17
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享最近了解到有一款新的数据库产品 DolphinDB,官方宣称速度极快,比同类型产品快1~2个数量级。而业界熟知的kdb+也正是以快著称,所以我想要了解一下DolphinDB的性能是不是真的这么快,并且想要知道DolphinDB和kdb+哪一个的性能更好。
本次比较主要从3个方面展开:加载数据和保存数据、数据库查询和计算、表连接。
环境配置
首先,分别从官网下载试用版,由于kdb+的只有32位版本是免费的,所以就用32位版本的,DolphinDB Database 下载Linux 64位版本。这次测试的设备是戴尔PowerEdge 630,256GB内存,3.6TB固态硬盘,Redhat 7操作系统。
32位版本的kdb+允许的最大内存是4GB,为了公平起见,参照官网教程把DolphinDB的最大内存也改成4GB。

DolphinDB环境配置
Kdb+环境配置
详细测试
为了降低缓存带来的性能波动,每个测试的脚本都是执行10次,所以测试结果里面的时间执行10次所耗费的总时间,单位是毫秒。
我用的数据是从NYSE网站下载的股票数据,生成了两个表,分别是Trades和Quotes。下面是两个表的结构。
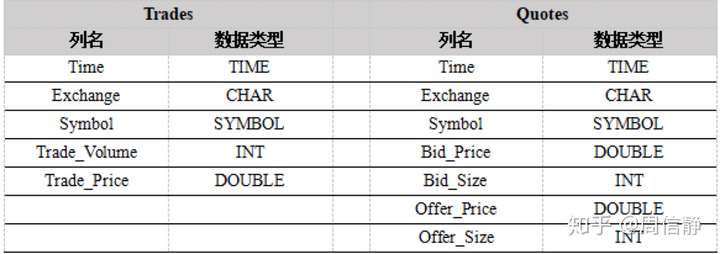
测试数据表结构
具体生成数据和测试的脚本帖在附录中。
2. 加载数据和保存数据
加载数据和保存数据算是数据库输入输出,测试出来的结果是DolphinDB比kdb+要略胜一筹。

加载和保存速度
