


301
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享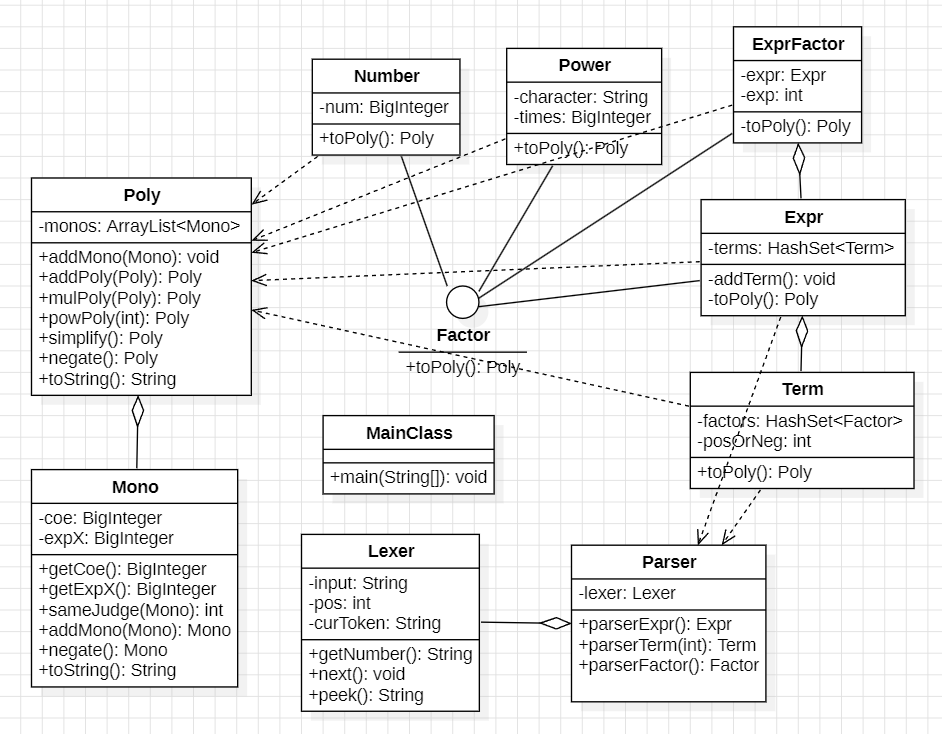
本次作业需要分析的表达式主要由Expr、Term、Factor三个部分组成,其中Expr由多个Term通过加减法构成,Term由多个Factor通过乘法构成,而Factor分为幂函数Power、常数因子Number和表达式因子ExprFactor三个种类。
本次作业主要关心两个问题:
此处使用到两个类:语法分析器Parser和词法分析器Lexer。词法分析的作用为读取token并提供给语法分析器,语法分析的作用为存储表达式结构。
词法分析器每次分析出一个token后,都将其结果存储在curToken中,以便于语法分析器通过调用peek()方法获取token的内容。
词法分析主要通过next()方法进行,每调用一次next()方法都向后分析一个token。代码架构如下:
public void next() {
if (pos == input.length()) {
return;
}
char c = input.charAt(pos);
if (Character.isDigit(c)) {
curToken = getNumber();
} else if ("()+-*^".indexOf(c) != -1) {
pos += 1;
curToken = String.valueOf(c);
} else {
pos += 1;
curToken = String.valueOf(c);
}
}
private String getNumber() {
StringBuilder sb = new StringBuilder();
while (pos < input.length() && Character.isDigit(input.charAt(pos))) {
sb.append(input.charAt(pos));
++pos;
}
return sb.toString();
}
具体思路为,对于题目中需要分析的表达式Expr,采用语法分析器Parser中的对应方法parseExpr()进行分析。而Expr由多个Term通过加减法构成,因此在对Expr进行语法分析时,调用分析Term的语法分析方法。parseTerm()分析结束后返回构建好的Term,将所有Term分析完后,Expr的构建也就完成了。代码架构如下:
public Expr parseExpr() {
Expr expr = new Expr();
int posOrNeg = 0; //表示项的正负
if (lexer.peek().equals("-")) {
posOrNeg = 1;
lexer.next();
} else if (lexer.peek().equals("+")) {
lexer.next();
}
expr.addTerm(parseTerm(posOrNeg));
while (lexer.peek().equals("+") || lexer.peek().equals("-")) {
posOrNeg = (lexer.peek().equals("+")) ? 0 : 1;
lexer.next();
expr.addTerm(parseTerm(posOrNeg));
}
return expr;
}
Term由多个Factor通过乘法构成,因此分析方式同理,此处不再赘述。
对于Factor的语法分析,首先根据词法分析器Lexer返回的结果判断因子的类型,之后调用对应因子的构造方法即可。代码架构如下:
public Factor parseFactor() {
if (lexer.peek().equals("(")) {
//调用parseExpr()分析表达式
return new ExprFactor((Expr)expr, exp);;
} else if (lexer.peek().equals("+") || lexer.peek().equals("-")) {
//......
return new Number(num);
} else if ("xyz".contains(lexer.peek())) {
//......
return new Power(character, times);
} else {
BigInteger num = new BigInteger(lexer.peek());
lexer.next();
return new Number(num);
}
}
表达式的本质是多项式,多项式又由许多个单项式构成。因此建立多项式类Poly和单项式类Mono,采用其中的方法进行化简,并储存结果。在Expr类中递归调用toPoly()方法即可把语法分析中读取的表达式存储到多项式中。
本次作业中,单项式的形式为常数*未知数^常数,由于未知数目前只有x一种,单项式中存储的成员只有常数coe和未知数指数expX。
单项式通过toString()方法将存储的值进行输出。除此之外,为了方便化简,还实现了sameJudge()方法,用于判断两个单项式是否可以合并。代码架构如下:
public class Mono {
private final BigInteger coe;
private final BigInteger expX;
public Mono(BigInteger coe, BigInteger expX) {
this.coe = coe;
this.expX = expX;
}
public BigInteger getCoe() {
return this.coe;
}
public BigInteger getExpX() {
return this.expX;
}
public int sameJudge(Mono mono2) {
//......
