求大佬解惑,想在hadoop上集成keycloak的身份验证,不知道如何下手,在网上也找不到资料
社区首页 (3662)
 我加入的社区 我管理的社区 官方推荐社区
76
其他社区
3662
我加入的社区 我管理的社区 官方推荐社区
76
其他社区
3662
请编写您的帖子内容
社区频道(9)
显示侧栏
卡片版式
全部
运营指南
问题求助
交流讨论
学习打卡
社区活动
博文收录
Ada助手
活动专区
最新发布
最新回复
标题
阅读量
内容评分
精选

247
评分
回复


求大佬解惑,想在hadoop上集成keycloak的身份验证,不知道如何下手,在网上也找不到资料
hadoop的版本是3.3.6,keycloak是docker上直接拉的18.0的镜像,找ds问ds给的方案是在core-site.xml里面加上像下面的配置,但是加上后就启动不了hadoop了,还显示Starting datanodes local
复制链接 扫一扫
分享
问题求助

472
评分
1

寻求大佬帮助,关于虚拟机安装win7系统后无法开机问题的解决办法
安装好win7系统之后本因该进入系统设置的界面,但是虚拟机就直接关机了,试过不同的镜像文件,应该不是iso的问题,安装过程的设置是常规问题,因该也没有问题,后面就不知道这么办了,想请教大家寻求解决办法
复制链接 扫一扫
分享
问题求助

850
评分
1

泛微OA如何修改浏览框字段的值?
是否解密字段为’是‘,则使用地点只保留一个值,其余值隐藏。当解密字段为’否‘,则全部展示。
复制链接 扫一扫
分享
问题求助
465
评分
回复

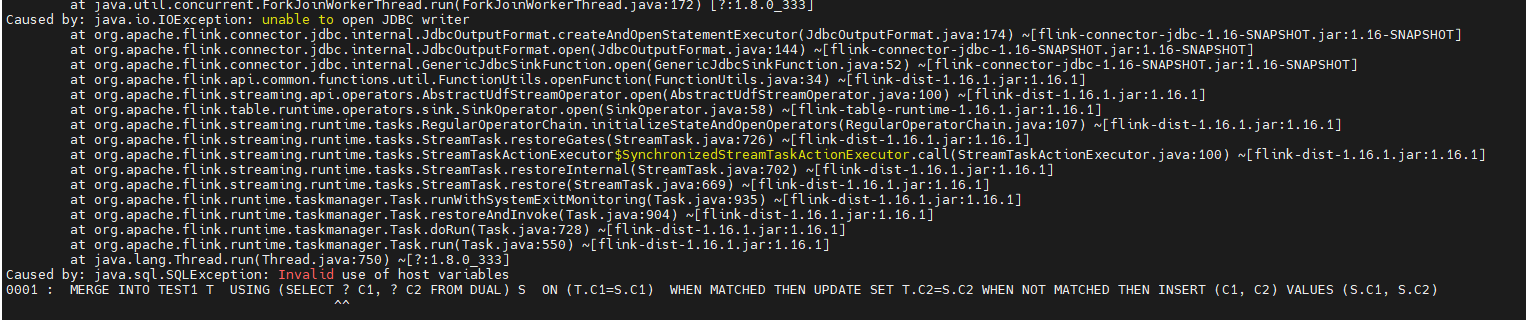
Flink修改flink-connector-jdbc增加数据库支持,打包测试遇到问题
因为数据库同Oracle的相类似,就根据flink-connector-jdbc里Oracle相应的方法修改别的数据库的jdbc方法,但是在测试时报错Caused by: java.sql.SQLException: Invalid use of h
复制链接 扫一扫
分享
问题求助

790
评分
回复

 复制链接
复制链接 扫一扫
分享
运营指南

朋友们,这周我又上了作者周榜了啊!
[图片]
...全文
389
评分
回复
朋友们,这周我又上了作者周榜了啊!
[图片]
复制链接 扫一扫
分享
交流讨论

547
评分
回复
成功解决Impala中修改parquet表的字段类型问题
最近有个小伙伴在开发中遇到了Impala中修改Parquet表的字段类型问题,于是开启了问题解决之路。上述解决方案并不是真正的对Parquet进行修改字段类型和删除字段,只是新建了一张修改好的新表,然后把原来表的数据以动态分区的方式导入到删表重建的新表中。因为Parquet是在存储上,做了加密,二级制存储压缩,不可以修改的,包括去Hive中执行也是不行的!
复制链接 扫一扫
分享
学习打卡

389
评分
回复
了解了ChatGPT对编程语言的影响后,决定让AI给自己打工!
介绍ChatGPT是一种基于自然语言处理技术的语言模型,由美国OpenAI团队研发。它是构建在生成式预训练变换模型(Generative Pre-trained Transformer,简称GPT)之上,具有强大的自然语言理解和生成能力。GPT模型以大规模文本数据为输入进行训练,从而学习到了丰富的语言知识和语义理解能力。它可以根据聊天的上下文生成自然、流畅、有逻辑的回复,并能进行多轮对话。ChatGPT是一种通用的,生成式的人工智能。具体是说ChatGPT不限定领域并且在理解的基础上生成新的内容。
复制链接 扫一扫
分享
交流讨论

