



301
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享任务简介:对读入的表达式进行处理,支持自定义函数、求导等操作,要求最终输出的表达式只保留必要的括号,同时可对表达式进行自主化简以提高性能分数。
作业要求:读入一个包含加、减、乘、乘方以及括号(其中括号的深度至多为1层)的单变量表达式,输出恒等变形展开所有括号后的表达式。
代码架构分析:
在hw1中,需要从零构建起表达式的处理机制,同时要求架构有比较好的可拓展性,最终确定的处理流程如下:
下面我们以表达式( x++1)^3 --19*x为例,对处理过程进行说明
表达式预处理
由Processor工具类完成两项操作:
(x+1)^3+19*x的形式表达式解析
表达式解析可分为两个部分
Part1 给表达式中的每一个成分“定性”
以(x+1)^3+19*x为例,我们如何知道+是加号,如何将19作为一个整体存取并以标注它为一个数字?此处采用的方法是用Token类来储存每一个成分,依靠词法分析器Lexer遍历字符串将各成分独立出来并进行标注。
public class Token {
public enum Type {
ADD, SUB, MUL, LPAREN, RPAREN, NUM, ARGU, EXP
}
private final Type type;
private final String content;
}
public class Lexer {
private final ArrayList<Token> tokens = new ArrayList<>();
}
至此,我们的表达式解析为Lexer中列表tokens,例如19就是列表的第九个元素,是一个Type为NUM,content为19的对象。
Part2 利用递归下降法进行语法分析
这部分将对表达式进行语法分析,建立起表达式的结构层次。该工作由Parser类完成,依照设定的形式化表述,我们将表达式分为一个个加号连接的项(Term),而又将项分解为乘号相连的不同因子(Factor),由于因子的形式多样,Factor实际上是一个接口,对于不同的因子类型单独建类并作为Factor的子类。
public class Parser {
private final Lexer lexer;
public Parser(Lexer lexer) {
this.lexer = lexer;
}
public Expr parserExpr() {
ArrayList<Term> terms = new ArrayList<>();
terms.add(parserTerm(sign));
while (/*仍有项未解析*/) {
//继续进行项的解析
}
...
}
public Term parserTerm(int sign);
public Factor parserFactor();
}
在完成这部分工作后,表达式已经抽象出层次结构,可以表示为如下形式:
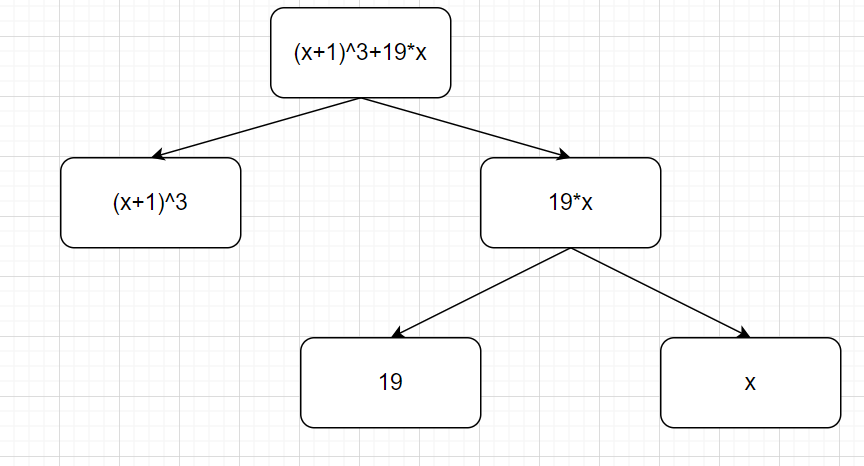
转多项式
这部分将对解析后的表达式进行展开,对于展开后的表达式,可以表示为$\sum$coe*x^exp,即一个多项式的形式,所以新建了Poly(多项式类)和Mono(单项式类)以完成表达式的展开工作。
表达式转为多项式,可认为是表达式中的每个项转为多项式后再相加,而项转为多项式,则可认为是每个因子转为多项式后再相乘。因此,只需要在Expr、Term、Factor等类中写出toPoly()方法,即可自下而上地构建出表达式的多项式。
因子的多项式形式多为只有一个单项式(Mono)的多项式(Poly),但对于表达式因子而言,由于可能具有指数,所以在将表达式因子的“底”(因子括号中的内容,类型为Expr)转为多项式后,需要进行乘方操作,所得到的结果多项式才是最终表达式因子所返回的多项式。
public class Poly {
private ArrayList<Mono> monoList;
public Poly(ArrayList<Mono> monoList) {
this.monoList = monoList;
}
public Poly addPoly(Poly theOther);
public Poly mulPoly(Poly theOther);
public Poly powPoly(Poly theOther);
...
