



17
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享DolphinDB和MongoDB都是为大数据而生的数据库。但是两者有这较大的区别。前者是列式存储的多模型数据库,主要用于结构化时序数据的高速存储、查询和分析。后者是文档型的NoSQL数据库,可用于处理非结构化和结构化的数据,可以根据键值快速查找或写入一个文档。MongoDB有着自己最合适的应用场景。但是市场上缺少优秀的大数据产品,不少用户试图使用MongoDB来存储和查询物联网和金融领域的结构化时序数据。本测试的目的是评估MongoDB是否适合此类海量时序数据集。
时间序列数据库DolphinDB和MongoDB在时序数据库集上的对比测试,主要结论如下:
本次测试在单机上进行,测试设备配置如下:
主机:DELL OptiPlex 7060
CPU:Intel(R) Core(TM) i7-8700 CPU@3.20GHZ,6核12线程
内存:32 GB (8GB x 4, 2,666 MHz)
硬盘: 2T HDD (222MB/s读取;210MB/s写入)
OS:Ubuntu 18.04 LTS
DolphinDB选用Linux0.89作为测试版本,所有节点最大连接数为128,数据副本设置为2,设置1个控制节点,1个代理节点,3个数据节点。
MongoDB选用Linux4.0.5社区版作为测试版本,shard集群线程数为12,所有服务器的最大连接数均为128。MongoDB的shard集群设置为1个config服务器,1个mongos路由服务器,3个分片服务器,其中config服务器设置为有1个主节点和2个从节点的replica集群,3个分片服务器均设置为有1个主节点,1个从节点,1个仲裁节点的replica集群。DolphinDB和MongoDB的参数配置请参考附录1。
本报告测试了DolphinDB和MongoDB在小数据量级(4.2GB)和大数据量级(62.4GB)下的性能。
对于大小两种数据集,我们测试两种数据库在磁盘分区情况下的性能,查询时间均包含了磁盘IO的时间。为了保证测试的公平,我们在测试前通过linux命令:sync,echo1,2,3 | tee /proc/sys/vm/drop_caches清空页面缓存,目录缓存和硬盘缓存,随后依次执行13条查询,并记录执行的时间。
以下是两个数据集的表结构和分区方法:
设备传感器信息小数据集(CSV文件,4.2G, 3千万条数据)
我们选用TimescaleDB官网提供的devices_readings_big.csv(以下简称readings数据集)和device_info_big.csv(以下简称info数据集)设备传感器数据作为小数据测试集。readings数据集包含3,000个设备在10,000个时间间隔(2016.11.15-2016.11.19)上的传感器信息,包括传感器时间,设备ID,电池,内存,CPU等时序统计信息。info数据集包括3,000个设备的设备ID,版本号,制造商,模式和操作系统等统计信息。
数据来源:https://docs.timescale.com/v1.1/tutorials/other-sample-datasets
数据集共3千万 条数据(4.2G),压缩包内包含一张设备信息表和一张设备传感器信息记录表,表结构以及分区方式如下:
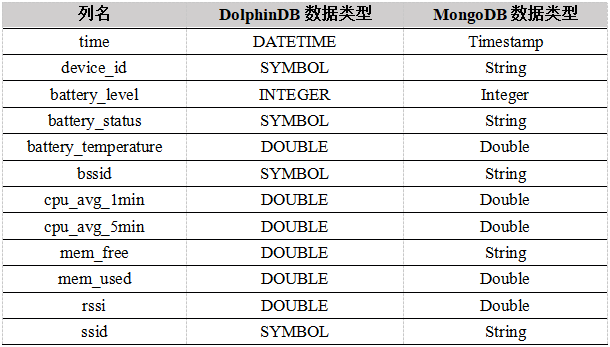
readings数据集
info数据集
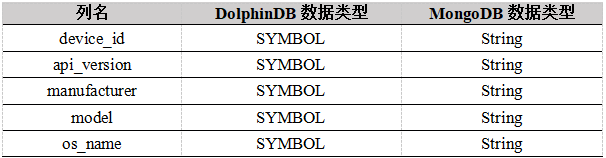
数据集中device_id这一字段有3000个不同的值,且在readings数据集中重复出现,这种情况下使用string类型不仅占用大量空间而且查询效率低,DolphinDB的symbol类型可以很好地解决占用空间和效率两个问题。
