


301
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享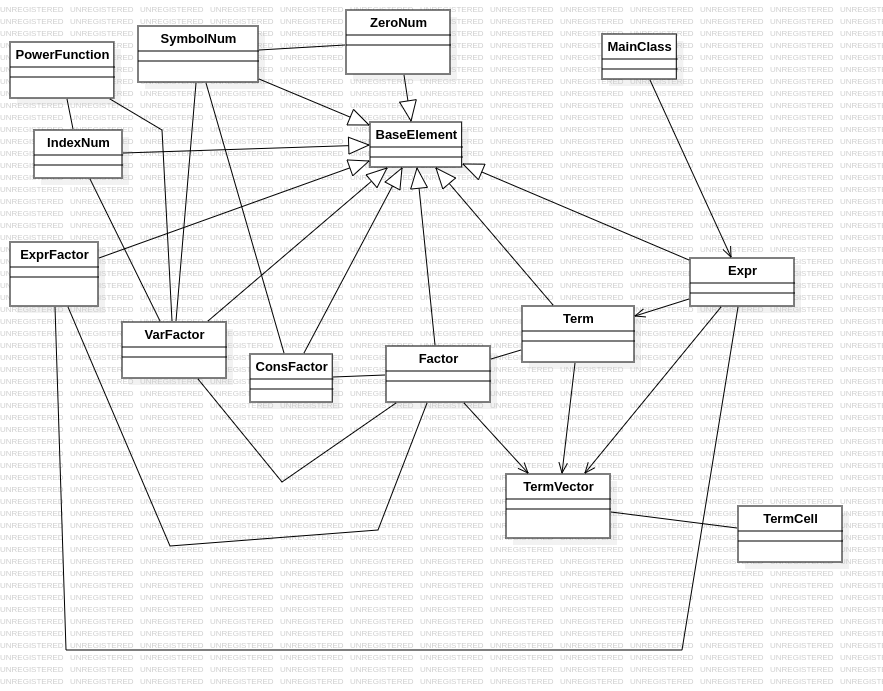
类图如上。
类凡14种。
代码凡535行。
根据第一次作业的形式化描述,建立元素相应类。所有元素类皆继承BaseElement类,此类规定元素的基本行为和数据。即解析元素和该元素在原字符串中的长度。
上级元素类实例化下级元素类以完成解析。

类图如上。
类凡18种。
代码凡980行。
类名或代码行数,皆前三次作业之最。
思路如第一次。
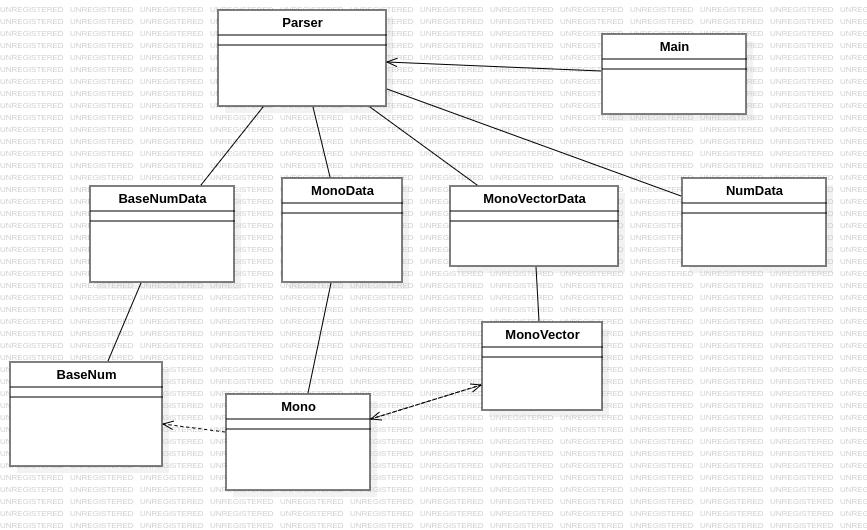
类图如上。
类凡9种。
代码凡935行。
架构大幅优化,详情后文。
三次作业,两次重构。
一个元素对应一个类。
每个元素类都负责解析并存储元素信息。
因此定义BaseElement类,规范接口行为。
在因子Factor一级,用TermCell和TermVector分别存储基本项和表达式。
基本思路如第一次作业,但进行重构。
因为第一次作业中的TermCell和TermVector已经不能满足本次的需要。
新增了BaseNum类,以便把指数函数和幂函数统一管理。
在此基础上,创建Mono和MonoVector类,管理基本项和表达式。
思路大改,二次重构。
使用Parser类统一实现解析功能。不再为每一个元素单独设计存储类,而是根据返回数据的类型设置存储类。
类的数量减少,工作量减少,但是设计起来更方便了。
exp(-x)
如上的表达式不合法,但是我的程序有可能输入它。因为判断常数项的时候我只考虑了绝对值,因此-1和1作为常数项有相同的效果。
exp(dx(...))
exp内部应当是因子,我的程序在进行解析时,会先运算dx的结果。但是dx的结果有可能为项或者表达式,这会导致程序解析错误。因此,应当把exp内部作为表达式解析为宜。
前三次作业中,基本项的底数有两种情况,一种为e,一种为x。为了拓展性,我统一二者于BaseNum类。管理方便,只需在toString()方法内考虑二者的不同。
第三次作业中,我的Mono类和MonoVector类一旦完成初始化,值就无法改变。这样可以很大程度上避免浅拷贝的问题,并且也不会使用太多内存。
在写代码之前,应当审慎地考虑代码的架构和类的特性。
互相促进,共同提高。