3. 数据查询和计算
这里的数据查询和计算是在没有进行表连接的情况下测试的。我测试了16种常用的SQL查询,包括了分区数据和未分区数据。在进行的所有测试中,DolphinDB的速度的确都比kdb+要快。总结了一下,在数据没有分区的情况下,DolphinDB的速度是kdb+的2.5倍;在数据分区的情况下,DolphinDB的速度是kdb+的2倍
下面是数据库查询的结果。DDB是DolphindB的缩写。
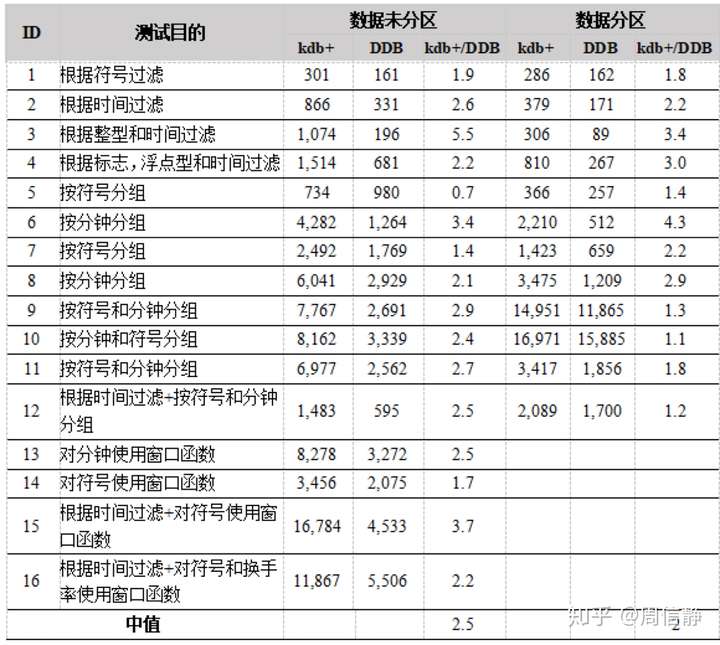
SQL查询比较
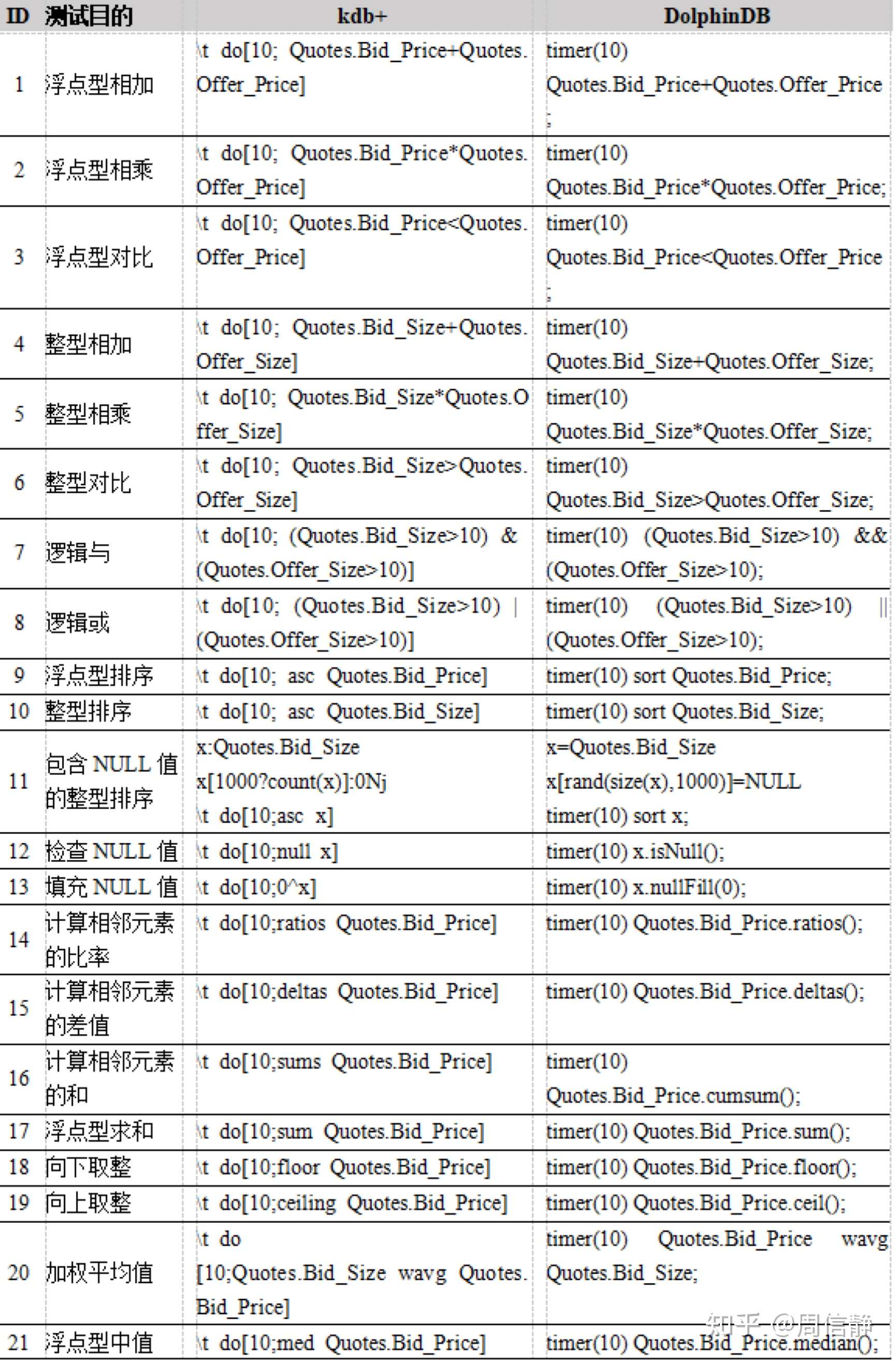
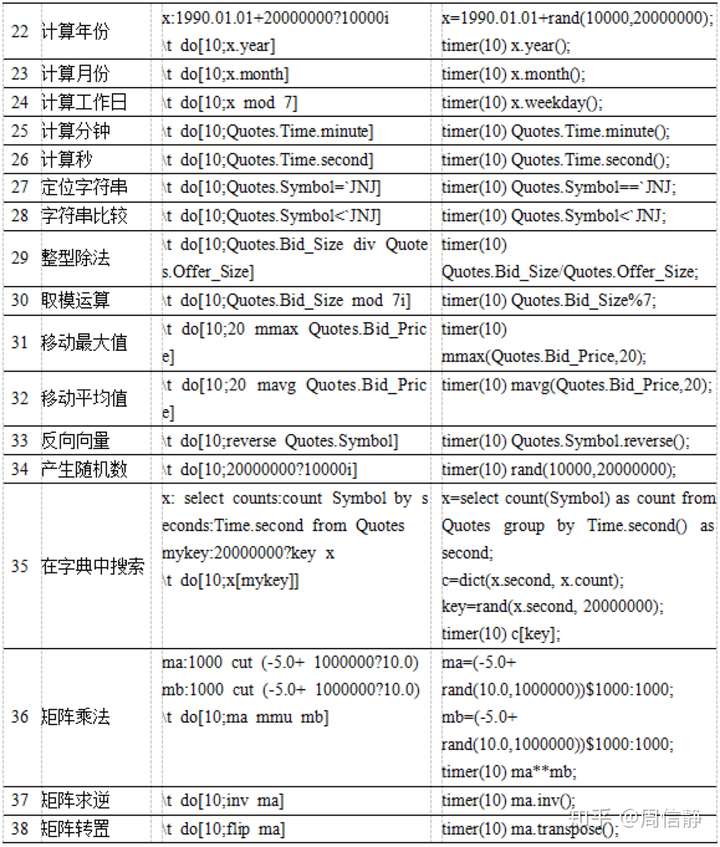
我也测试了38种比较典型的计算任务。在其中的35种测试中,DolphinDB比kdb+表现得更出色。DolphinDB计算中位数的速度是kdb+的2.7倍。在包含NULL值的整数排序,移动最大值和移动平均值这些测试项目上,DolphinDB的的速度是kdb+的10倍以上。
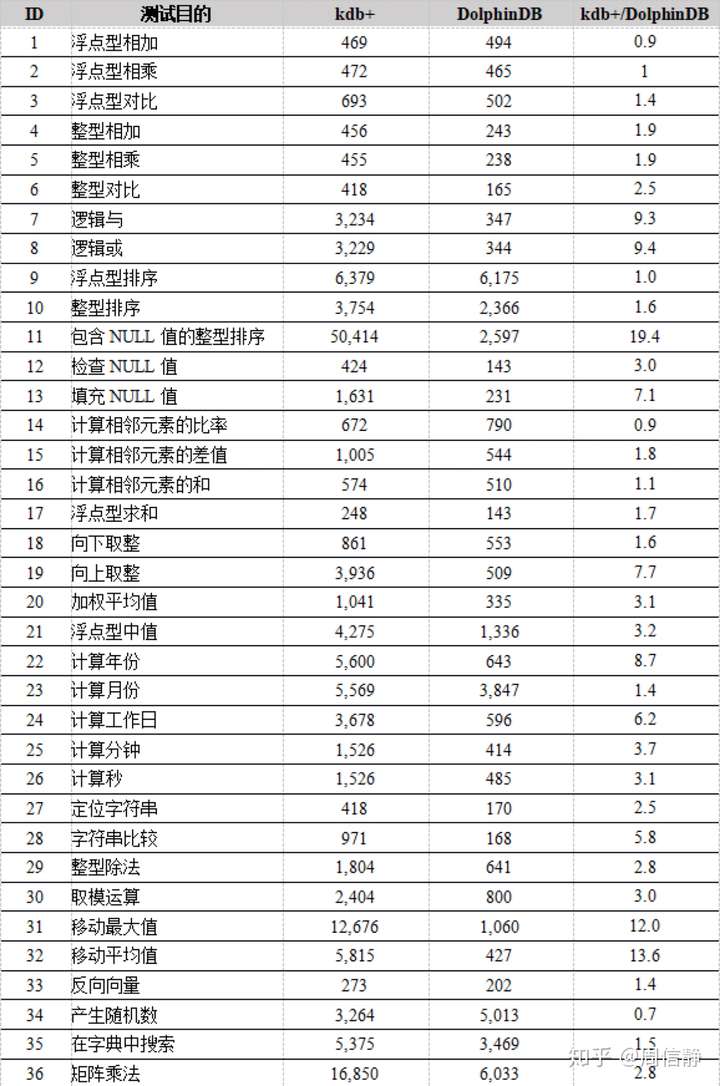
计算性能比较 (1)

计算性能比较 (2)
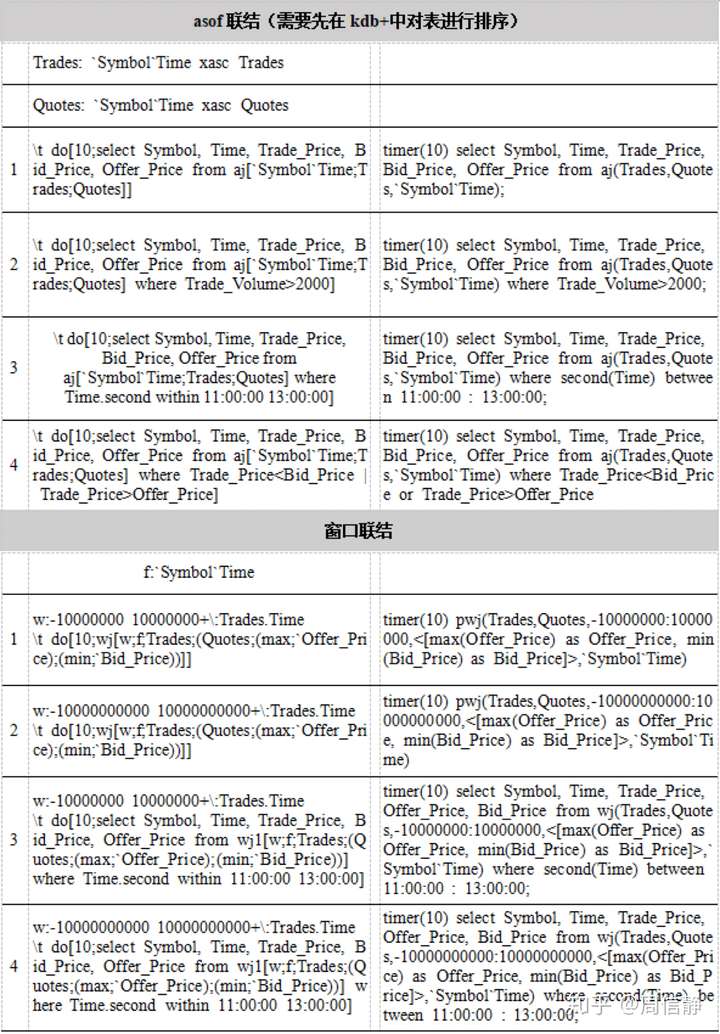
4. 表连接
左连接的时候,DolphindB稍微慢于kdb+,但在进行等值连接、asof join和窗口连接的情况下,DolphinDB比kdb+的速度明显要快得多。
对于左连接,kdb+的速度大约比DolphinDB快10%~30%。
