




17
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享DolphinDB Database 是由浙江智臾科技有限公司自主研发,于2018年初发布的高性能的磁盘与内存混合型和列式分布式数据库产品。DolphinDB集成了功能强大的编程语言和高容量高速度的流数据分析系统,为海量数据(特别是时间序列数据)的快速存储、检索、计算及分析提供一站式解决方案。
DolphinDB的主要竞争优势体现在四个“快”:运行快、学习快、部署快和开发快。为什么仅20多M的软件能够超越市场上的同类产品呢?本文将从DolphinDB的设计思路和技术架构两方面来揭开谜底。
一、设计思路
DolphinDB采用全新的设计思路,把编程语言、数据库和分布式计算完美地融合在一起。我们可以通过下面这张图来更好地理解DolphinDB的设计思路。
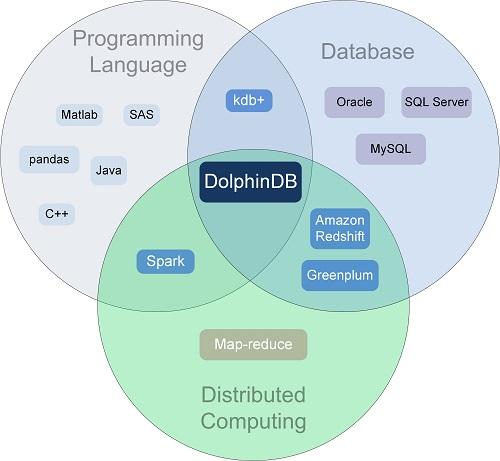
在传统数据库时代,数据的存储和分析计算,通常是分离的。Oracle和SQL Server等数据库服务器负责数据的存储和检索,Matlab和SAS等工作站软件负责数据的分析和计算。但是随着海量数据的到来,这种分离变得越来越困难,哪怕是从分布式数据库取千分之一,万分之一的数据都可能让一个工作站的内存无法支撑。所以,我们的一个基本看法是,在海量数据时代,分布式数据库和分布式计算将走向融合,数据和计算是紧密结合在一起的。通过这种融合,我们可以减少频繁的数据移动以及解决数据和计算资源不匹配的问题。
通过将编程语言和分布式计算融合,用户无需花费大量时间和精力来编写代码实现分布式计算。DolphinDB的脚本语言既可以轻松地调用分布式文件系统(DFS)和远程过程调用(RPC)的基础功能,也可以快速地创建分布式SQL需要的自定义函数,实现更为灵活的Pipeline、Map-Reduce和迭代计算等分布式应用。用DolphinDB脚本编写的分布式程序(应用),无需编译、打包和部署,可以在线使用。这大大提高了数据科学家的工作效率。
在传统的数据库时代,我们更看重数据的写入,所以我们强调数据库的一致性、原子性、持久性等等,而用于分析的SQL语句功能则相对简单,复杂的分析和计算通常由更高级的编程语言(譬如C++, Java等)来完成。在海量数据时代,我们更看重数据的读取,也就是通过对海量数据的分析,发掘数据背后的价值,数据分析的时效性则对企业的竞争能力至关重要。现在很多大数据系统主要实现了SQL接口,表达能力有限,很难满足更加复杂的数据分析和算法实现,影响开发效率。所以我们认为SQL语句和更高级的编程语言也将走向融合。
二、技术架构
DolphinDB的高性能不仅仅得益于全新的设计思路,还获益于独特的技术架构。
DolphinDB database 采用的是原创的架构(下文称为DolphinDB架构),并且引入了分布式文件系统(DFS),而市场上的一些数据仓库,如Teradata、IBM Netezza、Greenplum等都是采用主流的MPP(Massively Parallel Processing,大规模并行处理)架构的。
那么DolphinDB架构和MPP架构有什么区别呢?
通过下面两张图可以直观地看出DolphinDB架构(左)和MPP架构(右)的区别。
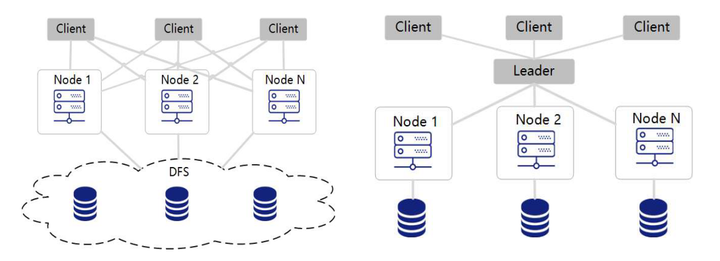
MPP架构是指一个系统拥有多个计算节点,每个节点都有独立的内存、操作系统和存储磁盘,它们之间是不存在共享的。因此,MPP架构也被称为shared nothing架构。
DolphinDB架构拥有多个数据节点,但在数据库层面不存在领导节点。每个数据节点虽然拥有本地的存储设备,数据节点与存储是通过DFS进行交互的。
为什么DolphinDB采用原创架构而不使用主流的MPP架构?
与MPP架构相比,DolphinDB架构具有以下的优势:
MPP采用树状结构,分区粒度较粗,容易出现数据分布不均衡,或在用户不饱和或查询数据只存在部分节点时出现资源闲置。DolphinDB的数据节点通过DFS共享存储,进行全局优化,数据均匀地分布在各节点上,能更充分的利用集群资源。
MPP架构通常会将一个任务发送到多个节点执行,即便在海量数据中查找很小的一部分数据,也是如此。DolphinDB的分布式文件系统和多列组合分区方案能够支持单表千万级的分区,能快速确定查询相关的分区和所在的节点,提高了查询的效率。
MPP是通过Hash计算来确定数据行所在的物理机器,存储位置的不透明导致了MPP的数据迁移和高可用较难实现。在DolphinDB中,存储逻辑与存储位置分离。当存储逻辑发生改变时,不需要改变数据的存储位置,只需要修改DFS master中的元数据,修改节点指向的存储位置即可。
当MPP集群规模和业务数据量达到一定数量时,数据库的元数据管理将会十分困难。一旦出错,很难恢复。MPP架构一般只能扩展到100个节点。 DolphinDB采用类似HDFS这样的分布式文件系统,由name node统一管理元数据、,自动管理分区数据和副本,提高了容错性和可扩展性。DolphinDB可以扩展到更多的节点。
MPP架构中客户端通过领导节点与集群连接。领导节点除了负责网络通讯之外,还负责将各个节点返回的数据合并,并作进一步处理,很容易成为整个系统的瓶颈。DolphinDB在数据库层面采用点对点的架构,每一个数据节点都可以作为协调者与客户端连接,因此DolphinDB很容易实现负载均衡。
三、总结
DolphinDB全新的设计思路和独特技术架构决定了它的高性能。DolphinDB不仅适用于大规模结构化数据快速入库和即席查询,还特别适用于时间序列数据以及实时流数据的处理和分析。
电话:0571- 8285 3925
邮箱:media@dolphindb.com