}
public class Mono {
private BigInteger coe;
private int exp;
...
}
经过这步后得到多项式1*x^0+22*x^1+3*x^2+1*x^3
输出字符串
在这一阶段,我们要把得到的多项式转化为字符串进行输出。Poly实际上就是$\sum$Mono,所以多项式转为字符串只需要将单项式转为字符串后用加号连接即可。这部分主要的工作是对单项式进行化简,主要考虑到下面几种情况:
调用多项式toString()方法后得到我们最终输出的结果1+22*x+3*x^2+x^3
作业要求:读入一系列自定义函数的定义以及一个包含幂函数、指数函数、自定义函数调用的表达式,输出恒等变形展开所有括号后的表达式。
迭代内容:在HW1的基础上,需要增加以下几点
迭代内容的实现
括号嵌套
基于HW1的架构,该功能已经实现。
自定义函数因子的实现
将实参代入函数表达式后得到的表达式仍符合HW1中形式化表述,可以转化为原有问题的求解,所以这一步我们只需要考虑如何实现自定义函数的替换,具体实现如下:
新增工具类Definer,完成对自定义函数定义式和形参列表的储存。在读入自定义函数时,调用addFunc()方法,Definer中的两个HashMap分别储存函数的定义式和函数的形参列表,其中Key值都为自定义函数的函数名。
public class Definer {
private static HashMap<String,String> funcMap = new HashMap<>(); //函数定义式
private static HashMap<String, ArrayList<String>> paraMap = new HashMap<>(); //函数形参列表
public static void addFunc(String input);
public static String callFunc(String name,ArrayList<Factor> actualParas);
}
新增FuncFactor(自定义函数因子类)。在解析因子时,若解析到的是自定义函数因子,则通过Parser中新增的paeseFuncFactor()方法,对自定义函数进行解析,返回一个表达式因子作为解析的结果。具体来说,当获得函数名和实参列表后,可在Definer中对该函数名对应定义式中的形参进行字符串层级的替换,再对新得到的字符串进行解析,就可以得到一个解析好的表达式因子,该表达式因子就作为自定义函数因子解析后的结果。如此一来,新的问题转化为了原有的问题,依靠HW1所建立的处理机制得到最终的结果。
public class FuncFactor implements Factor {
private String newFunc;
private ExprFctor expr;
public FuncFactor(String name,ArrayList<Factor> actualParas) {
this.newFunc = Definer.callFunc(name,actualParas); //替换后的字符串
this.expr = setExpr(); //对得到的字符串进行解析
}
private ExprFactor setExpr();
...
}
指数函数因子的实现
本次作业的“指数函数”特指以e为底数的指数函数,一般形式为exp(<Factor>)^<指数>,当指数为1时,指数符号和指数可以省去。对于新增的指数函数因子,主要进行两个方面的改动:
ExpFactor(指数函数类),同时为了方便后续的计算,如果指数函数后跟有指数,我们根据指数的计算方式将指数放入括号中,即指数函数的储存形式是exp(<Poly>)。当指数为1时,调用Factor的toPoly()方法即可得到expPoly,若存在指数,只需要多进行一次多项式相乘(HW1已实现)即可。public class ExpFactor implements Factor {
private Poly expPoly;
...
}
ceo*x^pow*exp(Poly)的形式。public class Unit {
private BigInteger coe;
private BigInteger pow;
private Poly expContent; //exp括号中的内容
...
