


301
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享第一单元的三次作业都围绕着表达式的解析与化简 通过该主题进行了面向对象编程的实践 在过程中发现自己许多问题
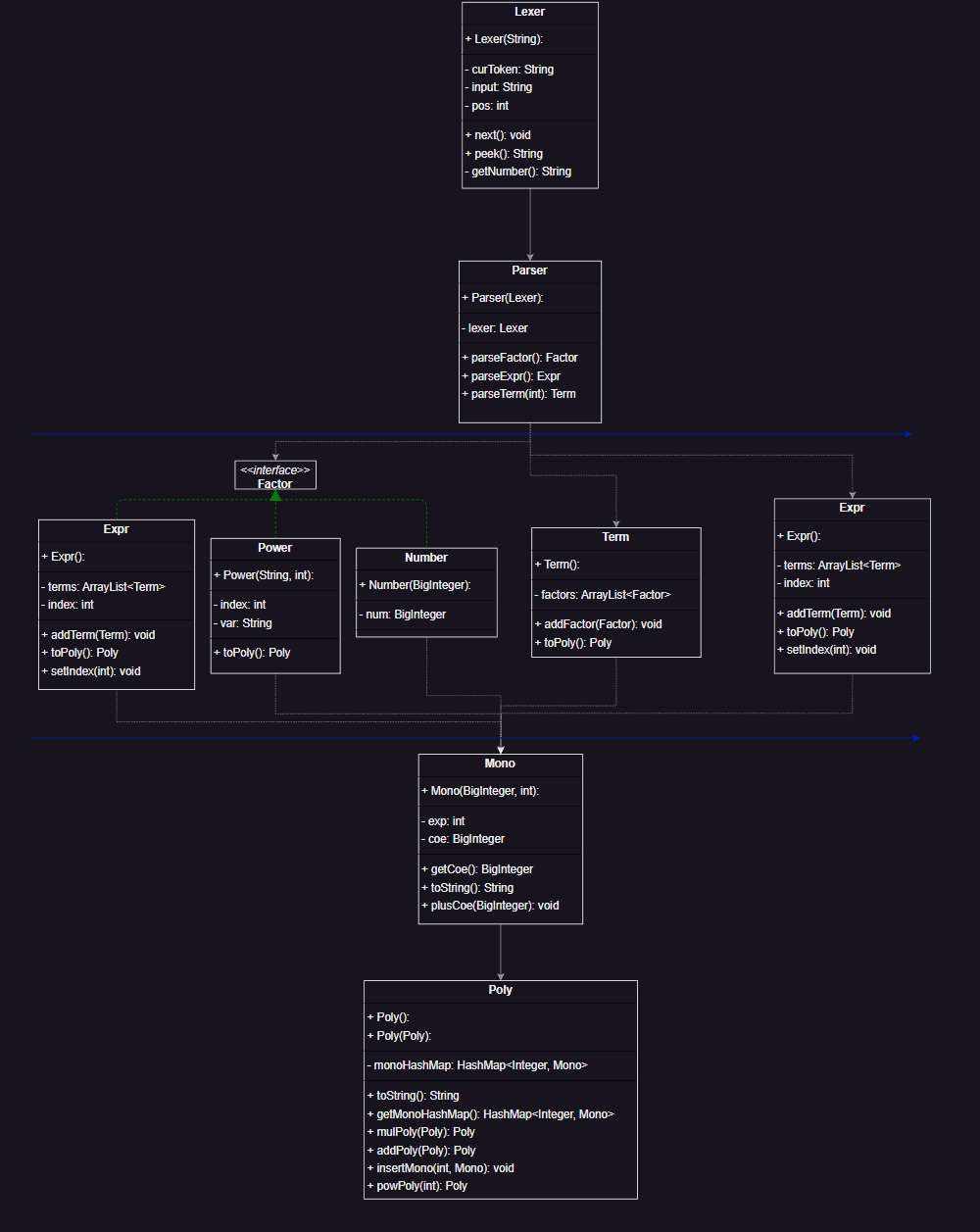
从面向过程的时序分析
预处理部分 我主要做了两步 将连续的正负号化简成1个 以及消除所有的空格 这样解析的逻辑就可以不用考虑这些
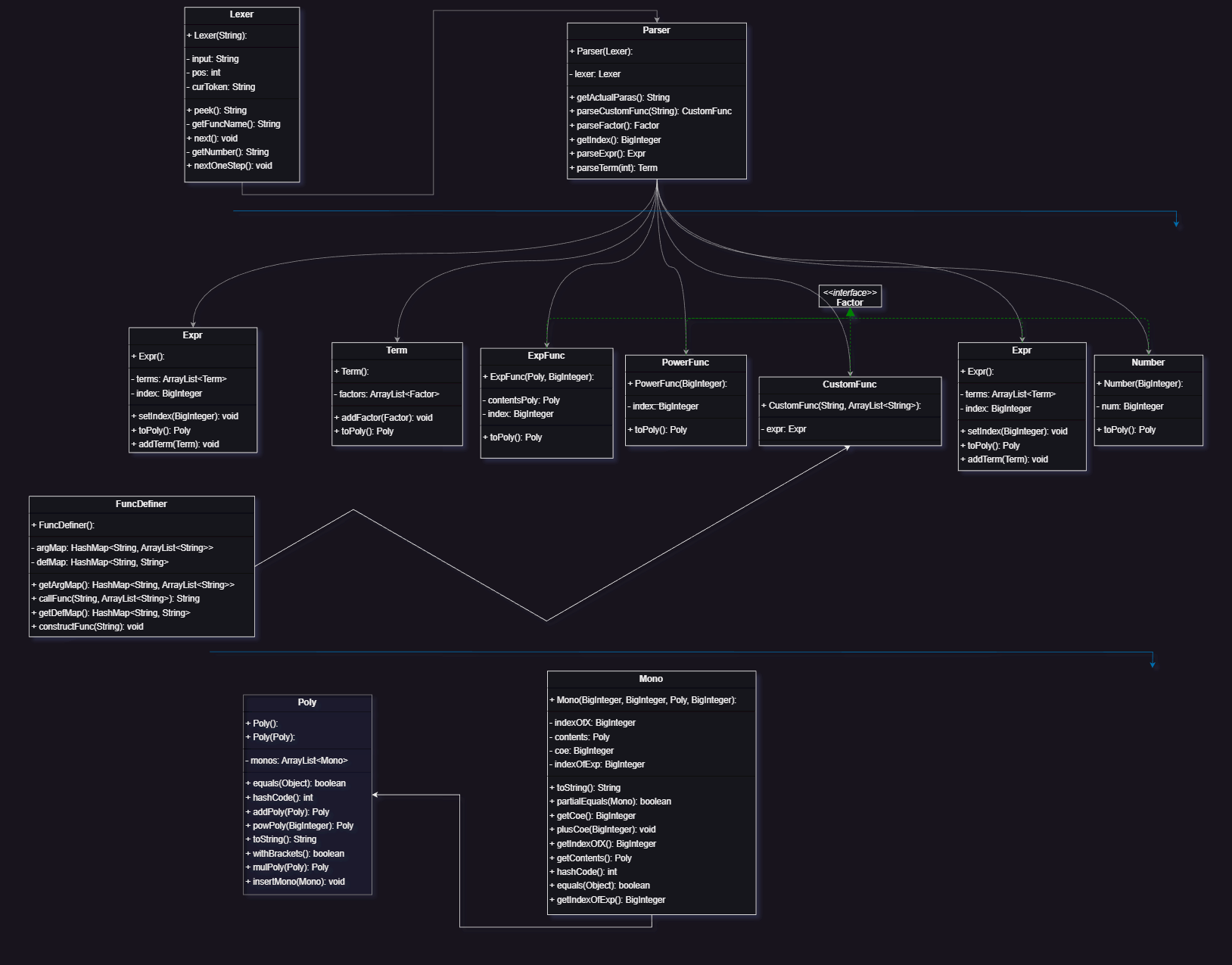
其中的解析 就是读取处理后的输入在逻辑上把各种类(Expr Term Factor) 组织成表达式树