对于等值连接,DolphinDB的速度大约是kdb+的2~4倍。
对于asof join,DolphinDB的速度大约是kdb+的4~8倍。
对于在窗口连接中使用常用的聚合函数(min、max、first、last、avg、wavg),DolphinDB比kdb+快1个数量级。
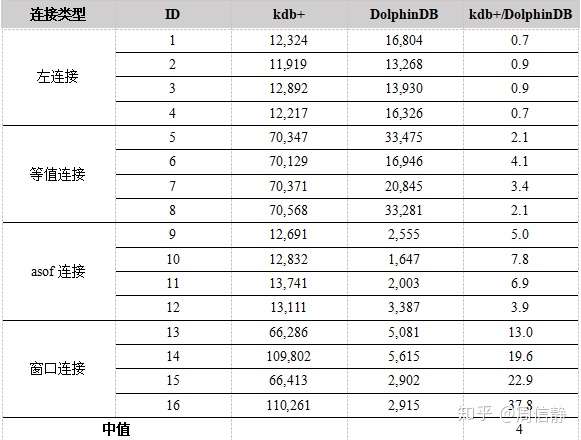
表连接比较
在这次测试中,DolphinDB表现着实耀眼,大部分场景下都比kdb+要快,小部分场景与kdb+相差不大。除了性能非常好之外,DolphinDB语言也相对易学得多,类似于Python+SQL,很容易就可以上手,相对而言,kdb+的q语言极其晦涩难懂,从附录的脚本就可以看出来。还有一点是,DolphinDB对时间序列数据的处理更加友好,它提供了很多与时间序列有关的函数,如移动平均数、最大值,并且比kdb+优化得更好。还需要指出的,DolphinDB采用了分布式文件系统和分布式计算,即使数据量非常庞大,DolphinDB也能达到毫秒级的响应速度,这是kdb+目前做不到的。
以上,仅供个人学习和参考,不得用于商业用途。如需转载,请联系作者,谢谢!
附录1.生成样本数据
访问ftp://ftp.nyxdata.com/Historical%2Data%20Samples/Daily%20TAQ%20Sample/并且下载EQY_US_ALL_TRADE_20161024.gz和EQY_US_ALL_NBBO_20161024.gz两个文件,然后把它们解压,保存在/DolphinDB/Data目录下,把两个文件的最后一行删除,因为最后一行是用来标记文件结尾的。