我们在 DolphinDB database 中采用组合分区,将time字段作为分区的第一个维度,按天分为 4 个区,再将device_id作为分区的第二个维度,每天一共分 10 个区,最后每个分区所包含的原始数据大小约为100MB。
我们在MongoDB中同样采用组合分区的方式,将time作为分区的第一维度,根据日期进行范围分区,再将设备ID作为第二分区维度,根据设备ID进行范围分区。MongoDB的范围分区是根据块的大小进行分区的,当数据块大小大于某个阈值,数据库会自动将一个大的数据块分为两个小的数据块,实现分区。经过测试,我们发现当chunkSize(数据块分区阈值)为1024时,性能最佳。最终,readings数据集总共分为17个分区。
MongoDB要求分区字段必须建立索引,因此我们建立日期+设备ID的复合索引,复合索引可以加快查询速度,但是MongoDB在建立索引时会消耗时间和空间。readings数据集分区建立time_1_device_id_1增序索引耗时为5分钟,占用空间大小为1.1G。建立索引的脚本如下所示:
use device_pt
db.device_readings.createIndex({time:1,device_id:1}
股票交易大数据集(CSV文件,62.4G,16亿条数据)
我们选用纽约证券交易所(NYSE)提供的2007.08.07-2007.08.10四天的股市Level1报价数据(以下简称TAQ数据集)作为大数据测试集,数据集包含8,000多支股票在4天内的交易时间,股票代码,买入价,卖出价,买入量,卖出量等报价信息。
数据集有4个csv文件,每个文件在14G到17G之间,总共大小为62.4G,大约16亿条数据,每个CSV文件保存一个交易日的交易信息,数据来源于(https://www.nyse.com/market-data/historical)。TAQ数据集结构如下所示:
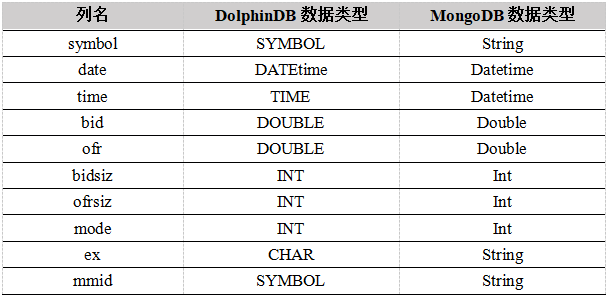
在DolphinDB中,我们采用组合分区,将date字段作为分区的第一维度,每天一个分区,共四个分区,再将symbol字段作为分区的第二维度,根据范围分区,每天分为100个分区。最后总共分为400个分区,每个分区大约40MB。
在MongoDB中同样采用组合分区方式,分区维度与DolphinDB相同,将chunkSize设置为1024,总共分为385个分区。
MongoDB在对TAQ数据集分区时建立date_1_symbol_1增序索引消耗的时间为53分钟,占用空间大小为19G,建立索引的脚本如下所示:
use taq_pt_db
db.taq_pt_col.createIndex({date:1,symbol:1}
3.1 导入性能
在DolphinDB中使用以下脚本导入:
timer {
for (fp in fps) {
job_id_tmp = fp.strReplace(".csv", "")
job_id_tmp1=split(job_id_tmp,"/")
job_id=job_id_tmp1[6]
job_name = job_id
submitJob(job_id, job_name, loadTextEx{db, `taq, `date`symbol, fp})
print now() + ": 已导入 " + fp
}
getRecentJobs(size(fps))
}
在MongoDB导入TAQ数据集时,为了加快导入速度,将63G的数据分为16个小文件导入,每个文件大小在3.5G~4.4G之间,然后使用以下脚本导入:
for f in /media/xllu/aa/TAQ/mongo_split/*.csv ; do
/usr/bin/mongoimport \
-h localhost \
--port 40000 \
-d taq_pt_db \
-c taq_pt_col \
--type csv \