在UML图中可以看到 Expr Number Power等实现了Factor 接口 从而在建立表达式树的过程中加入其中
我认为 第三步的化简是贯穿三次作业的重要一步 我结合了往届博客的经验 采用Poly-Mono的模式
这种模式的好处有
在实现toString 时 我采用了 TreeMap 因为第一次只有 x^n 所以我干脆按照幂次直接合并 同时输出按照降序 这样较为简单直接
但是在之后加入exp 就需要重构 有利有弊
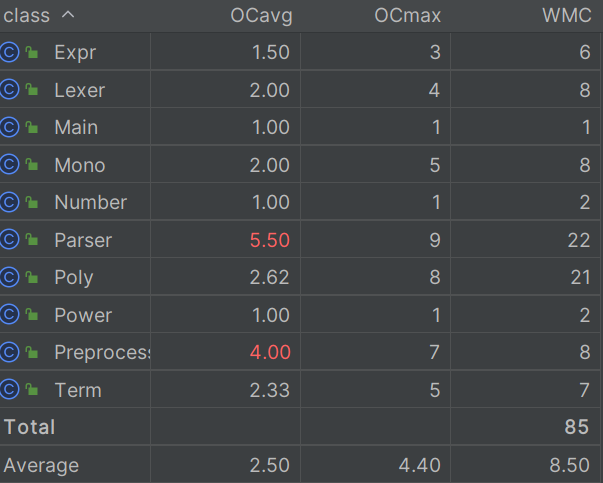
这里Preprocesser 的复杂度高是因为我在消除重复正负号时用的是扫描判断
实际可以用正则表达式的