sed -i '$ d' EQY_US_ALL_TRADE_20161024
sed -i '$ d' EQY_US_ALL_NBBO_20161024
接着,执行下面的脚本。
DATA_DIR = "./DolphinDB/Data"
PTNDB_DIR = DATA_DIR+"/NYSETAQSeq"
db = database(PTNDB_DIR, SEQ, 16)
Trades = loadTextEx(db, `Trades, DATA_DIR + "/EQY_US_ALL_TRADE_20161024”,'|')
Quotes = loadTextEx(db, `Quotes, DATA_DIR + "/EQY_US_ALL_NBBO_20161024",'|')
表Trades包含2016年10月24日美国股市的所有交易数据。表Quotes包含同一天的全国最佳买卖报价(NBBO)。
接着,为了符合kdb+的内存限制,我们缩小了DolphinDB的数据集。
// select a quarter of symbols
symbols = exec distinct Symbol from Trades
symbols = symbols[0..(symbols.size() - 1) % 4 == 3]
Trades = select convertTime(Time) as Time, Exchange, Symbol, Trade_Volume, Trade_Price from Trades where Symbol in symbols
Quotes = select convertTime(Time) as Time, Exchange, Symbol, Bid_Price, Bid_Size, Offer_Price, Offer_Size from Quotes where Symbol in symbols
saveText(Trades, DATA_DIR + "/Trades.csv")
saveText(Quotes, DATA_DIR + "/Quotes.csv")
其中表Trades和表Quotes是未分区表。
在DolphinDB中执行以下脚本来生成分区表:
pdb = database(DATA_DIR+"/dolphindb_value_on_date", VALUE, [2016.10.24, 2016.10.25, 2016.10.26, 2016.10.27]);
Quotes = loadText(DATA_DIR + "/Quotes.csv");
dates = table(take([2016.10.24, 2016.10.25, 2016.10.26, 2016.10.27], size(Quotes)) as date);
Quotes = Quotes join dates;
saveText(Quotes, DATA_DIR + "/QuotesDates.csv");
pdb.createPartitionedTable(Quotes,`Quotes,`date).append!(Quotes);
Trades = loadText(DATA_DIR + "/Trades.csv");