--columnsHaveTypes \
--fields "symbol.string(),date.date(20060102),time.date(15:04:05),bid.double(),ofr.double(),bidsiz.int32(),ofrsiz.int32(),mode.int32(),ex.string(),mmid.string()" \
--parseGrace skipRow \
--numInsertionWorkers 12 \
--file $f
echo "文件 $f 导入完成"
done
导入性能如下表所示:

从上表可得,DolphinDB在导入结构化的时序数据时,速度远快于MongoDB,下面从几个方面分析导入结果。
(1)横向比较
由于两个数据集的字段数量和字段类型不一样,readings数据集多为字符串类型,TAQ数据集多为数值类型,相比于字符串类型,数值类型导入更快,因此可以看到MongoDB和DolphinDB在导入TAQ数据集时,速率更快。
(2)纵向比较
MongoDB属于文档型数据库,导入速度受文档数量的影响很大,可以看出导入3千万条记录大约需1小时,导入16亿条记录大约需55小时,记录条数相差大约53倍,导入时间相差约55倍,考虑到每条记录字段类型和数据的影响,可以认为导入速度和记录条数大约成正比。
DolphinDB属于列式数据库,存储这种结构化的数据时,DolphinDB会将一个字段当成一个列,存储在一个列文件中。导入readings数据集时创建了12个列文件,导入TAQ数据集时,创建了10个列文件,列文件数量相差不多。导入4.2G数据,需要63秒,导入62.4G数据,需要11分30秒。数据集大小相差大约14.8倍,导入时间相差大约11倍,考虑到列文件数量和存储类型的不同,可以认为导入时间和文件大小大约成正比。
DolphinDB在导入时序结构化数据时,在列字段类型和数量相差不大的情况下,导入时间和文件大小成正相关,符合列式存储数据库的特点。MongoDB在导入时序结构化数据时,在字段相差不大的情况下,导入时间和记录条数成正相关,符合文档型存储数据库的特点。
(3)MongoDB导入相对缓慢的原因分析
DolphinDB采用列式存储,效率远远高于MongoDB的文档型存储。MongoDB按照记录逐条导入,在记录条数很大的情况下,MongoDB数据导入时长增加,性能下降。
MongoDB在sharding集群配置时,必须开启journaling日志,先写入记录再进行导入操作,降低了其导入速度。
因为MongoDB属于NoSQL数据库,其没有主键概念,为了保证唯一性约束,数据在导入时必须创建一个数据库自动生成的唯一索引来表征每一条记录,数据导入和索引必须同时进行,因此降低了导入速度。
3.2 导出性能
在DolphinDB中使用以下脚本进行数据导出:
timer saveText((select * from t),"/media/xllu/aa/device/device_readings_out.csv")
在MongoDB中使用以下脚本进行数据导出:
mongoexport -h localhost:40000 -d db_nopt -c device_readings -o /media/xllu/aa/device/
device_readings_mongo_out.csv
小数据集导出性能如下表所示:

数据库磁盘空间占用性能对比主要对比DolphinDB和MongoDB数据库导入readings数据集和TAQ数据集这两种大小的数据集后,在分区情况下各数据库中的数据所占磁盘空间的大小。磁盘占用指标为数据在磁盘中的大小。
DolphinDB直接通过读取所有列式数据文件的大小获取,MongoDB通过db.stats()获得数据存储的大小。两个数据库均有一个备份,MongoDB中数据存储大小还包括索引的大小。测试结果如下表所示:

相同数据量,MongoDB的磁盘占用空间大约是DolphinDB的2~3倍,主要有以下原因:
(1)DolphinDB采用列式存储方式,每个列有固定的类型,通过LZ4压缩算法,将每个字段按照类型压缩存储为一个列文件。并且针对symbol类型,还采用位图压缩算法解决存储空间占用的问题,进一步提高了压缩率。MongoDB本次测试采用的是WiredTiger存储引擎,选用snappy压缩算法。
(2)MongoDB中建立分区数据库均要对分区字段建立索引,进一步导致其存储空间变大,经分析发现,readings数据集对time和device_id字段建立的索引大小为1.1G,TAQ数据集对date和symbol字段建立的索引大小为19G。
对于readings数据集和TAQ数据集,我们对比了以下8种常用的SQL查询。
1、点查询:根据某一字段的具体值进行查询。
2、范围查询:根据一个或者多个字段的范围根据时间区间进行查询。
3、聚合查询:根据数据库提供的针对字段列进行计数,平均值,求和,最大值,最小值,标准差等聚合函数进行查询。
4、精度查询:根据不同标签维度列进行数据聚合,实现高维或者低维的字段范围查询,测试有hour精度,minute精度。
5、关联查询:根据不同的字段,在进行相同精度,相同的时间范围内进行过滤查询的基础上,筛选出有关联关系的指标列并进行分组。
6、对比查询:根据两个维度将表中某字段的内容重新整理为一张表格(第一维度作为列,第二维度作为行)
7、抽样查询:根据数据库提供的数据采样API,可以为每一次查询手动指定采样方式进行数据的稀疏处理,防止查询时间范围太大数据量过载的问题。
8、经典查询:实际业务中常用的查询。
执行时间是以毫秒为单位的。为了消除网络传输等不稳定因素的影响,查询性能比较的时间指标为服务器执行某个查询的时间,不包括结果传输和显示的时间。
4.2G设备传感器信息小数据集查询测试
对于小数据集的测试,我们均测试磁盘分区数据,执行时间包括了磁盘IO的时间。为了保证测试的准确性和公正性,每次启动测试前均通过Linux系统命令sync;echo 1,2,3 | tee /proc/sys/vm/drop_caches清除系统的页面缓存,目录项缓存和硬盘缓存,启动程序后一次执行样例一遍,并记录执行的时间。
DolphinDB中使用以下脚本得到数据库句柄:
dp_readings = "dfs://db_range_dfs"
device_readings=loadTable(dp_readings, `readings_pt)
MongoDB中执行use device_pt语句切换数据库至device_pt数据库。在执行关联查询时,由于info数据集的数据量较小,因此可以把数据加载到内存中。在MongoDB中执行db.device_info.find({})将3,000条设备记录全部加载,在DolphinDB中执行loadText(dp_info)将3,000条设备记录加载至内存。在DolphinDB中使用timer计算查询执行耗时,在MongoDB中使用explain()函数获取执行时间。下面是DolphinDB在小数据集上的查询脚本,MongoDB的查询脚本见附录。
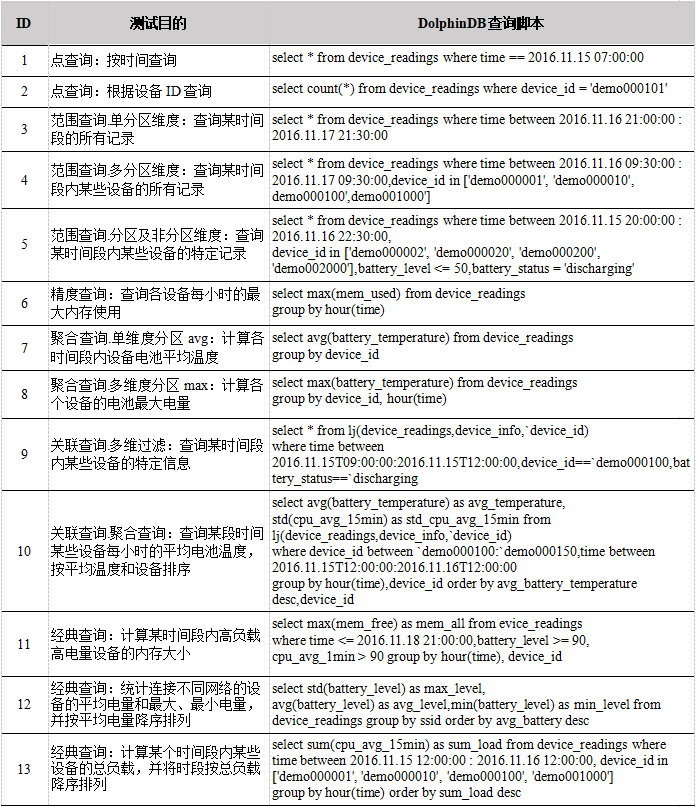
查询性能如下表所示:
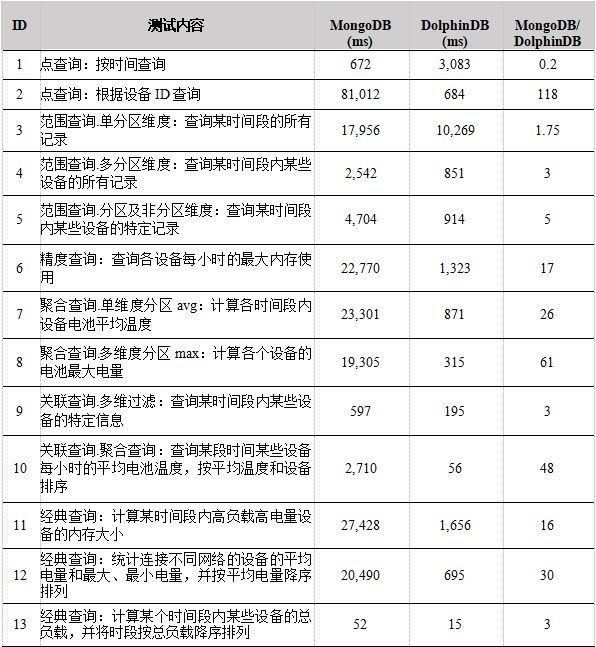
对于范围查询,在包括了分区字段的查询中,如查询3,4所示,MongoDB可以调用复合索引,DolphinDB可以通过分区字段加快查询,这种情况下两个数据库的差距在4倍之内,并不是很大。在包括了未分区字段的查询中,如查询5所示,MongoDB没法调用未分区字段的索引,需要进行全字段搜索过滤,DolphinDB则无需搜索不在where过滤条件中的字段,这种情况下DolphinDB和MongoDB的差距进一步扩大。可以看出在处理这种结构化时序数据时, DolphinDB采取的列式存储的方式的效率比MongoDB建立索引的方式更加高效,也更加适用于多维结构化数据的查询。