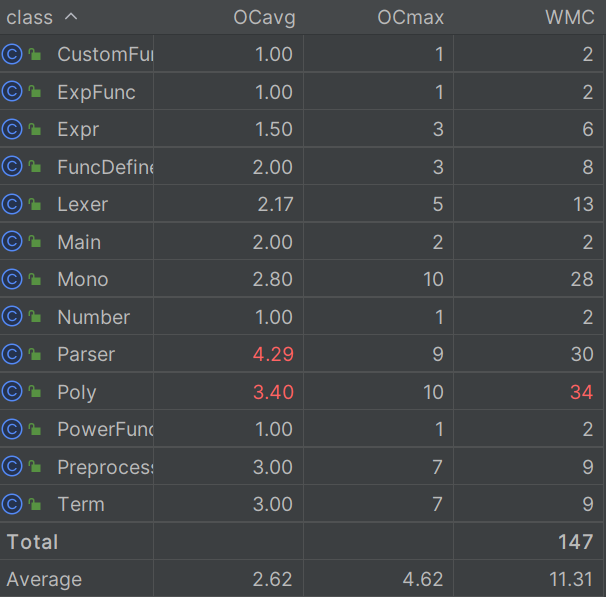
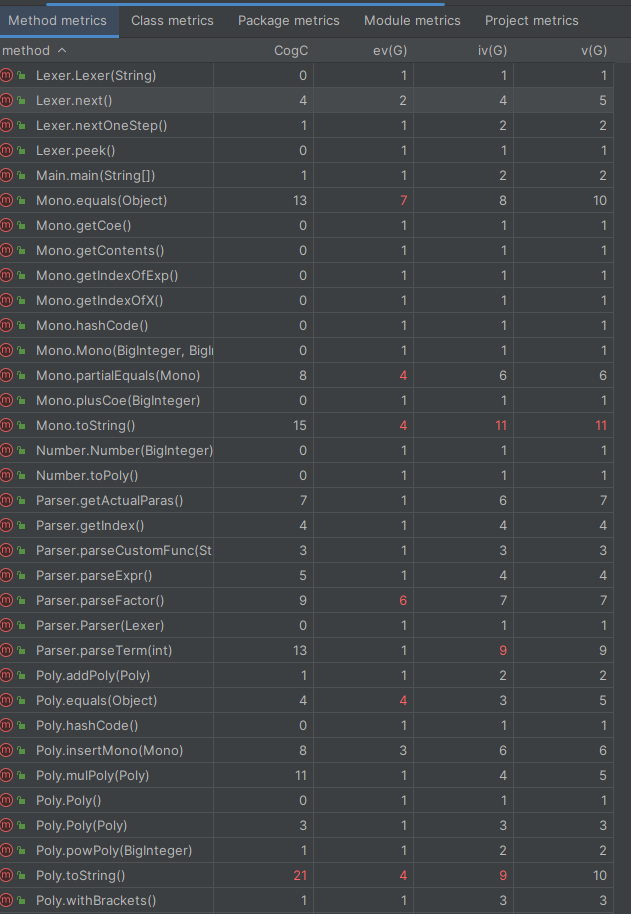
Parser类的OCavg(类平均圈复杂度)最高,这是因为Parser类是类似有限状态机的一种解析器,需要对当前状态(curToken)进行判断以得出下一状态
Parser 中明显使用了 大量的条件判断和调用函数 因此平均圈复杂度最高
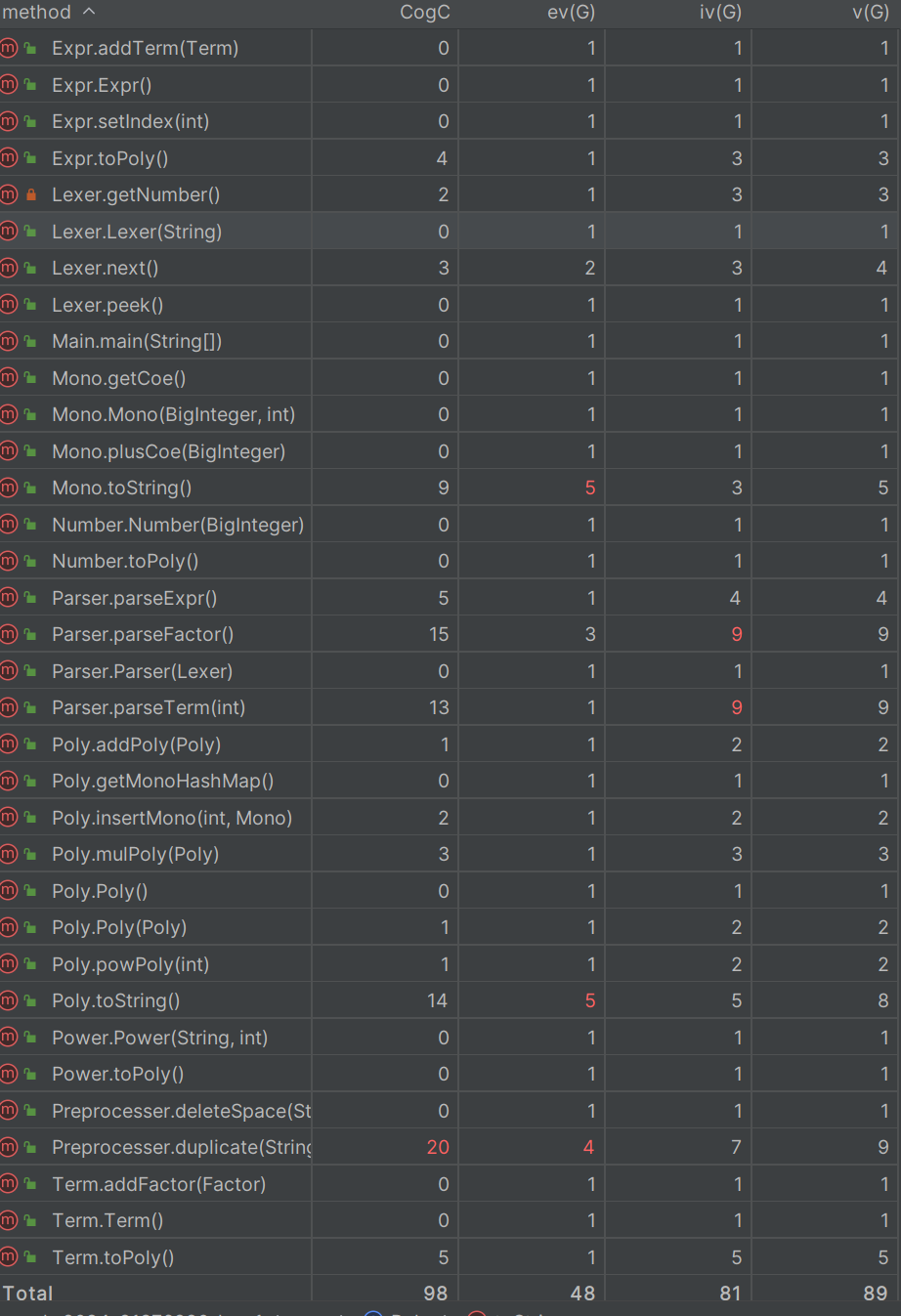
Preprocesser的duplicate前面说了
ev(G) 表示基本复杂度 衡量非结构化程度 高意味着难以模块化和维护