}
作业要求:读入一系列自定义函数的定义以及一个包含幂函数、指数函数、自定义函数调用、求导算子的表达式,输出恒等变形展开所有括号后的表达式。
迭代内容:在HW2的基础上,需要增加以下几点
迭代内容的实现
函数表达式调用其他“已定义”函数的实现
根据HW2中自定义函数的替换机制,我们已经实现了该功能。
求导算子的实现
求导因子 → 求导算子 空白项'('空白项 求导因子 空白项')'|求导算子 空白项'('空白项 表达式 空白项')'
求导算子 → 'dx'
实现求导算子,最重要的是将求导过程层次化实现
新增DerivativeFactor(求导因子类),在解析过程中对求导因子进行管理
public class DerivativeFactor implements Factor {
private Expr base; //base为求导因子括号中的表达式
public DerivativeFactor(Expr base) {
this.base = base;
}
}
在表达式转为转多项式这一过程中,求导因子的返回值应该是对base求导后得到的多项式,所以我们需要在Expr、Term以及Factor中新增toDer()方法,并且返回的类型设为Poly,我们根据给出的求导公式即可写出各类型的toDer()方法。特别地,由于求导因子也可能出现在base中,那么DerivativeFactor中也应该有toDer()方法,该过程相当于对base求二阶导。具体实现是:
调用base.toDer()方法得到base的一阶导(一个Poly类型)
