




17
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享我们于近期发布了1.30.17和2.00.5版本,为存储引擎、数据分析引擎和流计算引擎新增或改进了多个重要功能。新版本进一步增强了存储与计算引擎的性能,并显著提高了数据库的易用性、适用性与安全性。
本文将从存储引擎、产品易用性、业务场景适用性、安全性四个方面为大家介绍本次新发版本的特性。
TSDB是我们在 2.00 版本推出的存储引擎。与 OLAP 引擎相比,它在读写数据时具有更高的效率与更丰富的特性。写数据时,既能满足海量数据的快速写入,又能保持存储的低成本,还具有自动去重等特性。读数据时,既能极速读取每个指标最新的状态,高并发高速读取多个指标一段时间内的数据,也能对读取的数据快速完成数据统计分析。新版本中,我们对TSDB 存储引擎从功能和易用性方面均进行了优化。
DolphinDB 的分区数据采用多副本存储模式,不同副本存储在不同节点中。当用户遇到副本损坏或版本不一致等问题时,TSDB 引擎支持在多副本存储模式下进行异步的数据恢复,恢复期间,用户仍可持续写入新的数据。在线增量恢复时,系统只需拷贝两个分区间有差异的数据,无需进行全量恢复,因此显著缩短了恢复数据的时间。
新版本的 TSDB 支持对写入缓存中的数据进行异步排序,这很好地解决了缓存数据排序带来的性能消耗问题。与同步排序相比,效率最多达到4倍的提升。
在2.00.5版本中,TSDB 引擎可以在 Windows 上运行。用户可以根据应用场景选择使用存储引擎,以便更高效地写入与查询。
数据库产品的易用性在企业的日常业务中是非常重要的考量维度之一。面对同样的问题,是需要用户自己写多行代码解决,还是可以直接通过一个内置函数完成,或者能否与熟悉的编程语言兼容等,这些都是用户使用产品的细节体验。用户使用数据库更多是需要基于产品搭建自己的应用,如果产品需要很高的学习成本、操作成本,并且安全性得不到保障,那对企业的运维管理效率、经营业绩都会产生负面影响。
在新版本中,我们引入或改进了多个功能,并在语法兼容和扩展上做了进一步提升,为客户提供了更多方便、安全的手段,显著提高了数据库的友好和易用性,以保障我们的客户能够更好地控制研发成本,提升使用体验。
rebalanceChunksAmongDataNodes([exec = false])
rebalanceChunksWithinDataNode(nodeAlias, [exec = false])
restoreDislocatedTablet()
以往版本 DolphinDB 的 SQL 语法与标准 SQL 语法的不同之处,除了 DolphinDB 独有的 context by,pivot by 等创新之外,主要是不支持 JOIN,CREATE,ALTER 等语句,而以 DolphinDB 内置函数实现。随着 DolphinDB 的应用领域不断拓展,越来越多的用户都希望 DolphinDB 兼容标准 SQL 语法。新版本中新增了 join, create, alter 语句,对于习惯使用标准 SQL 语法的用户来说更加友好,有效降低了学习和使用门槛。
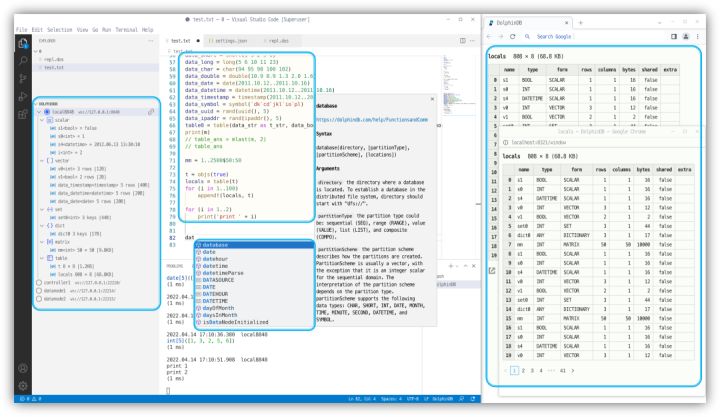
许多用户曾经评论过,DolphinDB GUI 虽然功能齐全,但是界面太老旧。我们在新版本中积极回应了广大用户对 VSCode 插件的期盼,将 DolphinDB GUI 功能迁移至 VSCode,极大提升了前端界面的用户体验。新版本 VSCode 插件可建立多个与 server 的连接并可任意切换,可以查看会话变量的值,也支持在弹窗中查看变量,方便比较多次查询的结果。此外,我们还为用户提供了1000多个函数的参数提示、智能补全和函数文档链接。在编写代码时,可以直接查看函数功能和用法,极大地降低了编写代码的时间成本。
某些问题可能需要多个表(多种消息类型)的协作,而且所有来源的消息是有时间先后顺序的。例如对于金融的行情数据,有交易,报价,订单薄等多个表,这些表的结构各不相同,但业务要求将多个不同结构的表按时间戳同步回放,仿真实盘情况。针对该场景,DolphinDB 在新版本改进了回放机制,支持多张异构表或数据源回放到一张流数据表,并严格按照时间顺序输出,从而解决了同构模型难以保证多消息回放时间一致性的问题。
用户在使用流数据时序引擎计算全市场股票的一分钟K线时,对交易非常不活跃的股票,或对午盘休息、下午停盘后长时间没有新数据到来的时间段,可以通过开启强制触发,减少计算延时,并自定义填充无数据的空窗口,确保每个窗口均有及时的数据输出。为了尽早输出各个分组的窗口计算结果,新版本改进了时序引擎的强制触发选项。新版本中,一个窗口后的第一条数据即可触发所有股票窗口的计算;用户亦可标记交易时段的结束时刻。
pivot by 语句是 DolphinDB 的创新,也是对标准 SQL 语句的拓展。它可将表中某列的内容按照两个维度重新排列。若进行 pivot by 的数据量较大,会对其性能有较高的要求。新版本中 pivot by 的性能在部分情况下有大约5倍的提升。
引擎流水线级联是解决复杂因子实时计算的问题的一个通用方法。我们在新版本中拓展了其他引擎和连接引擎级联计算的功能,极大简化了计算流程,减少内存等资源的消耗,对于复杂计算场景下的因子开发更加有效。
除了性能、功能外,流数据引擎的安全也是很多客户关心的方面。在之前的版本中,流数据引擎创建后,若管理员未对该引擎进行权限限制,任何用户均可以删除其他人所创建的流计算引擎,误删风险极大。针对该问题,新版本增加了用户层级的权限控制,当多用户在同一个集群上进行开发时,可为自建的流引擎增加访问限制,以避免多个用户之间的干扰。
未来我们将继续在高性能分布式时序数据库的基础上,不断为广大用户提供性能更优秀、管理更便捷、功能更强大的数据存储与分析一站式解决方案。在下一个小版本中,TSDB 存储引擎的优化为重点工作方向。首先通过对排序列(时间序列的tag列)的映射,优雅地解决了时序数据库的时间线膨胀的问题。 其次, 我们的用户可以以较低的代价实现对时序数据的修改。最后,分级存储功能的推出将进一步降低时序数据库用户的存储成本,尤其在云端,用户可以使用 AWS S3 等低成本的文件系统来存储冷数据。DolphinDB 已经发布了 Kubernetes 的部署包,下一个版本将在监控告警、日志采集、备份恢复、多 K8S 高可用等多个方向持续发力,为用户提供更灵活、更高性能、更安全可靠的数据库服务体验。

