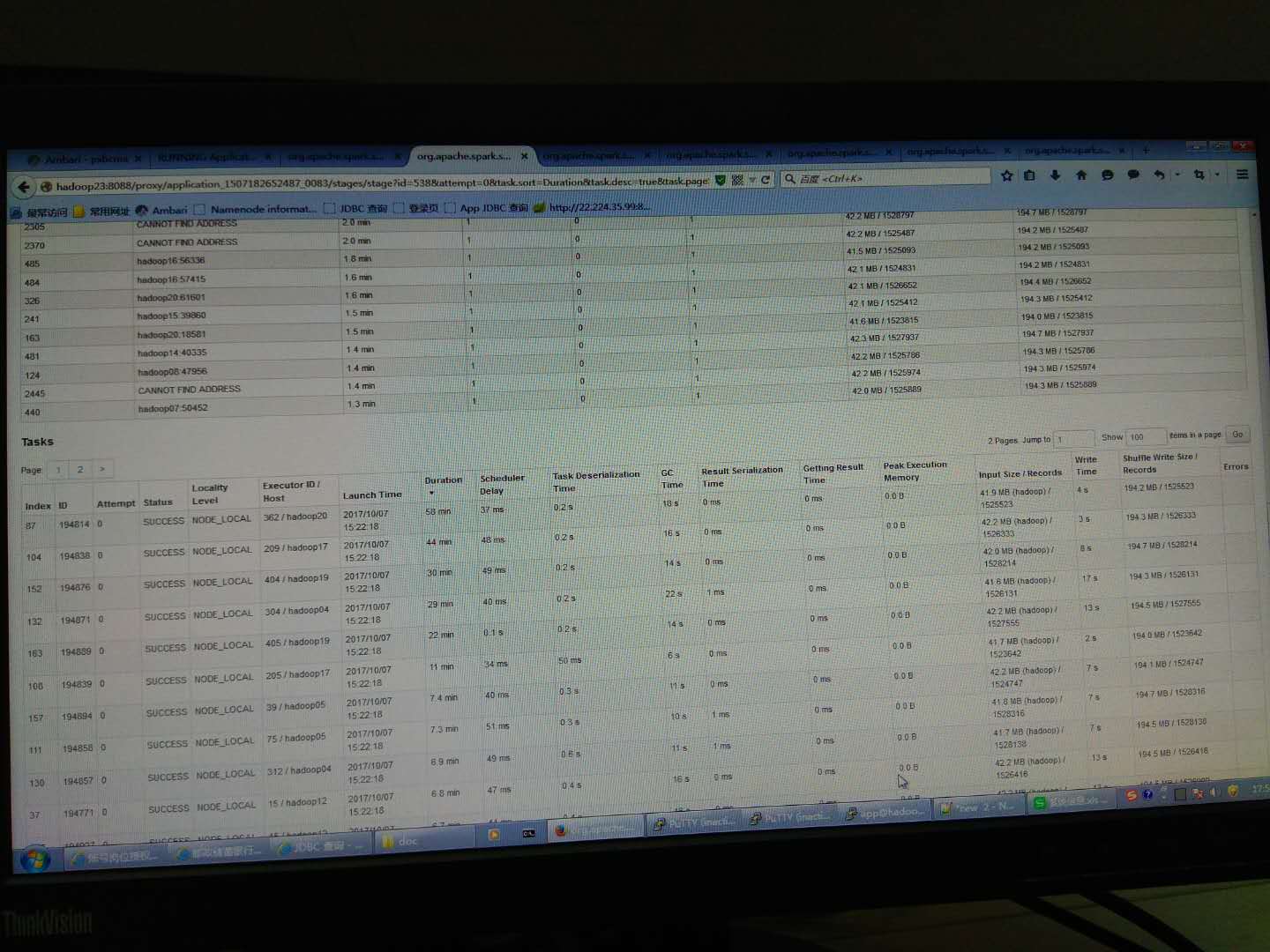
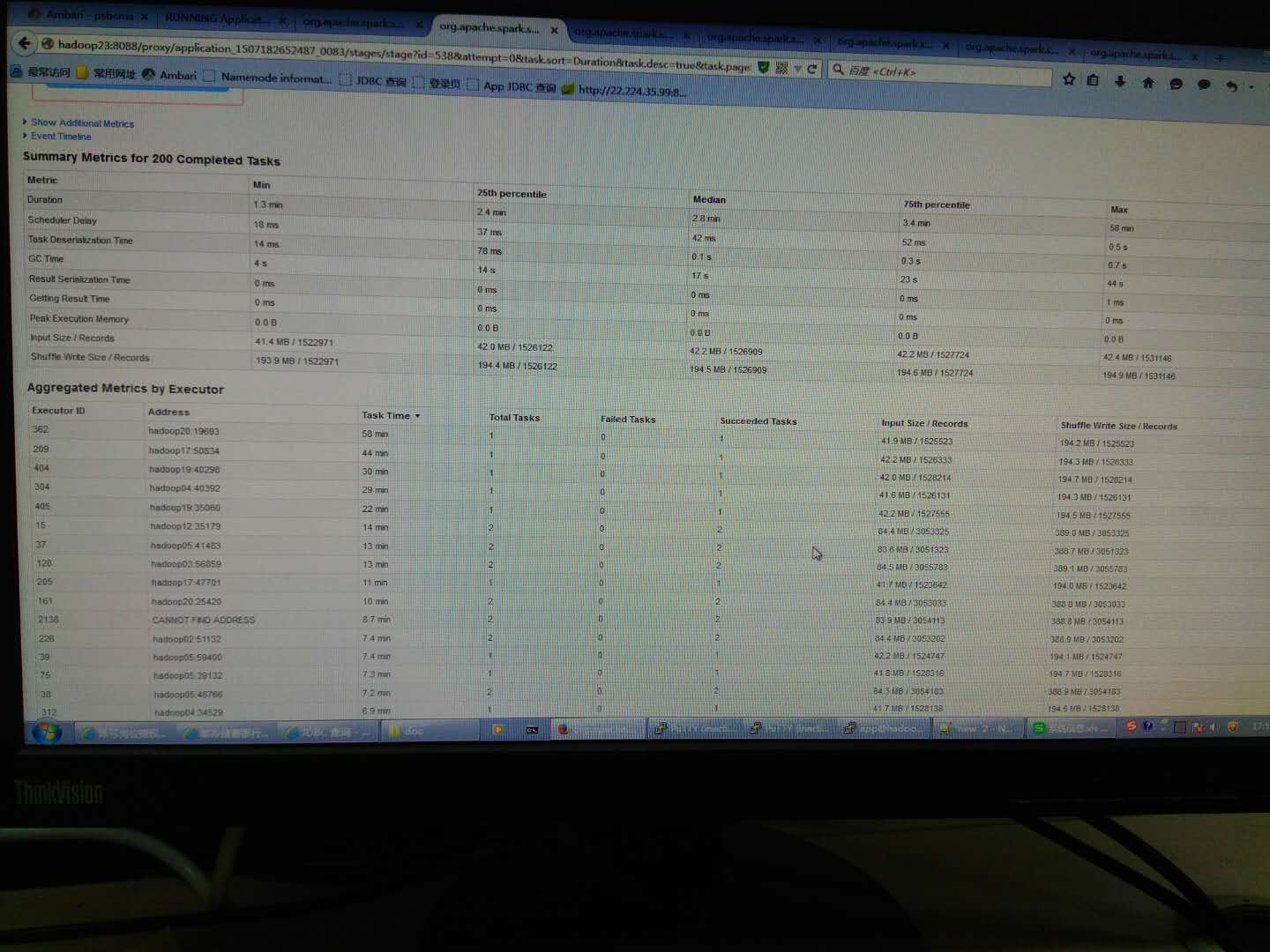
为什么spark sql有些任务特别慢?基本同样的input和shuffle数据量,大多数任务不到10几分钟就结束了,但有几个任务要30分钟以上,有个还要快1小时,GC时间都差不多。应该不是数据倾斜,因为任务的数据量都差不多。
我用的是spark 1.6,yarn-client模式,通过spark thrift server运行sql跑批。
请各位大神分析分析,在此谢过!
...全文
1274
4
打赏
收藏
为什么spark sql有些任务特别慢?基本同样的input和shuffle数据量,大多数任务不到10几分钟就结束了,但有几个任务要30分钟以上?
为什么spark sql有些任务特别慢?基本同样的input和shuffle数据量,大多数任务不到10几分钟就结束了,但有几个任务要30分钟以上,有个还要快1小时,GC时间都差不多。应该不是数据倾斜,因为任务的数据量都差不多。 我用的是spark 1.6,yarn-client模式,通过spark thrift server运行sql跑批。 请各位大神分析分析,在此谢过!