}
public Mono addMono(Mono mono2) {
//......
}
public Mono negate() {
//......
}
public String toString() {
//......
}
}
多项式由许多个单项式构成,Poly类中通过ArrayList存储多个Mono。此外,实现了addPoly()、mulPoly()、powPoly()等运算方法,simplify()合并同类项方法和toString()输出方法。代码架构如下:
public class Poly {
private final ArrayList<Mono> monos;
public Poly() {
this.monos = new ArrayList<Mono>();
}
public void addMono(Mono mono) {
this.monos.add(mono);
}
public Poly addPoly(Poly poly2) {
//逐项相加
poly = poly.Simplify();
return poly;
}
public Poly mulPoly(Poly poly2) {
//逐项相乘
poly = poly.Simplify();
return poly;
}
public Poly powPoly(int exp) {
if (exp == 0) {
//(x)**0=1
}
//乘方
poly = poly.Simplify();
return poly;
}
public Poly Simplify() {
for (Mono curThisMono : this.monos) {
for (int i = 0; i < poly.monos.size(); i++) {
Mono curMono = poly.monos.get(i);
if (curMono.sameJudge(curThisMono) == 1) {
flag = 1;
//......
}
}
if (flag == 0) {
poly.addMono(curThisMono);
}
}
return poly;
}
public Poly negate() {
//......
}