调用Poly.toString()得到一阶导字符串形式
将得到的字符串再次进行解析得到一个表达式
调用Expr.toDer()得到二阶导(Poly类型)
第二三步的过程实际上就是对表达式解析过程的一个重复,实现方法的复用即可。
若在迭代过程中引入求和函数sum(i,求和下界,求和上界,求和表达式),若求和表达式符合形式化表述中因子的定义,如何进行求和函数的解析和表达式的展开?
sumFactor对求和函数因子进行管理,与自定义函数的解析类似,在Parser中新增parseSum()方法,对函数求和上下界和求和因子进行解析即可。经过上述处理后,我们的多项式即可沿用之前的方法进行化简输出,并且不需要对其余部分进行过多的改动,证明最终设计具有一定的可扩展性。
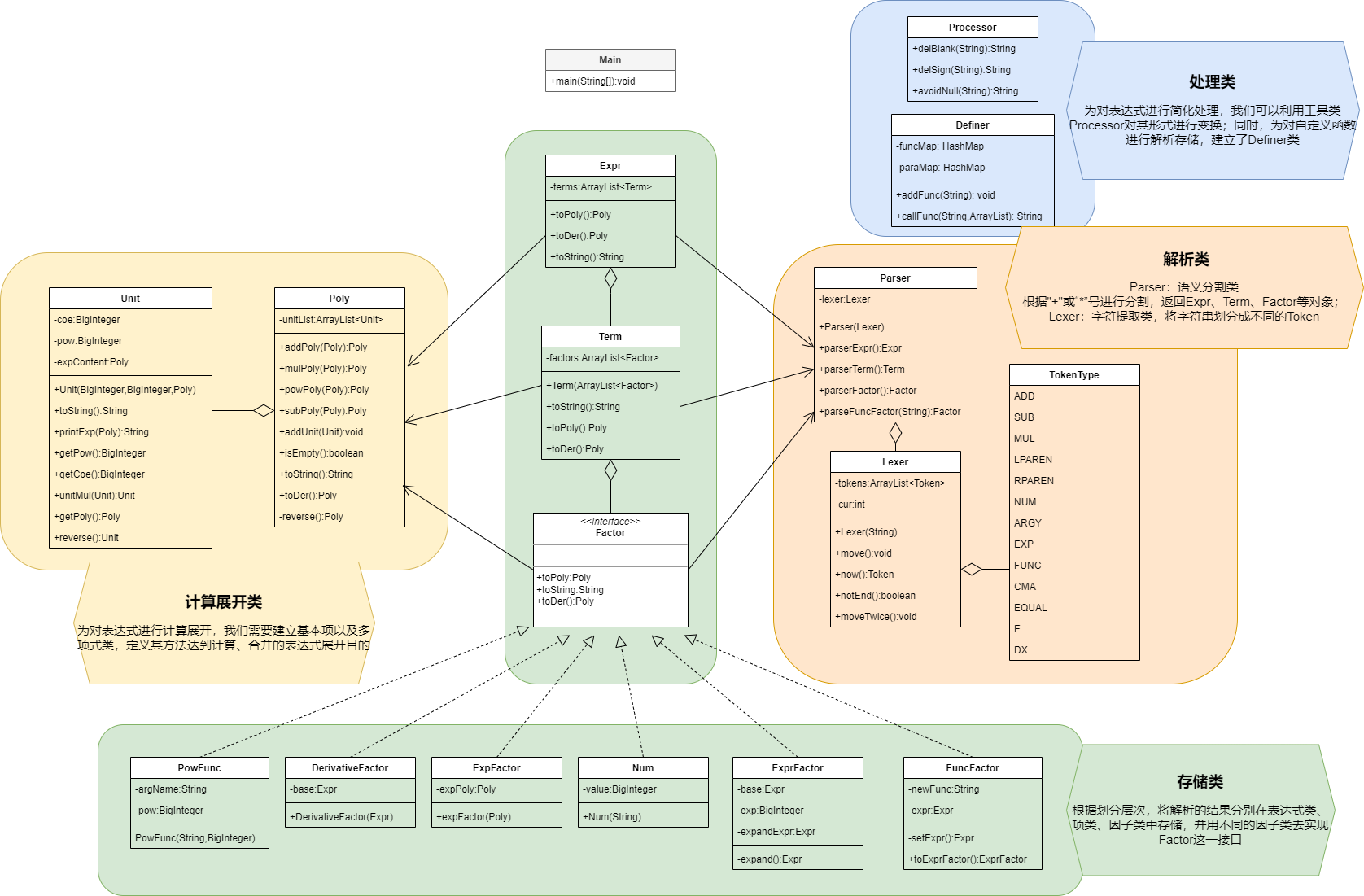
UML类图
Statistic analysis
Class metrics
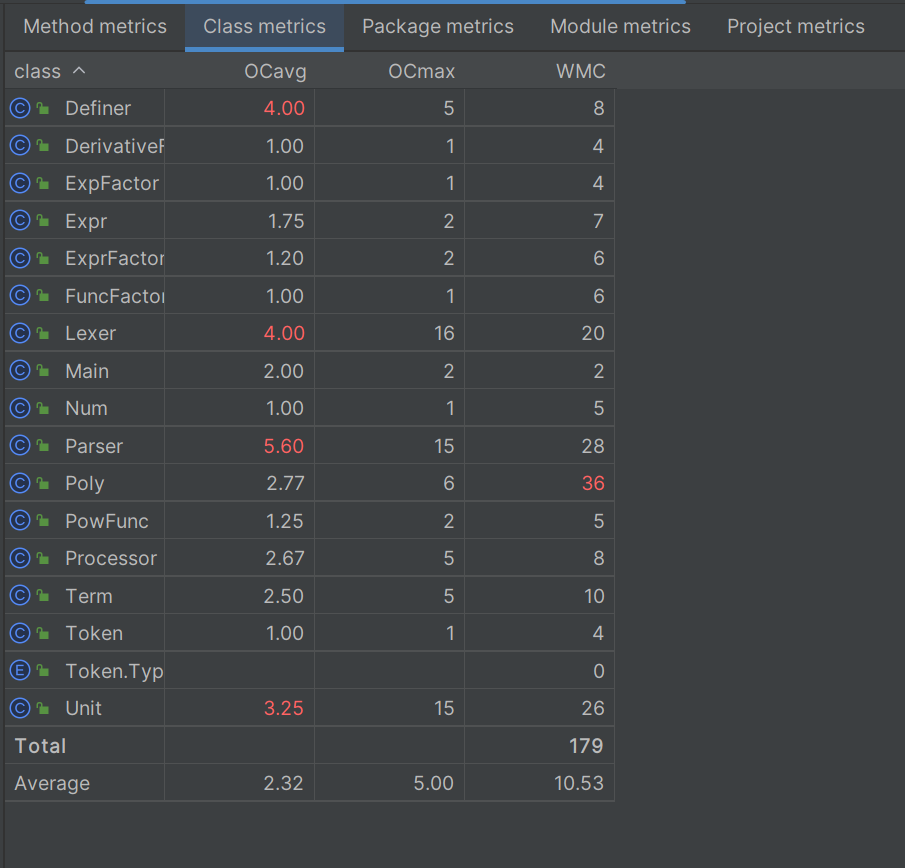
OCavg:类的平均操作复杂度
OCmax:类的最大操作复杂度
WMC:类的加权方法复杂度
像Parser、Lexer、Definer等类中,使用了较多枚举,所以类的平均操作复杂度较高,但整体在可接受的范围内。
Poly中多项式计算等操作较为复杂,导致类的加权方法复杂度较高。
Method metrics
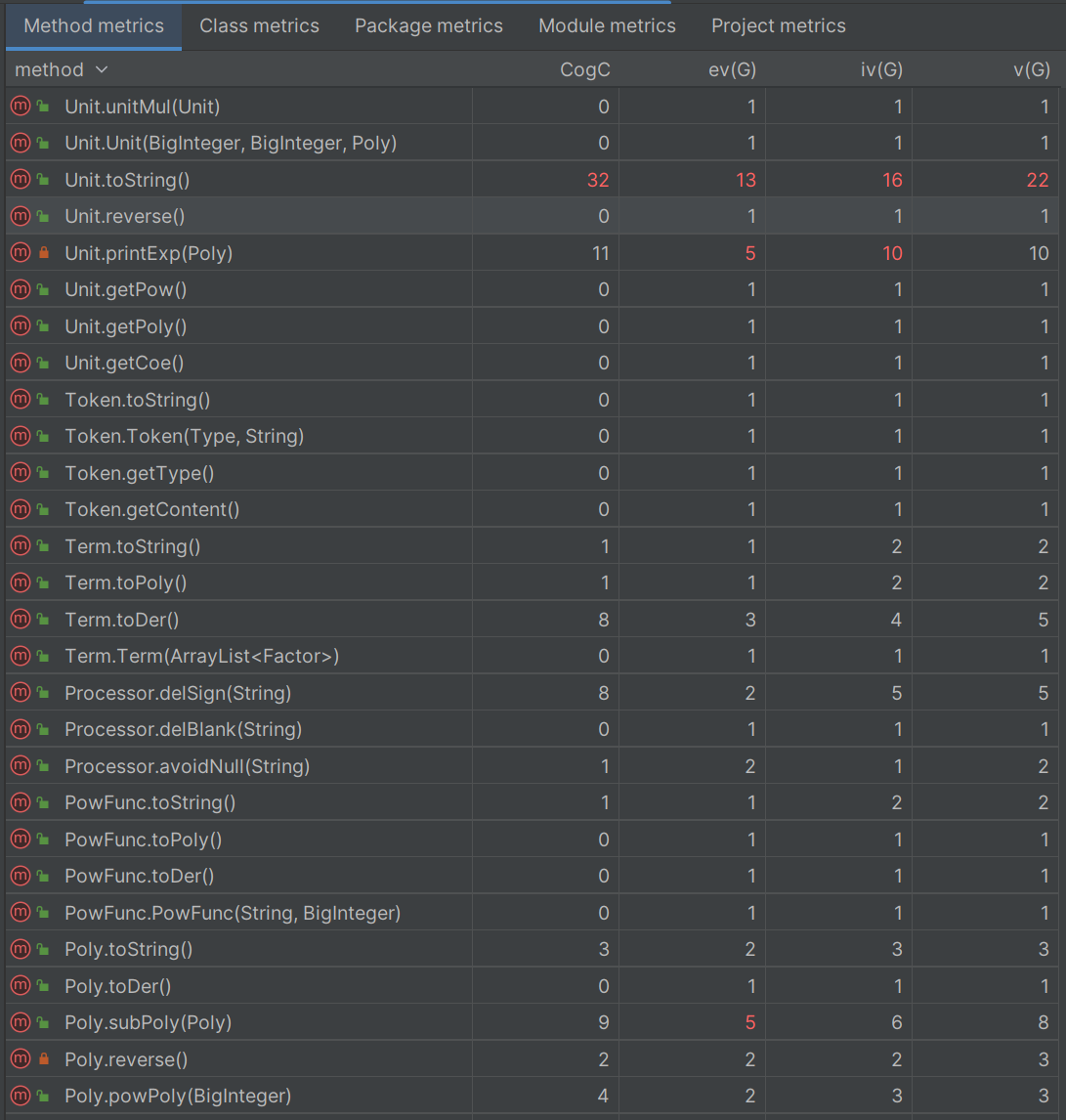