复制链接
扫一扫
分享
转发到动态
举报
写回复
配置赞助广告
用AI写文章
4 条
回复
切换为时间正序
请发表友善的回复…
发表回复
打赏红包
flyaga
2017-10-10
打赏
举报
回复
到最慢机器上查cpu很空闲,很奇怪
flyaga
2017-10-09
打赏
举报
回复
谢谢,现在是一个executor4个核,自动分配executor,分区没有设置。接下来,会试试一个executor一个核,看是否有改
flyaga
2017-10-09
打赏
举报
回复
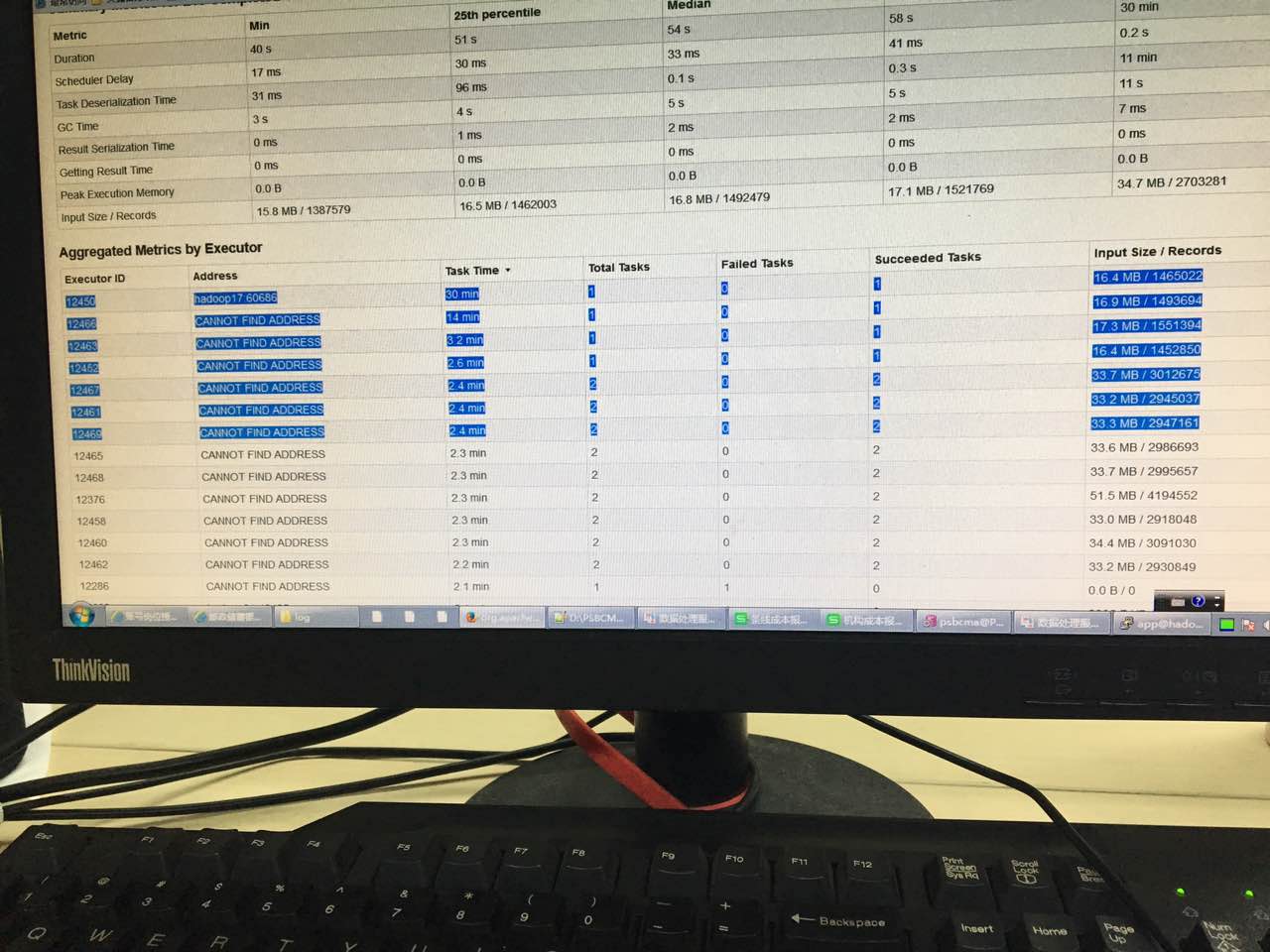
改成一个executor一个核后,分区没有设置,情况还是一样,见下图,多数不到4分钟完成,有一个30分钟
卡奥斯道
2017-10-08
打赏
举报
回复
查看一下CPU利用率 job,有的特别慢,查看CPU利用率很低,我们就尝试减少每个executor占用CPU core的数量,增加并行的executor数量,同时配合增加分片,整体上增加了CPU的利用率,加快数据处理速度。 推荐个文章,可以参考一下,可能会帮助你 http://blog.csdn.net/kaaosidao/article/details/78174413
Spark
SQL
生产优化经验--
任务
参数配置模版
特殊case说明:当
任务
存在扫event_log表时需注意,若对event_log表进行了过滤,且过滤比很高,如下图的case,
input
为74T,但
shuffle
write仅为3.5G,那么建议提高单partition的读取
数据量
,将参数set
spark
.