public String toString() {
//......
}
}
在每个类中都实现toPoly()方法,之后通过顶层的Expr调用,就可以自顶向下完成括号的展开。
Number和Power的toPoly()方法只需要向待返回的Poly中添加对应的单项式;ExprFactor的toPoly()方法需要调用Expr的toPoly()方法,并返回Poly进行乘方后的值;Term的toPoly()方法需要调用每个Factor的toPoly()方法,并返回这些Poly依次相乘后的值;Expr的toPoly()方法需要调用每个Term的toPoly()方法,并返回这些Poly依次相加后的值;以Term为例,代码架构如下:
public Poly toPoly() {
//......
while (iterator.hasNext()) {
//......
poly = poly.mulPoly(curPoly);
}
return poly;
}
通过input = input.replaceAll("\\s", "");去除读入表达式中的空白符。关于对连续的+-号的处理,在递归下降的过程中分布实现。
一个本人未能注意到的优化:如果单项式既有正又有负,则正项优先输出。
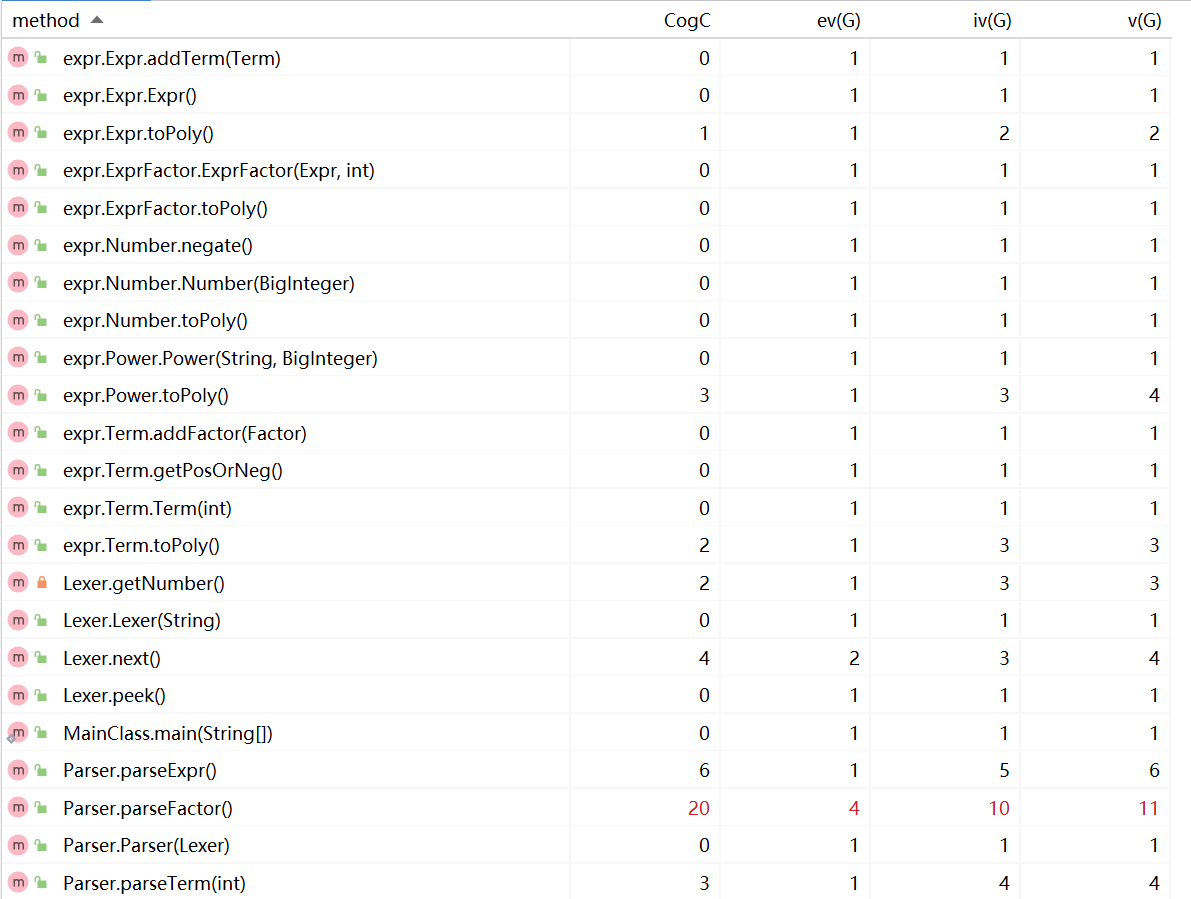
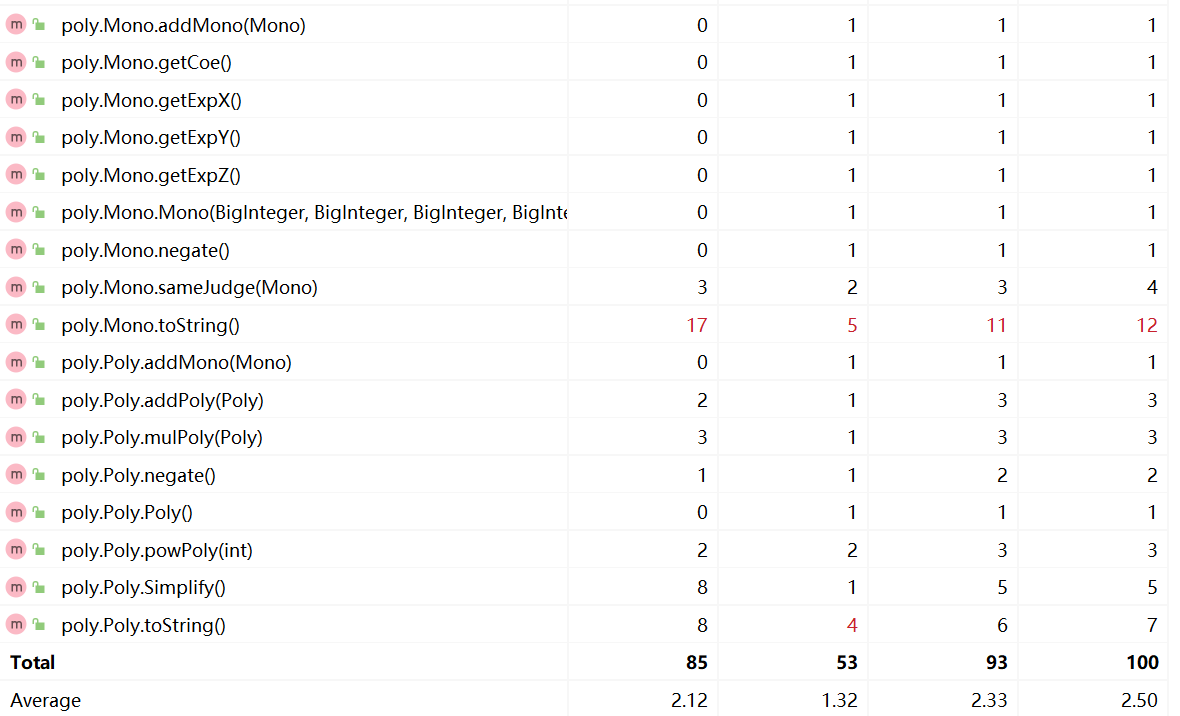
Parser中的parseFactor()和Mono中的toString()方法在实现的过程中都需要分情况讨论,使用了大量的if-else语句,因此代码复杂度较高。第二次作业中对parseFactor()方法进行了优化,简化了条件判断后语句块中的内容。
相比于第一次作业,本次作业增加了指数函数和自定义函数。
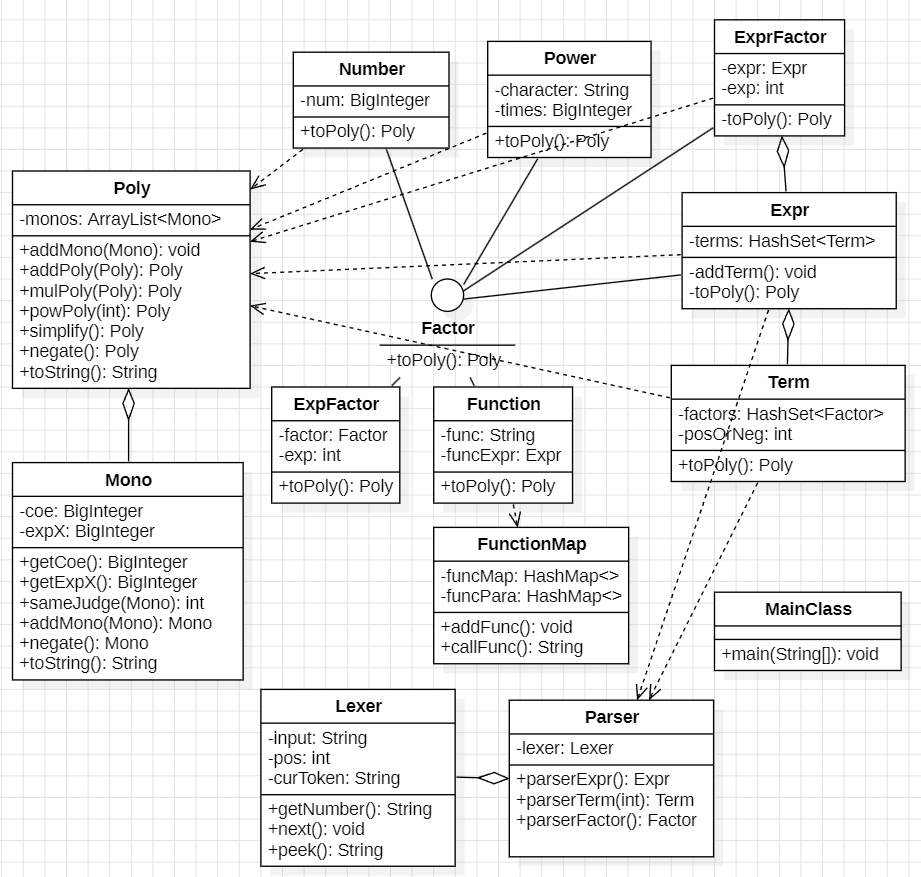
本次作业主要关心两个问题:
在词法分析的过程中增加对于exp的判断,并在语法分析的parseFactor中增加对于ExpFactor的分析。分别对exp()中的内容和可能存在的指数进行语法分析,之后调用ExpFactor的构造方法即可。代码架构如下:
public Factor parseExpFactor() {
//...