dates = table(take([2016.10.24, 2016.10.25, 2016.10.26, 2016.10.27], size(Trades)) as date);
生成kdb+中的未分区表:
Trades: ("nssif";enlist ",") 0: `:/DolphinDB/Data/Trades.csv
Quotes: ("nssfifi";enlist ",") 0: `:/DolphinDB/Data/Quotes.csv
生成kdb+中的分区表:
dates = table(take([2016.10.24, 2016.10.25, 2016.10.26, 2016.10.27], size(Quotes)) as date);
Quotes =Quotes join dates;
saveText(Quotes, DATA_DIR+"/QuotesDates.csv");
QuotesDates: ("nssfifid";enlist ",") 0: `:/DolphinDB/Data/QuotesDates.csv
`:/KDB/TAQ/2016.10.24/Quotes/ set .Q.en[`:/KDB/TAQ] select from QuotesDates where date=2016.10.24
`:/KDB/TAQ/2016.10.25/Quotes/ set .Q.en[`:/KDB/TAQ] select from QuotesDates where date=2016.10.25
`:/KDB/TAQ/2016.10.26/Quotes/ set .Q.en[`:/KDB/TAQ] select from QuotesDates where date=2016.10.26
`:/KDB/TAQ/2016.10.27/Quotes/ set .Q.en[`:/KDB/TAQ] select from QuotesDates where date=2016.10.27
\l /DolphinDB/data/KDB/TAQ
附录2.加载数据和保存数据的脚本
把CSV文件加载到DolphinDB中:
timer(10) t1=loadText("/DolphinDB/data/Trades.csv")
把CSV文件加载到kdb+中:
\t do[10; Trades: ("tssif";enlist ",") 0: `:/DolphinDB/data/Trades.csv]
在DolphinDB中保存表:
timer(10) saveTable("/DolphinDB/data/Trades",t1, "Trades",true,true);
在kdb+中保存表:
\t do[10;`:/DolphinDB/data/Trades/splay/ set .Q.en[`:/DolphinDB/data/Trades; Trades]]
附录3.用于数据库查询的脚本
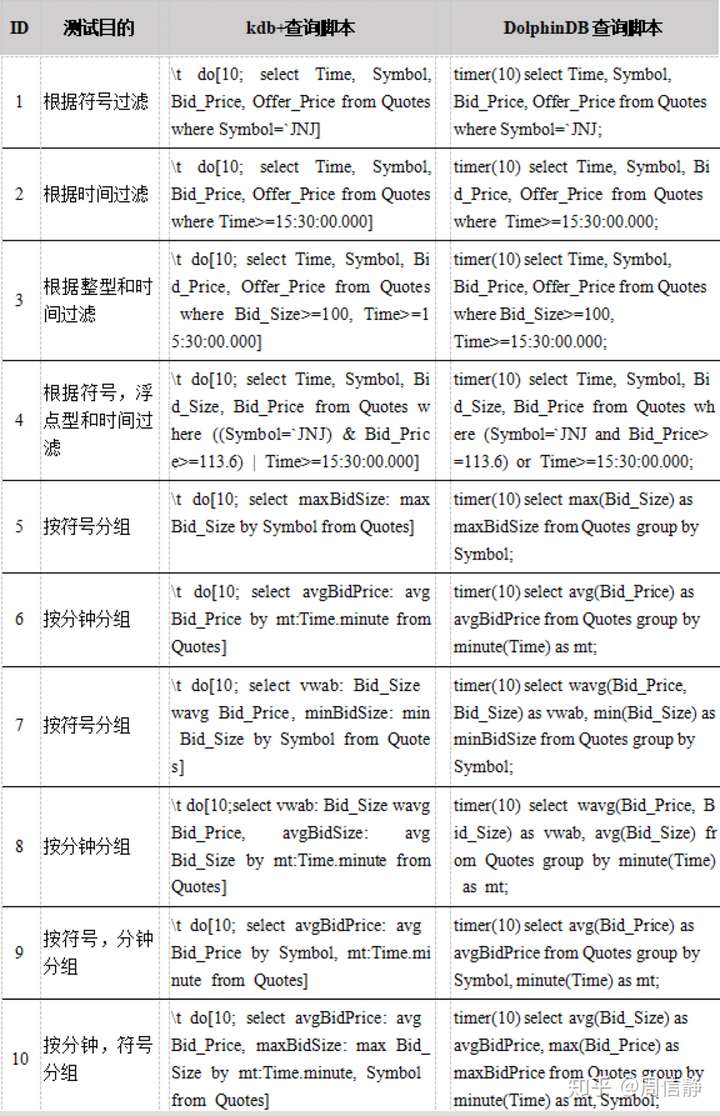
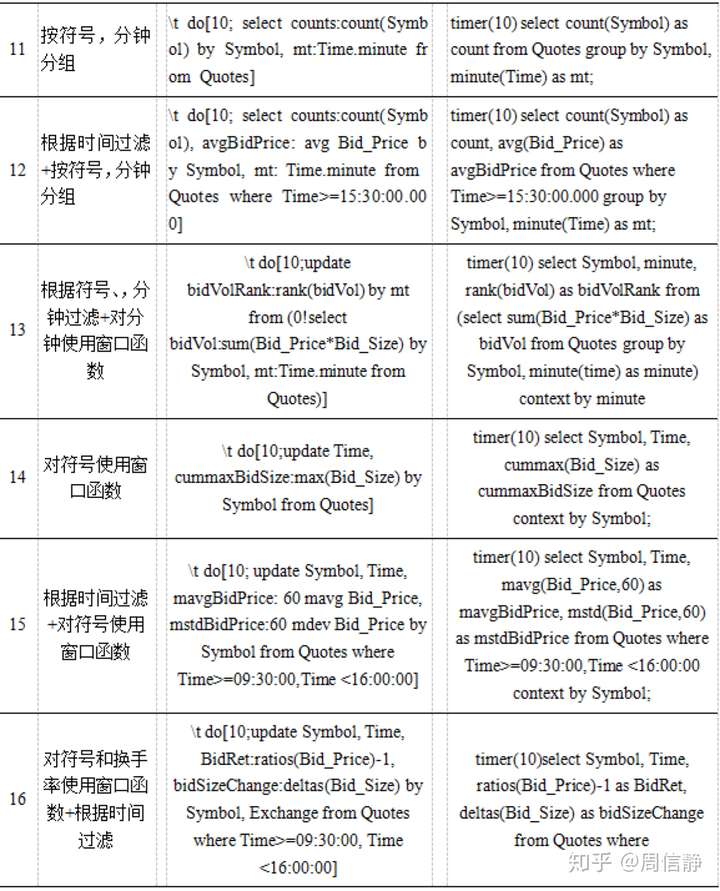
附录4.计算任务脚本
附录5.表连接脚本