iv(G) 表示模块设计复杂度,它用来衡量模块之间的调用关系 越高 模块之间的耦合性越高,越难隔离、维护和复用
toString 方法的设计使用了较多的条件判断 导致基本复杂度高
而parse方法由于递归的存在使得耦合的程度增高 这个是程序架构的问题
在接下来的学习中,要进一步注意方法的解耦,尤其要避免方法中使用一大串的条件判断语句和循环语句
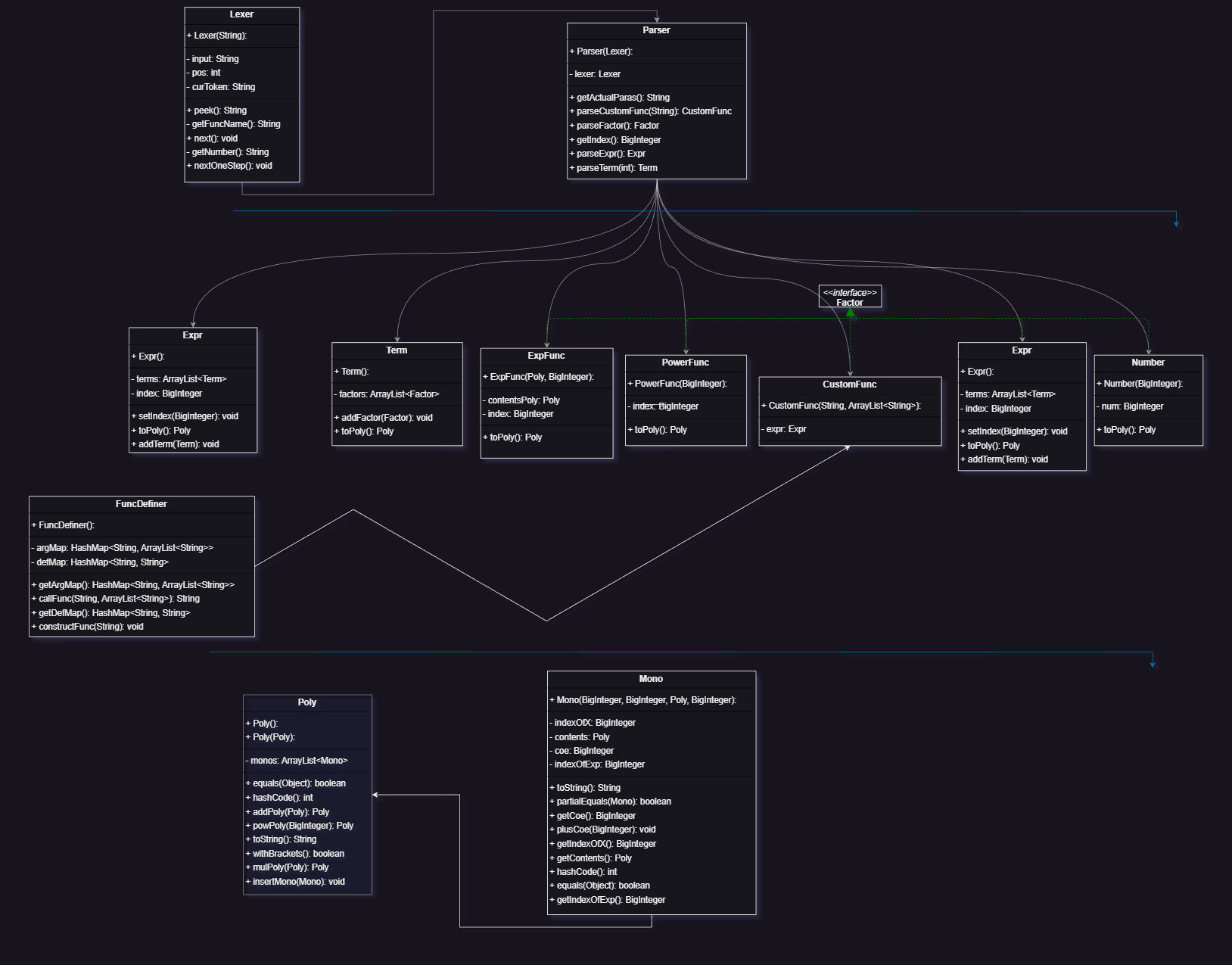
从面向过程的时序分析
预处理和之前一样
解析输入还是递归下降法 比较大的不同是,在读入函数定义时,需要对形式表达式和形式参数进行保存。而在解析表达式时,遇到函数调用则先解析形式表达式,之后才代入实参
简单地说 函数调用这里要先替换处理 然后才保存到表达式树中
化简这一步则涉及到架构的较大改进
我认为从第一次作业到第二次作业增加的要求中 自定义表达式并不是很大的威胁
自定义表达式只是增加了工作量
对于架构的冲击主要在于exp的处理涉及到表达式定义与类的设计方面的问题
Lexer lexer = new Lexer(input);
Parser parser = new Parser(lexer);
Expr expr = parser.parseExpr();
Poly poly = expr.toPoly();
System.out.println(pr.duplicate(poly.toString()).