Factor expFactor = parseFactor();
//...
if (lexer.peek().equals("^")) {
//......
}
return new ExpFactor(expFactor, exp);
}
增加指数函数后,Mono中也添加了相应的expSameJudge()方法,用于判断指数函数因子是否相同。代码架构如下:
public int expSameJudge(HashMap<Poly, Integer> exp2) {
if (exp.isEmpty() && exp2.isEmpty()) {
return 1;
}
if (exp.size() != exp2.size()) {
return 0;
} else {
for (Poly key : exp.keySet()) {
int equalFlag = 0;
for (Poly key2 : exp2.keySet()) {
if (key.judgeSame(key2) == 1) {
equalFlag = 1;
if (!exp.get(key).equals(exp2.get(key2))) {
return 0;
}
}
}
if (equalFlag == 0) {
return 0;
}
}
return 1;
}
}
此处使用到两个类:函数声明类FunctionMap和函数因子Function。函数声明类的作用为在自定义函数读取的过程中存储自定义函数的形参表和函数体,并实现函数调用方法。函数因子用于储存函数表达式。
FunctionMap类中存储了两个HashMap成员变量,其中funcMap为函数体表,key为String类型的函数名,value为对应的String类型的函数体;**funcPara为函数形参表**,key为String类型的函数名,value为一个ArrayList,存储String类型的形参。
该类实现了两个方法addFunc()和callFunc()。addFunc()存储自定义函数,callFunc()在遍历函数体遇到形参时,将实参与形参进行对应,并进行字符串替换。
此处有两个需要注意的问题:
exp,形参表中含有x,则直接进行字符串替换会造成混淆。本人的做法是在实参替换前将所有的exp替换为e,实参替换结束后再将e替换回exp。代码架构如下:
public class FunctionMap {
private static HashMap<String, String> funcMap = new HashMap<>();
private static HashMap<String, ArrayList<String>> funcPara = new HashMap<>();
public static void addFunc(String func) {
String name = String.valueOf(func.charAt(0));