sql
.files.maxPartitionBytes=536870912提高
10
倍至5368709120;目前测试:在不手动添加任何参数、平均时长在90min以内、单个
shuffle
量在2T以下的
任务
可以使用该模版,但实际
任务
情况还需跟踪观察。
大数据开发面筋之
慢
SQL
及数据倾斜问题及解决方案
Spark
-
慢
SQL
问题 1. 错误的使用低性能函数 2. 数据倾斜 一、错误使用低性能函数 案例1: 在对某个表流量上报字段判断是否包含SKU, 使用正则(.*?)+加其他正则联合匹配,导致本来
几
分钟
能跑完
SQL
跑
几个
小时 发现:
Spark
某个Stage 单task
input
特别
慢
定位: 查看
input
阶段 filter 操作都有哪些,最终找到正则 问题本质:谓词下推 解决方案: 1. 在使用正则之前,提前对这个字段进行 is not null 进行过滤,减少大量无效数据,在进行正则【提升90
spark
入门学习:
spark
SQL
Spark
SQL
是用于结构化数据处理的
Spark
模块。与
基本
的
Spark
RDD API不同,
Spark
SQL
提供的接口为
Spark
提供了有关数据结构和正在执行的计算的更多信息。在内部,
Spark
SQL
使用这些额外的信息来执行额外的优化。与
Spark
SQL
交互的方式有多种,包括
SQL
和Dataset API。计算结果时,使用相同的执行引擎,与您用于表达计算的API/语言无关。为什么要有
SPARK
SQL
:1)发展历史。
一文搞清楚
Spark
shuffle
调优
Spark
shuffle
调优
Spark
基于内存进行计算,擅长迭代计算,流式处理,但也会发生
shuffle
过程。
shuffle
的优化,以及避免产生
shuffle
会给程序提高更好的性能。因为
shuffle
的性能优劣直接决定了整个计算引擎的性能和吞吐量。 下图是官方的说明,1.2 版本之后默认是使用 sort
shuffle
。这样会更加高效得利用内存。之前版本默认是 hash s...
Spark
sql
数据倾斜解决
一次数据查询,简单的表关联,在某个stage 长时间running 查看
Spark
ui ,发现 两阶段
input
size 相差巨大,有明显数据倾斜 解决: 其中一个表为维度表,
数据量
较小考虑 提供map join 判断阀值 set
spark
.
sql
.autoBroadcastJoinThreshold = 83886
10
00; 提高广播表的大小,适当牺牲空间换查询性能, set spar...
Spark
1,275
社区成员
1,171
社区内容
发帖
与我相关
我的任务
Spark
Spark由Scala写成,是UC Berkeley AMP lab所开源的类Hadoop MapReduce的通用的并行计算框架,Spark基于MapReduce算法实现的分布式计算。
复制链接
扫一扫
分享
社区描述
Spark由Scala写成,是UC Berkeley AMP lab所开源的类Hadoop MapReduce的通用的并行计算框架,Spark基于MapReduce算法实现的分布式计算。
社区管理员
加入社区
获取链接或二维码
近7日
近30日
至今
加载中
查看更多榜单
社区公告
暂无公告
试试用AI创作助手写篇文章吧
+ 用AI写文章


 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享