CogC:方法的认知复杂度
ev(G):方法的基本圈复杂度,用于衡量程序非结构化程度
iv(G):方法的设计复杂度,用于衡量模块和其他模块和其他模块之间的调用关系
v(G):方法的圈复杂度,数量上为独立路径的条数
大多数方法的复杂度在合理范围内,像Unit类中的toString()方法,用于将单项式转为字符串,需要针对每一种情况进行考虑,需要大量枚举特判,复杂度较高。
出现的bug
在hw2中,将基本项Unit变为ceo*x^pow*exp(Poly)的形式,若exp中没有内容,我将其设置为一个ArrayList为空的Poly,这个处理会带来一些问题,比如在合并同类项时,我们需要比较两者exp中的Poly是否相等,当Poly为空时,addPoly()在处理中可能会出现空指针等问题;同时,空Poly和一个只有一个单项式但值为0的Poly事实上是等价的,但是在比较中往往会认为它们不等,导致合并过程中出现问题。
在hw3强测中,求导函数因子的toString()方法出现错误,没有在两侧补上括号,在对x*d(x^2+x^3)等式子进行替换时,会出现x*2*x+3*x^2等错误形式,虽仍符合表达式形式化表述,但数学意义发生了改变,解析结果不再相同。
前一个bug是由于设计上的不严谨导致的,没有考虑到空数组会带来的问题,或许可以用更加得当的方式对没有内容的exp进行表示;后者则是细节问题,同时也是测试上的疏忽,应该考虑到该方法的调用情形,考虑到求导结果多于一项时的正确性问题。
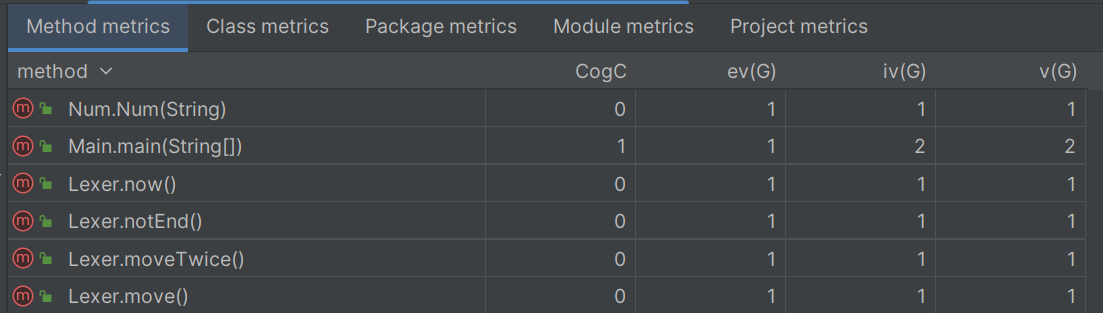