int pos = 2;
ArrayList<String> para = new ArrayList<>();
while (func.charAt(pos) != ')') {
if (Character.isAlphabetic(func.charAt(pos))) {
//......
} else {
pos += 1;
}
}
funcPara.put(name, para);
pos += 2;
funcMap.put(name, func.substring(pos));
}
public static String callFunc(String name, ArrayList<Factor> actualPara) {
String content = funcMap.get(name);
ArrayList<String> formPara = funcPara.get(name);
int pos = 0;
StringBuilder sb = new StringBuilder();
content = content.replaceAll("exp", "E");
while (pos < content.length()) {
if ("xyz".indexOf(content.charAt(pos)) != -1) {
//实参替换
} else {
//......
}
}
String callContent = sb.toString();
callContent = callContent.replaceAll("E", "exp");
return callContent;
}
}
语法分析遇到函数名token时,对函数的每个实参进行语法分析,并根据实参和函数名构造函数因子。在函数因子的构造方法中调用FuncMap的callFun()方法,按照解析表达式的步骤对替换后的函数表达式进行分析。
该类的toPoly()方法即为调用分析后的函数表达式的toPoly()函数。
代码架构如下:
public class Function implements Factor {
private final String func;
private final Expr funcExpr;
public Function(String name, ArrayList<Factor> actualPara) {
func = FunctionMap.callFunc(name, actualPara);
Lexer lexer = new Lexer(func);
Parser parser = new Parser(lexer);
funcExpr = parser.parseExpr();
}
public Expr getFuncExpr() {
return funcExpr;
}