replaceAll("-1\\*x", "-x"));
回顾作业1 的Main 的主要步骤
第一步 parse:lexer 和 parser 的构造 可以看作是表达式树的构建
第二步 poly 的构造则是将表达式树逐层改写成[多项式] 的形式
第三步 poly调用toString方法将类组织起来的逻辑上的多项式化成字符串的形式
不考虑可以带入自定义表达式
那么我们在作业1的基础上只增加了指数函数这一个要求
在作业一的架构中 是通过上述的方式完成的
如果直接照搬 导致:
由于作业2允许指数函数嵌套 作业1的基本项就要改变 本来是系数-指数就可以唯一表示一个基本项 相同则在调用insertMono时 就得以合并 而insertMono 又是在addPoly mulPoly powPoly 时被调用 所以是在"改写"这一步同类型的Mono得到了合并 最终的 toString 完全不涉及合并同类型项这一化简!!!
可以说在作业1中 在toString时的性能优化 非常简单 虽然效果很显著 但是方法上真的就是条件判断 重点是合并同类型项 所以很自然地我也希望在作业2中实现同类型项的合并
然而在作业2中 insertMono 的写法是一个挑战
有两个选择 一个是在parse 那就是要求一直剥到底 在解析每个exp的时候 就直接将每一层的exp都完全展开
另一个就是在parse之后 做这样的动作 总之是要把每一层都剥开
实现的是前一种思路 不断递归直到到了表达式的原子部分 回溯回来将这个类放到表达式树上
针对exp函数 需要考虑合并的问题 也就是insertMono的实现基础
我最终是这样处理的
// Poly
@Override
public boolean equals(Object obj) {
if (obj == null) {
return false;
}
if (obj == this) {
return true;
}
if (obj instanceof Poly) {
Poly p = (Poly) obj;
return this.monos.containsAll(p.monos) && p.monos.containsAll(this.monos);
}
return false;
}
@Override
public int hashCode() {
return Objects.hash(monos);
}
Mono也有完全类似的方法
如此 在合并的时候 就可以根据我规定的同类 进行合并
于是 addPoly mulPoly powPoly 这些需要合并的计算方法也就有了依据
自定义函数的处理
在读入函数定义时,需要对形式表达式和形式参数进行保存。
在解析表达式时,遇到函数调用则先解析形式表达式,之后才代入实参。
首先新建一个类实现Factor接口 用来表示自定义函数因子
定义成员变量
//FuncFactor.java
private String newFunc; //将函数实参带入形参位置后的结果(字符串形式)