对于点查询,在查询1中,MongoDB在建立有time+device_id索引的情况下可以快速的找到某个时间点的记录,DolphinDB中按照日期分为4天,查找某一天的具体的时间点需要选定一个分区再进行检索,这种情况下DolphinDB比MongoDB慢。在查询2中,MongoDB的过滤字段仅为设备ID,没有包括time字段,我们从explain()中发现查询过程中没有调用复合索引,这是因为查询字段必须包括复合索引的首字段,索引才会起作用,查询1仅仅根据设备ID过滤,不涉及time字段的过滤, MongoDB不会调用复合索引,因此这种情况下,DolphinDB比MongoDB快。
对于关联查询,MongoDB作为NoSQL数据库,仅支持左外连接,并且因为其没有关系型数据库的主键约束,要实现表连接查询只能使用内嵌文档的方式,这种方式并不利于计算和聚合。DolphinDB作为关系型数据,其支持等值连接,左连接,全连接,asof连接,窗口连接和交叉连接,表连接查询功能丰富,可以高效方便地处理海量结构化时序数据。从查询9~10中我们可以看出DolphinDB快于MongoDB,并且关联查询越复杂,性能差距越大。
对于抽样查询,MongoDB可以在aggregation函数中通过$sample语句实现抽样查询,抽样方式取决于集合的大小,N(抽样数)的大小和$sample语句在pipeline中的位置。DolphinDB不支持全表抽样,仅支持分区字段抽样。因为两种数据抽样查询的实现过程差别较大,所以不做比较。
对于插值查询,MongoDB并没有内置的函数可以实现插值查询,而 DolphinDB 支持 4 种插值方式,ffill 向后取非空值填充、bfill 向前去非空值填充、lfill 线性插值、nullFill 指定值填充。
对于对比查询,MongoDB作为文档型数据库,其存储单元是文档,集合中包含若干文档,文档采用BSON格式,没有行和列的概念,因此无法实现选择两个维度将表中某字段的内容整理为一张表(第一个维度作为列,第二个维度作为行)的功能。DolphinDB中内置有pivot by函数语句,选定分类的维度可以方便的将制定内容整理为一张表。因为MongoDB不支持对比查询,所以不做比较。
62.4G股票交易大数据集查询测试
DolphinDB中使用以下脚本得到数据库句柄:
taq_pt_db= "dfs://db_compound_dfs"
taq_pt_col=loadTable(taq_pt_db, `readings_pt)
MongoDB中执行use taq_pt_db语句切换数据库至taq_pt_db数据库。
大数据集DolphinDB的查询脚本如下所示:

查询性能如下表所示:
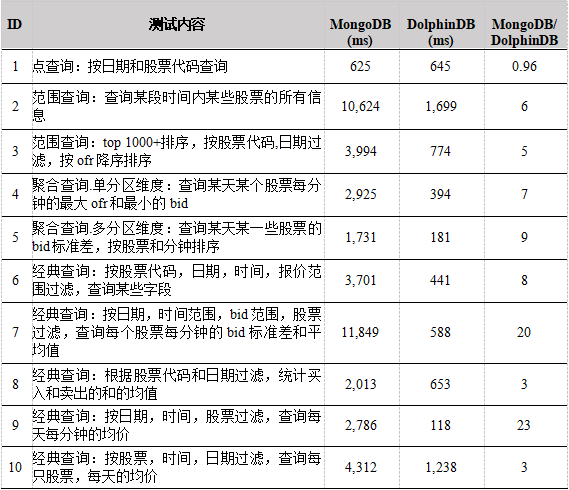
在大数据量,两个数据库均做了分区的情况下,DolphinDB依然比MongoDB大约快5-20倍。查询1是根据日期,股票代码进行的点查询,这种情况下MongoDB和DolphinDB的性能差距不大,DolphinDB略慢于MongoDB,这是MongoDB进行复合分区时会建立date+symbol复合索引可以较为快速的找到结果,是MongoDB比较好的应用场景,但是对比查询5~9可知,MongoDB的计算性能仍不如DolphinDB,差距大约在10-20倍之间。
在处理结构化的时序数据时,无论是数据导入导出、磁盘空间占用还是查询速度,DolphinDB的性能都比MongoDB更加优越。但是,MongoDB作为文档型的NoSQL数据库,在数据模型多变的场景下以及处理非结构化数据方面更有优势。
1. DolphinDB环境配置
2. MongoDB环境配置
3. DolphinDB分区脚本
4. MongoDB分区脚本
5. MongoDB查询脚本