public Poly toPoly() {
return funcExpr.toPoly();
}
}
本次作业没有新增预处理。为了确保正确性和防止TLE,对exp()表达式进行的优化只有两点:
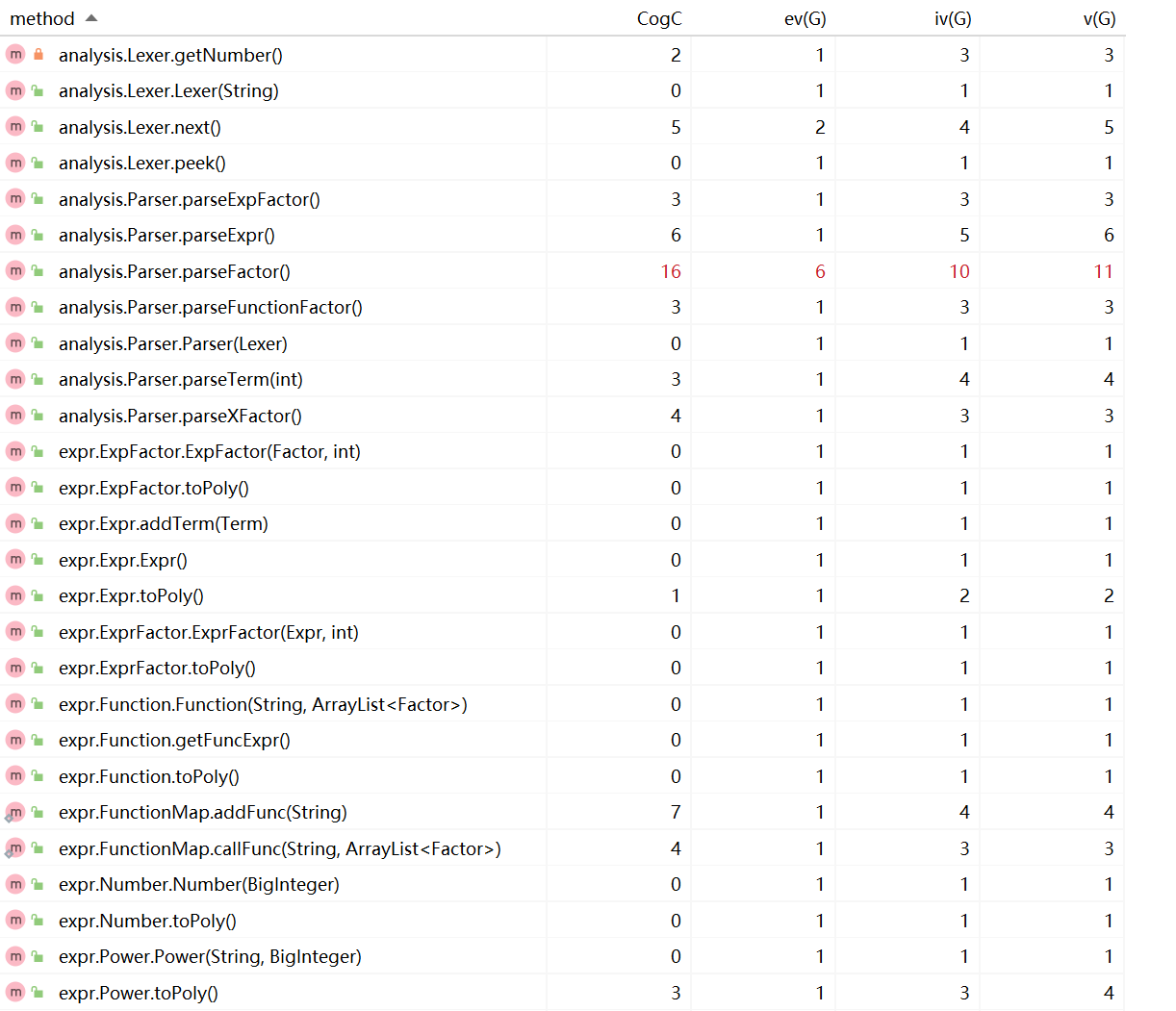
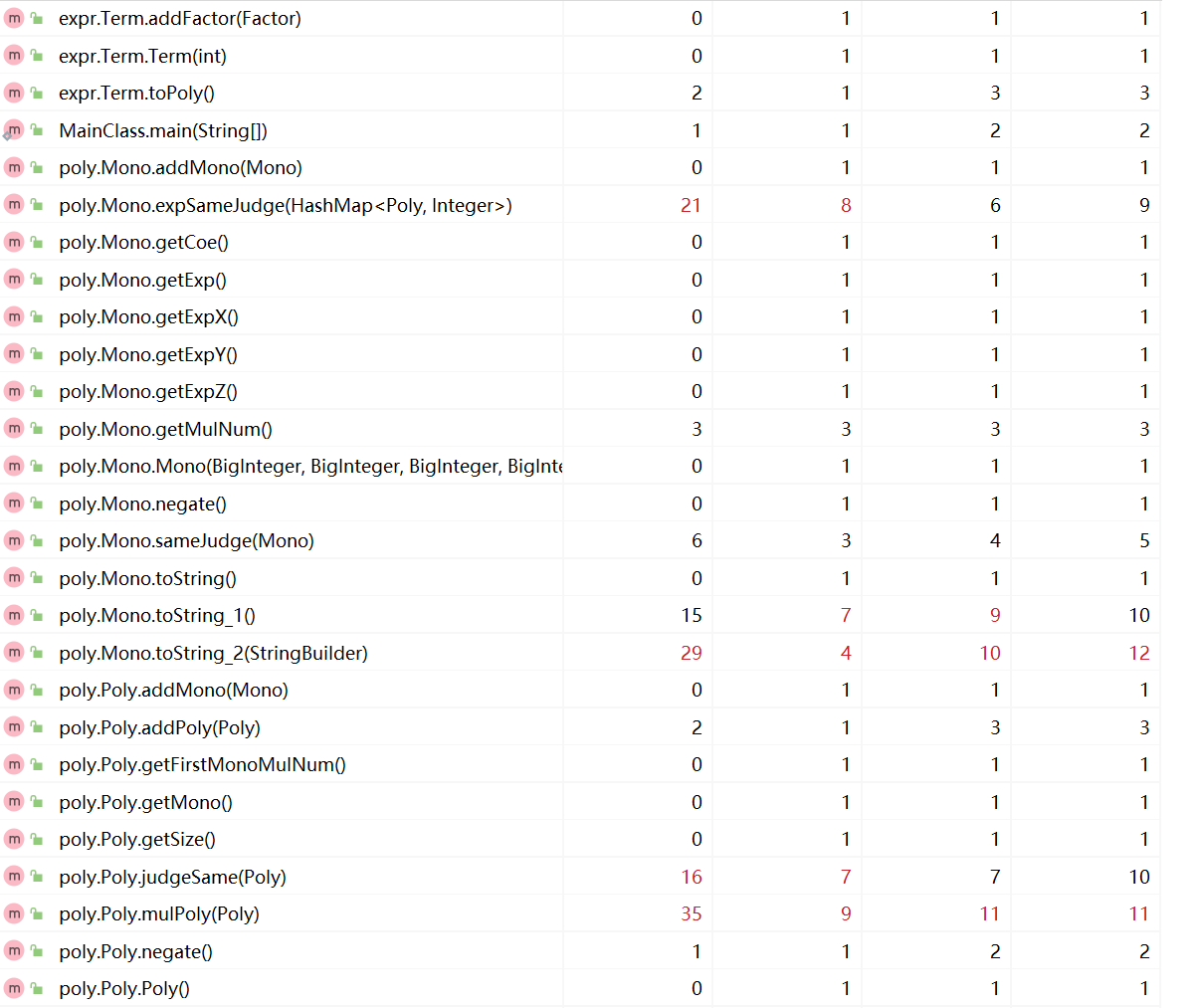

新增的expSameJudge()方法由于需要比较两组指数函数因子是否完全相等,因此代码复杂度较高。Poly中的judgeSame()和mulPoly()都调用了此方法,复杂度有所上升。此外,Mono中的toString()方法由于复杂度较高被分解为两个部分,但由于使用了大量的if-else语句,代码复杂度依旧没有显著下降。
相比于第二次作业,本次作业增加了求导因子。
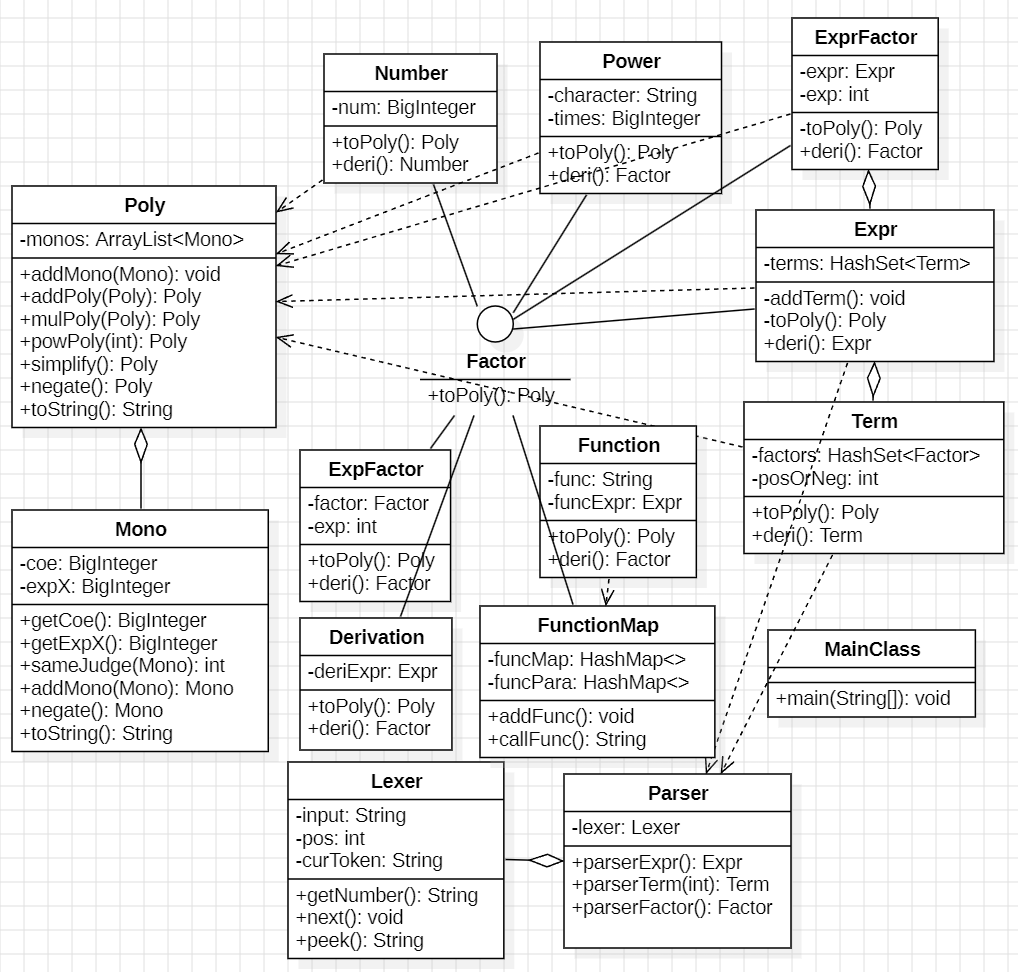
本次作业主要关心的问题是:多项式求导如何实现?
新增Derivation类,用于存储多项式求导的结果。代码架构如下:
public class Derivation implements Factor {
private final Expr deriExpr;
public Derivation(Expr expr, char c) {
deriExpr = expr.deri(c);
}
public Poly toPoly() {
return deriExpr.toPoly();
}
public Factor deri(char c) {
return deriExpr.deri(c);
}
}
对于多项式的每个组成部分新增求导方法deri(),在计算求导结果时,通过顶层的Expr调用求导方法,就可以自顶向下完成求导的计算。
Number的deri()方法返回因子0;Power的deri()方法返回系数*x^系数-1;ExprFactor的deri()方法需要调用Expr的deri()方法,并返回链式法则运算的结果;Term的deri()方法需要调用每个Factor的deri()方法,并返回乘法法则运算的结果;Expr的deri()方法需要调用每个Term的deri()方法,并返回这些结果依次相加后的值;以Term为例,代码架构如下:
public Term deri(char c) {
Iterator<Factor> iterator = factors.iterator();
Expr deriTerm = new Expr();
while (iterator.hasNext()) {
//...
Term partDeriTerm = this.remove(curFactor);
partDeriTerm.addFactor(curFactor.deri(c));
deriTerm.addTerm(partDeriTerm);
}
//......