387
评分
回复
人大某硕士盗取全校学生信息已被刑拘,请警惕法律红线!
我个人觉得技术确实很牛逼,但是当你把用技术手段去做了这样的事情,并且把网址公开出来,这个事情就变了性质,最终会为自己的行为付出代价,这不,代价这就来了!也算是给各位拥有技术的程序员敲响了警钟!违法犯罪必将严惩,请谨之慎之!某天早上在新华网看到下面这条信息,真是大快人心!我查了一下,居然还上了热搜!
复制链接 扫一扫
分享
交流讨论

548
评分
回复
听说第一批“让AI给自己打工”的人,已经月入10万了
ChatGPT,一场革命性的技术变革,AIGC 正以史诗级的气势席卷全球,这个概念模糊的新词汇,究竟意味着什么?它将对行业格局带来怎样的影响?教育、经济、就业,未来会受到何种冲击?投资界如何看待大模型技术的崛起?对于想加入到AIGC大潮中的创业者来说
复制链接 扫一扫
分享
交流讨论

402
评分
回复
Spark——成功解决java.util.concurrent.TimeoutException: Futures timed out after [600 seconds]
最近真是和Spark任务杠上了,业务团队说是线上有个Spark调度任务出现了广播超时问题,根据经验来看应该比较好解决。在进行Spark 任务开发中需要合理配置和参数,并配合,使作业能够顺利执行。
复制链接 扫一扫
分享
问题求助


博主《笑看风云路》的微信公众号
[图片]
...全文
696
评分
回复

博主《笑看风云路》的微信公众号
[图片]
复制链接 扫一扫
分享
运营指南

487
评分
回复
博主《笑看风云路》的联系方式
账号介绍:CSDN博客专家、大数据领域优质创作者,全网粉丝1.5w+,拥有千人社区,推广效果极好 合作类型(诚信长期合作价格可谈): 1、供稿子代发,按粉丝量计算(CSDN博主报价一般为:1万粉丝/300元),目前账号1.5万粉丝,报价在400元
复制链接 扫一扫
分享
运营指南

384
评分
回复
Mapreduce实例(七):单表join
MR实现单表join
复制链接 扫一扫
分享
学习打卡
403
评分
回复
Mapreduce实例(八):Map端join
MR实现Map端join
复制链接 扫一扫
分享
学习打卡

391
评分
回复
Mapreduce实例(九):Reduce端join
MR实现Reduce端join
复制链接 扫一扫
分享
学习打卡

417
评分
回复
Mapreduce实例(十):ChainMapReduce
MR实现ChainMapReduce
复制链接 扫一扫
分享
学习打卡

539
评分
回复
Hadoop知识点总结——HDFS小文件过多问题、解决方法
每个文件均按块存储,每个块的元数据存储在NameNode的内存中,因此HDFS存储小文件会非常低效。因为大量的小文件会耗尽NameNode中的大部分内存。每个小文件都会对应启动一个MapTask,1个MapTask默认内存1G,造成资源浪费。HDFS存档文件或HAR文件,是一个更高效的文件存档工具,它将文件存入HDFS块,在减少NameNode内存使用的同时,允许对文件进行透明的访问。具体说来,HDFS存档文件对内还是一个一个独立文件,对NameNode而言却是一个整体,减少了NameNode的内存。Com
复制链接 扫一扫
分享
学习打卡

408
评分
回复
Hadoop知识点总结——数据倾斜解决方法
在Mapper加上combiner相当于提前进行reduce,即把一个Mapper中的相同key进行了聚合,减少shuffle过程中传输的数据量,以及Reducer端的计算量。第一次在map阶段对那些导致了数据倾斜的key 加上随机前缀,这样本来相同的key 也会被分到多个Reducer中进行局部聚合,数量就会大大降低。第二次mapreduce,去掉key的随机前缀,进行全局聚合。思想:二次mr,第一次将key随机散列到不同reducer进行处理达到负载均衡目的。第二次再根据去掉key的随机前缀,按原k
复制链接 扫一扫
分享
学习打卡
为您搜索到以下结果:
6,217
社区成员
80
社区内容
 发帖
发帖 与我相关
与我相关 我的任务
我的任务 
风云大数据
专注于分享大数据相关技术,包括Hadoop、Spark、Flink、Kafka、Hive、 HBase等,社区人员均可提出编程中遇到的疑难杂症、程序bug等等问题,博主看到后会及时回答!
复制链接 扫一扫
 分享
分享确定
社区描述
专注于分享大数据相关技术,包括Hadoop、Spark、Flink、Kafka、Hive、 HBase等,社区人员均可提出编程中遇到的疑难杂症、程序bug等等问题,博主看到后会及时回答! hivesparkflink 个人社区 北京·顺义区
社区管理员
加入社区
获取链接或二维码

- 近7日
- 近30日
- 至今
加载中
社区公告
暂无公告