private Expr expr; //将newFunc解析成表达式后的结果
public CustomFunction(String name, ArrayList<Factor> actualParas) {
this.newFunc = Definer.callFunc(name, actualParas);//调用函数
Lexer lexer = new Lexer(Simply.clear(newFunc));
Parser parser = new Parser(lexer);
this.expr = parser.parserExpr();//换成新的表达式变量
}
上面的构造函数承担了自定义函数的实参带入调用
为了便于自定义函数的定义和解析 新建了一个工具类Definer
主要处理自定义函数的定义和调用
该函数的成员方法都是静态的 意味着不需要实例化对象 直接通过类名Definer即可调用
//Definer.java
private static HashMap<String, String> funcMap = new HashMap<>();
private static HashMap<String, ArrayList<String>> paraMap = new HashMap<>();
funcMap 表示函数的函数名和函数体 函数名为key 化简后的函数体为value
paraMap 表示函数的对应变量形参表 函数名为key 形参表为 value
同时 Definer 有两个方法
addFunc 将函数定义中的函数名 函数体 形参表 也就是上面的那些在输入时就处理完成
接下来 由callFunc 调用函数 需要传入函数名以及一个实参列表 这样就可以通过两个Map 中存储的数据实现函数的调用 最终返回调用后的表达式字符串
如何实现自定义函数的解析 当读到 f g h时 就调用专门解析这个的方法
首先要解析出 实参因子 然后创建一个新的自定义函数对象 由这个自定义函数的对象的构造函数实现函数的实参替换 最后返回一个处理好的表达式因子 这样最后我们就只需要处理 这个处理好的表达式因子 也就是说 这个自定义表达式就化成了一般的表达式
这种处理的附带优势是 可以不用管定义的先后 我在自行构造样例hack别人时曾构造出
f=g 但是f定义在g前面 找到了有人的程序异常 后面才发现我的程序可以不管定义顺序 但指导书禁止了这一点
这个是我为了满足代码需求添加的
简单来说 规定 基本项
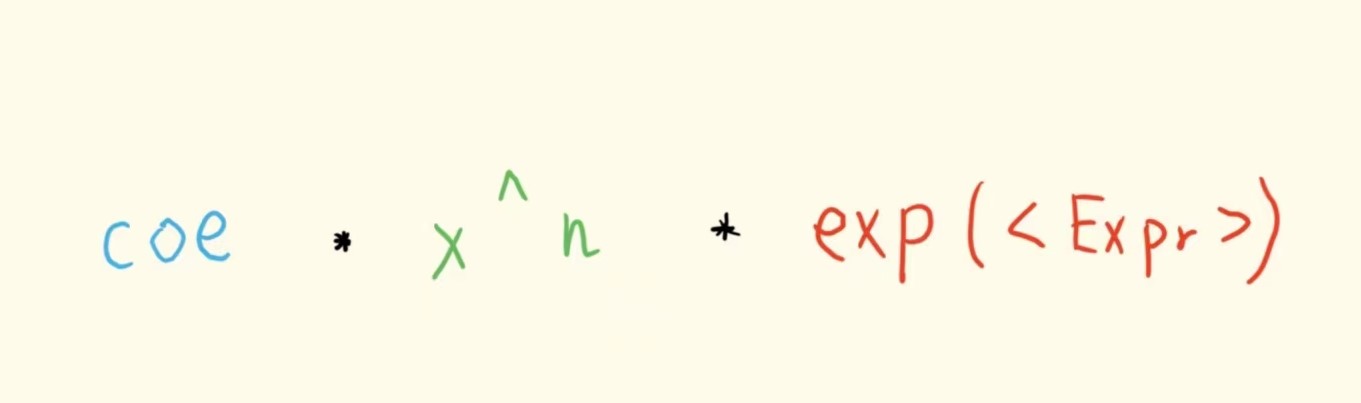
在合并的时候 要求基本项只有系数不同 也就是调用partialEquals
在判断是否相同时 比如exp里面的表达式是否是一个
这个时候就需要调用 equals
不然可能exp(1)*exp(-1)得到意想不到的结果
首先第一次的代码很多拿来直接用的
toString 之前提到了
patrtialEquals 和 equals 实现差不多 涉及到许多条件判断 因此ev(G) 基本复杂度偏高