return deriTerm;
}
本次作业没有新增预处理和优化。
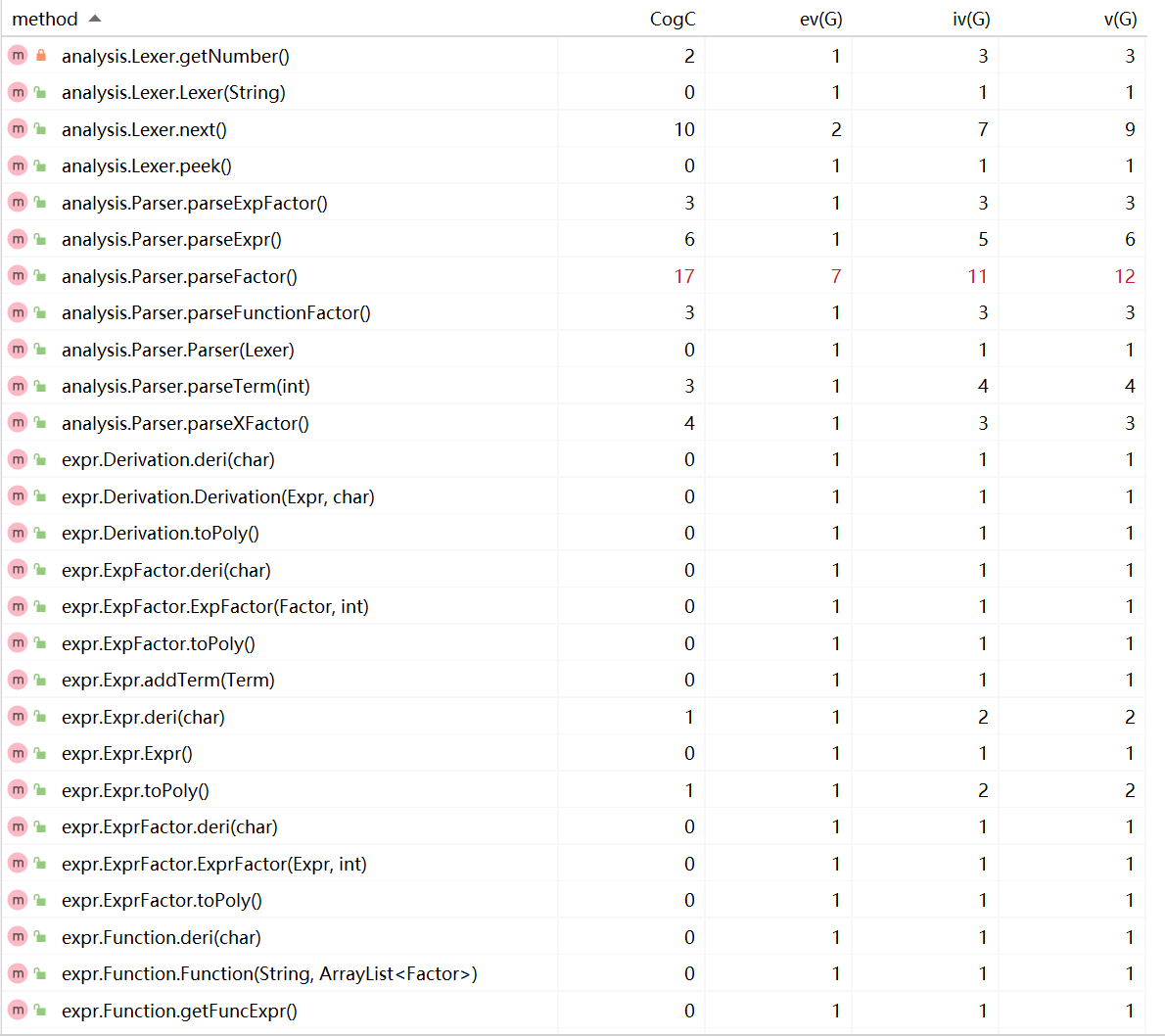
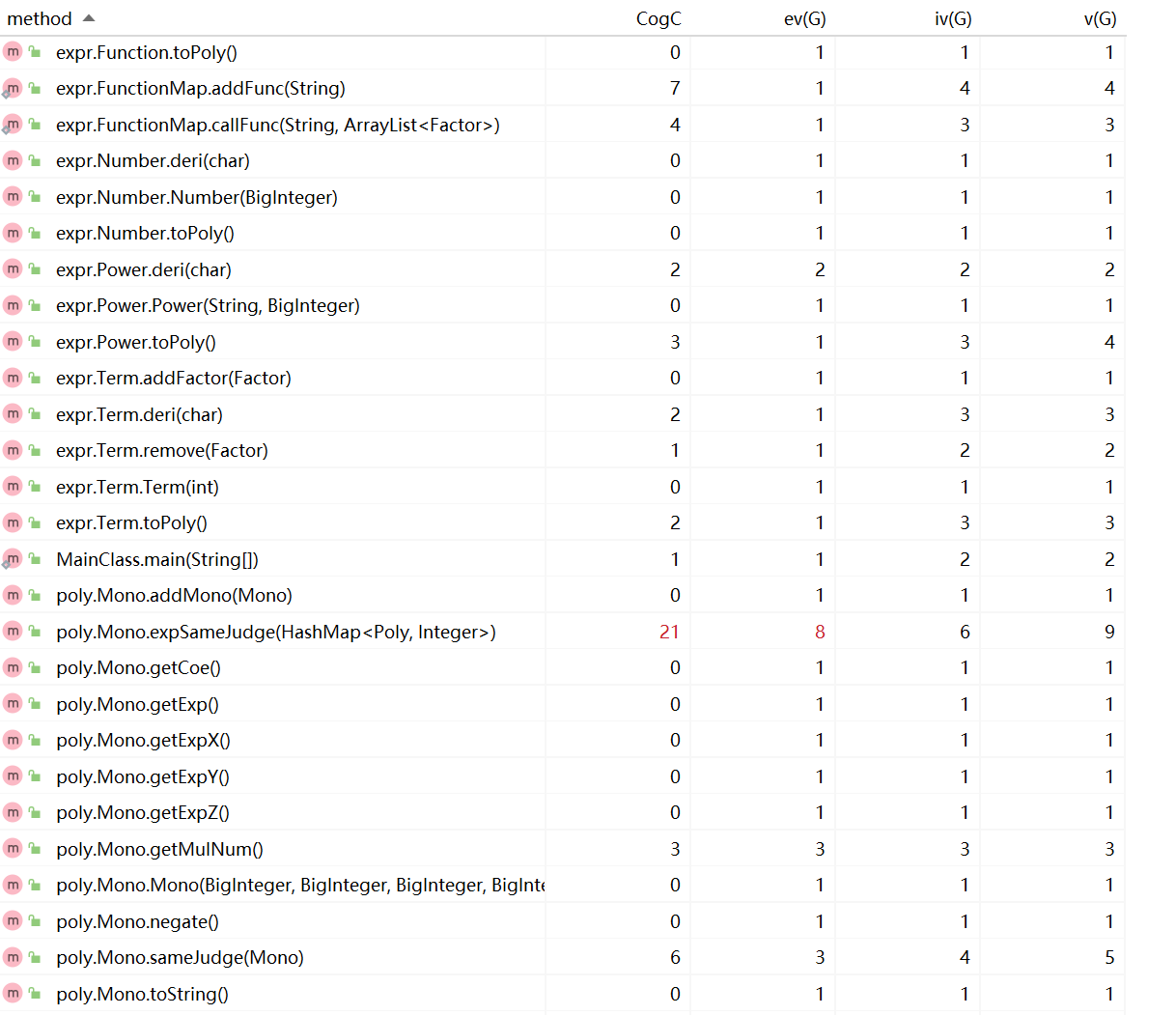
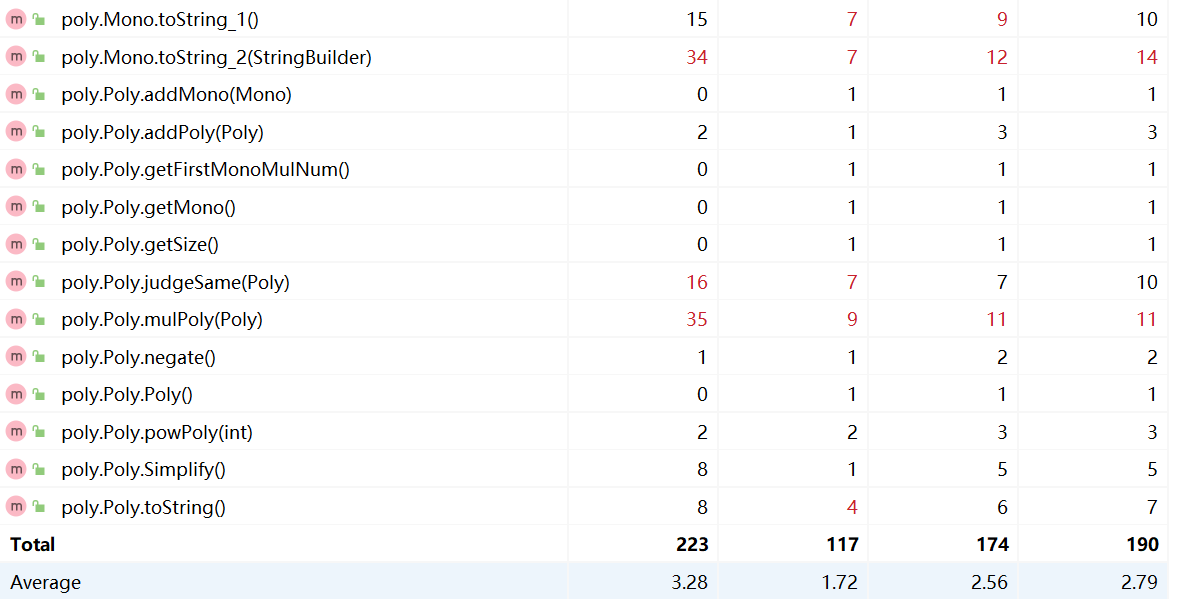
可以看出代码复杂度较高的方法与上次作业的情况保持一致。
与指数函数因子的形式接近,代码架构如下:
public class CosFactor implements Factor{
private final Factor factor;
private final int exp;
public CosFactor(Factor factor, int exp) {
this.factor = factor;
this.exp = exp;
}
public Poly toPoly() {
Poly cosPoly = (factor.toPoly()).Simplify();
HashMap<Poly, Integer> cos = new HashMap<>();
//...
return poly;
}
}
public int cosSameJudge(HashMap<Poly, Integer> cos2) {
if (cos.isEmpty() && cos2.isEmpty()) {
return 1;
}
if (cos.size() != cos2.size()) {
return 0;
} else {
for (Poly key : cos.keySet()) {
int equalFlag = 0;
for (Poly key2 : cos2.keySet()) {
if (key.judgeSame(key2) == 1) {
equalFlag = 1;
if (!cos.get(key).equals(cos2.get(key2))) {
return 0;
}
}
}
if (equalFlag == 0) {
return 0;
}
}
return 1;
}
}
在Power类中增加expY和expZ成员变量即可。对于求导因子中可能出现的求偏导情况,只要在deri()方法中将求导的未知数作为参数传入即可,以Expr和Power为例:
//Expr:
public Expr deri(char c) { //c = x y z
Iterator<Term> iterator = terms.iterator();
Expr deriExpr = new Expr();
while (iterator.hasNext()) {
Term curTerm = iterator.next();
Term deriTerm = curTerm.deri(c);
deriExpr.addTerm(deriTerm);
}
return deriExpr;
}
//Power:
public Factor deri(char c) {
if (c == character.charAt(0)) {
//dx(x^a) = ax^a-1
//......
return new ExprFactor(deriExpr, 1);
} else {
//dx(y^b)
return new Number(BigInteger.ZERO);
}
}
第一次作业没有出现bug。第二次作业在互测和公测中出现了两个bug,一是在合并同类项时的逻辑判断出现问题,具体表现为少了一句break,导致指数因子部分合并同类项时判断混乱;二是对于exp()^0进行输出时,没有考虑到只有exp()^0且系数为1的情况,在此情况下没有输出,增加特判即可解决。第三次作业在互测中出现了一个bug,原因是没有考虑到只有exp()^0且系数为-1的情况(这说明上次的bug修复并不完善),修改上次增加的特判即可解决。
本人在作业中主要对于边界情况进行测试,例如各种系数和指数为0,1,-1的情况。在第一次互测中测试出一个bug,其原因就是结果为1时缺少输出。再加上本人也在边界情况出现错误,这提醒我们写代码需要考虑周全,尤其注意对于各种特殊数据正确性的检验。
通过本单元的学习,我对面向对象的编程方式有了更深刻的认识,对自顶向下分析法也有了新的体会。在完成作业的过程中,我对java这门面向对象程序设计语言也有了进一步掌握。
希望弱化性能分占比。仅保证程序正确性的前提下,已经能初步了解和掌握面向对象程序设计思想。一味追求输出的简短,与面向对象思想关联度并不是很高。