出现了bug的方法的复杂度:


互测策略
利用自动评测机
对自己程序中的bug、讨论区中提及的问题进行记录,构造样例进行hack
在每次hack中,针对迭代的部分进行测试
在本次作业中,大多数同学的代码设计结构都是类似的,只有在细节或是优化处理上的方式有所不同,所以运用上述第二点进行测试用例的构造时效果较好。同时,由于是迭代开发,所以每一次的测试重点应该放在新增部分,这一点可能在本次作业中有所忽视,希望下次互测时可以进行更好地针对性打击)
起步无疑是艰辛的。
由于没有重视oopre课程和及时复习,第一次作业发出后多少有点无从下手。反复阅读指导书、公众号以及学长博客后,开始依葫芦画瓢搭建自己的架构,潦草上交完事。但是第二次作业继续上强度,经历了几次推倒重来才确定了最终的迭代策略,没有进行细节上的推敲和优化。直到第三次作业,我才开始思考我是否在“面向对象设计与构造”,每个设计是否是因为合理才选择的?
讨论贴和研讨课中同学们的观点给了我很多启发思考,无论是可变类和不可变类的区别,还是深浅克隆的选择问题,或者是更深一层的设计原则的思考,都在提醒我要走到每次作业的背后,学习如何更好地设计。此外,在完成作业的过程中,很多同学和我进行了架构上的交流,这都帮助我更好地完善了我的设计。所以总体来说需要:
* 积极交流 多思考总结
* 充分测试 寻找优化的可能性
* 留好拓展空间
* 代码不宜冗长
或许万事开头难的真正含义是,当你开始做的时候,一切都会越来越好。希望今后的OO学习能够顺利,祝学有所成。