parse之前也提到了 是上一次作业的遗留问题
从面向过程的时序分析
从第二次到第三次有点过于简单
基本上增加一个实现了Factor接口的求导类
在Poly 和 Mono中 分别增加求导方法
其中Mono 的toDiff是重点 需要考虑链式法则
我自测出的一个问题就是 exp() 中的表达式求导忘记乘了
代码增量不大
求导类和方法的复杂度也不显著
因此在复杂性度量上与上一次作业差别不大
自己的作业目前并没有被测出bug
在写作业的过程中 我对于调试的重视程度有了显著提升
之前在oopre的学习 我一直采用的是静态调试 也就是在自己的意识中思考这一行这样写的前后逻辑是否正确
可是这样在逐渐复杂的代码下(有时是自己对代码的理解与实际语法产生作业之间是脱节的 对java的语法毕竟不熟) 需要调试来看看到这一行位置,是否正确运行?
printf这种方式需要写system.out.println
而且也不是所有东西都有字符串输出的
还是看看调试
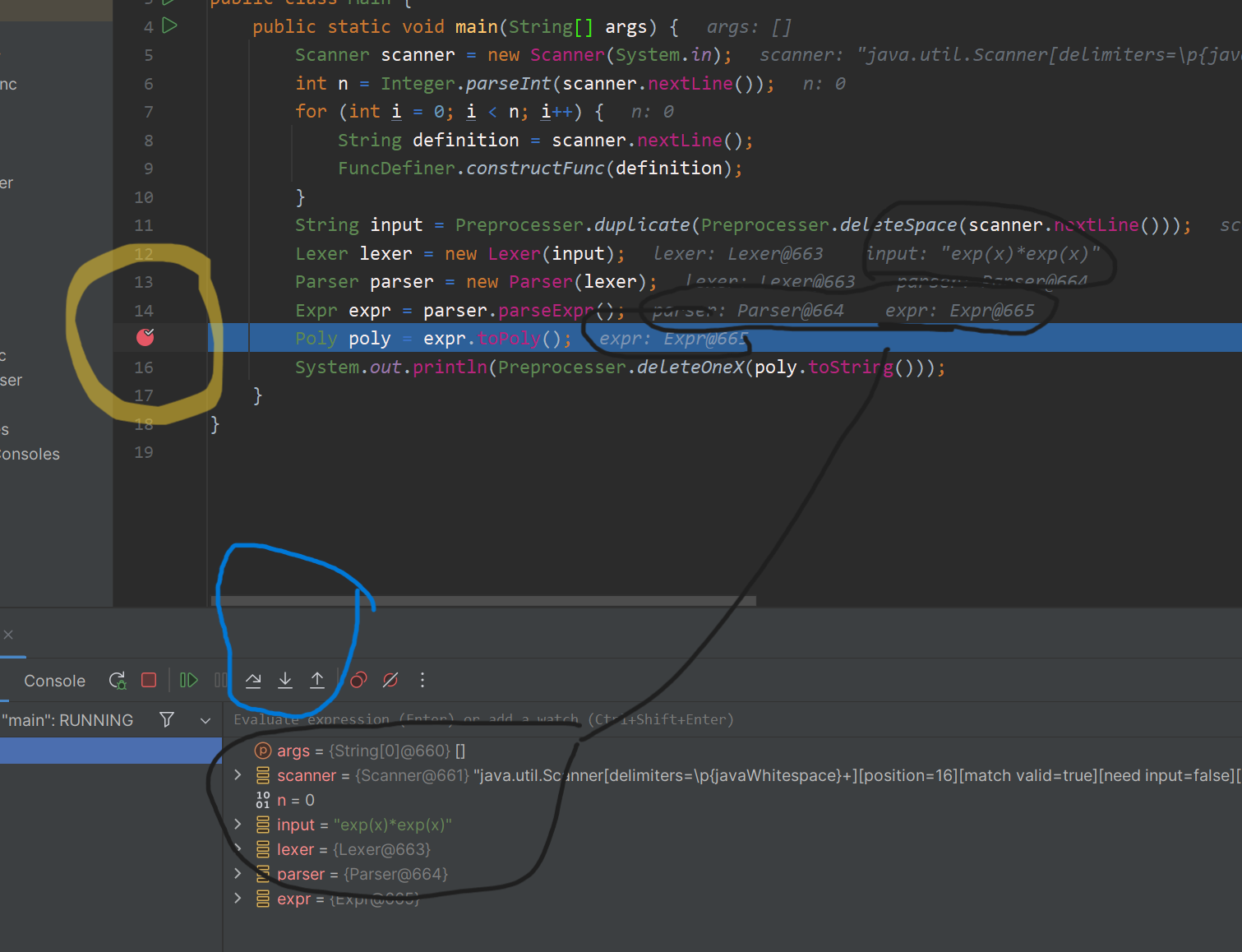
首先在希望停下来的地方设置图中黄框的断点
在IDEA中点击debug的标志后,
程序会 start-continue 到 breakpoint的位置
蓝框中的几个按钮从左到右分别是 step-over(next) step-into(step) step-out(finish)
意思都是显然的
值得一提: 边上的三点点开后有倒退的选项也是很有用的
最后是数据的显示 不仅下方可以显示 对于一些定义了toString方法的类 在程序的后面也可以自动显示字符串形式的结果 这就是IDEA的强大之处
这个功能对于第一单元的作业显然是很有用的
使用这种工具的好处是使得我高效快速的找到了程序的问题
本来我可能需要半天才想到是这里有问题 然后printf
现在我只需要跳到这里看结果 如果怀疑是上一步就出了问题 就直接回到上一步
就这样我确认了是哪些方法 比如 第二次作业的自定义函数解析 存在问题
然后予以改正 大大加速了我开发功能正常的程序的速度
可以说之前学C, 数据结构没有用 IDE的debug说明写的程序太少太简单了
第一次作业 我使用了往届的评测机 删除了三角函数的部分 采用Python调用命令行对jar 文件输入并调用python解析输出
加强了数据以后 成功找到同组两个人的问题 其中一个是部分符号是反的 另一个是一旦出现0项就可能产生bug
后两次由于限制比较多 我就采用了肉眼的方式 并未取得好的效果
我认为找bug
前两点是评测机做不到的 需要仔细阅读题目的文档
在这三次作业中我并没有大重构,主要得益于递归下降算法的天然优势和合理的需求预测
然后就是Poly-Mono的使用也助长了这一点
第一次作业有一个反面的教训 使用TreeMap 降序排列 实际上随着之后作业基本项变得复杂 这部分代码完全用不上了
因此以后在作业中要关注代码的可扩展性 为下一次作业的迭代做好准备
通过第一单元的学习 我对递归下降法有了一定的了解 与此同时对面向对象设计进行了一定的实践



