







301
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享经过一个月间的三次迭代,我终于完成了《面向对象设计与构造》(OO)课程第一单元的任务要求。以下是我的博客总结。
第一单元的任务是使用递归下降法进行表达式化简,分为三次迭代:
x 的非负数次方;常数因子为有符号的整数;表达式因子为表达式的非负数次方。f(x, y, z) = 函数表达式);自定义函数调用属于变量因子,其实参为因子(f(因子, 因子, 因子))。dx(表达式))。为了度量程序结构,我导出了程序的类图、代码数量和圈复杂度,并进行分析。
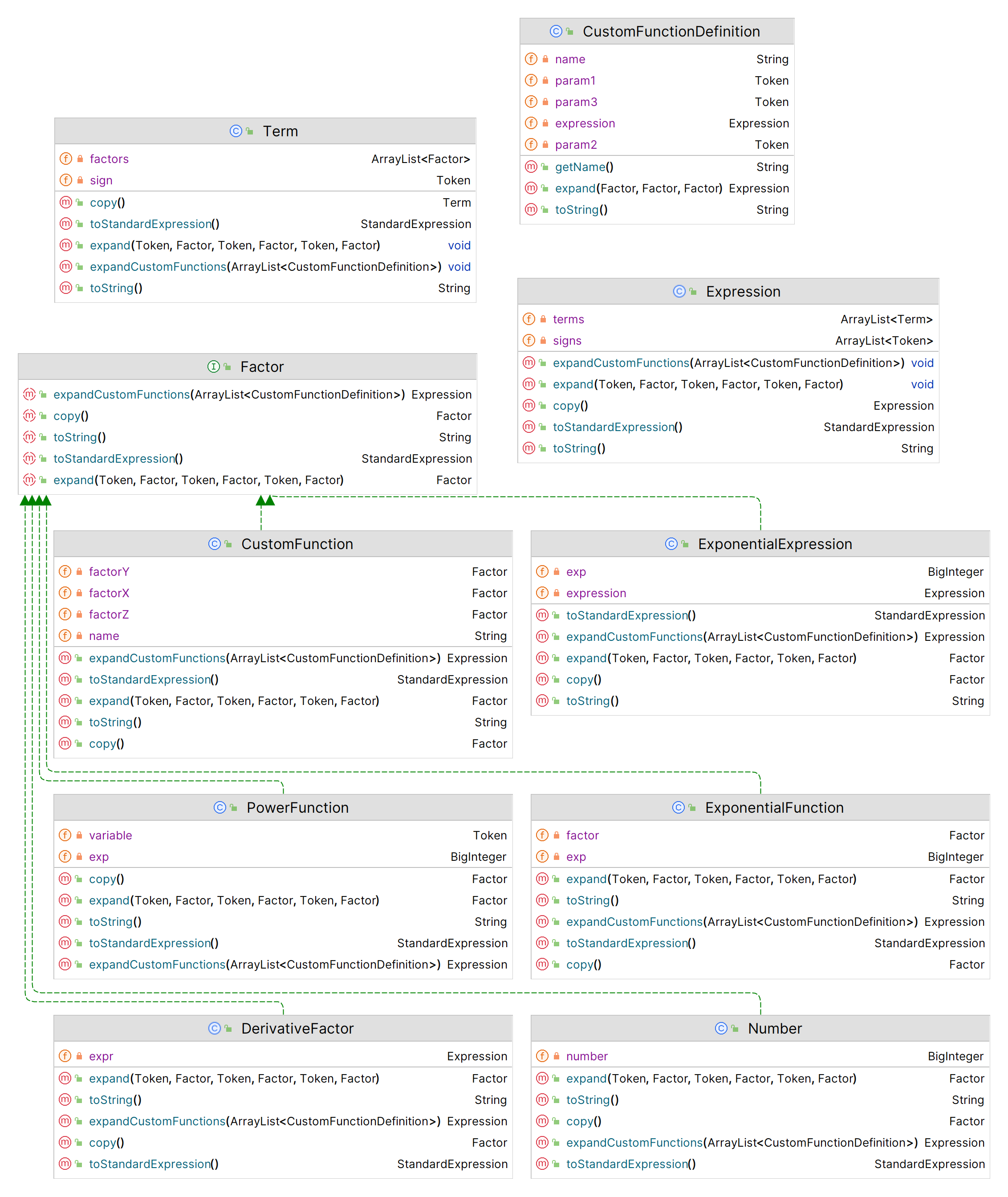
以下是使用 IDEA 导出的类图:
| 输入处理 | AST | 标准化 AST |
|---|---|---|
| 这些类负责输入、输出、词法分析、语法分析。 | 这些类用于建立抽象语法树(AST)。 | 这些类用于建立“标准化”抽象语法树,其结构比语法树更简单,便于进行化简等操作。 |
|
|
|
以下是使用 Statistic 插件导出的代码行数统计(节选):
| Source File | Total Lines | Source Code Lines | Comment Lines | Blank Lines |
|---|---|---|---|---|
CustomFunction.java | 91 | 82 | 2 | 7 |
CustomFunctionDefinition.java | 45 | 41 | 0 | 4 |
DerivativeFactor.java | 37 | 30 | 0 | 7 |
ExponentialExpression.java | 44 | 37 | 0 | 7 |
ExponentialFunction.java | 57 | 50 | 0 | 7 |
Expression.java | 55 | 47 | 1 | 7 |
Factor.java | 15 | 8 | 2 | 5 |
Lexer.java | 89 | 83 | 0 | 6 |
Main.java | 23 | 22 | 0 | 1 |
MainTest.java | 116 | 100 | 6 | 10 |
Number.java | 38 | 31 | 0 | 7 |
Parser.java | 174 | 161 | 0 | 13 |
PowerFunction.java | 67 | 57 | 2 | 8 |
StandardExpression.java | 210 | 177 | 12 | 21 |
StandardTerm.java | 137 | 109 | 12 | 16 |
Term.java | 66 | 59 | 0 | 7 |
Token.java | 27 | 22 | 0 | 5 |
| Total: | 1291 | 1116 | 37 | 138 |
以下是使用 MetricsReloaded 插件导出的圈复杂度(仅展示超出阈值的方法和类):
| Method | CogC | ev(G) | iv(G) | v(G) |
|---|---|---|---|---|
Lexer.Lexer(String) | 23 | 1 | 18 | 20 |
Parser.parseFactor() | 7 | 6 | 8 | 8 |
StandardExpression.toString(boolean) | 10 | 4 | 5 | 9 |
StandardTerm.toString(boolean) | 17 | 1 | 8 | 13 |
| Class | OCavg | OCmax | WMC |
|---|---|---|---|
Lexer | 4.60 | 18 | 23 |
MainTest | 3.33 | 4 | 10 |
StandardExpression | 2.53 | 8 | 43 |
上表中的方法和类复杂度较高,都是难啃的硬骨头。例如 Lexer 类要将输入分割为多个 token,Parser.parseFactor() 要分辨 7 类因子并调用对应的解析函数,StandardTerm.toString(boolean) 为了缩短输出长度需要分多种情况讨论,等等。为了降低隐患,我在迭代期间对这些函数进行了简化、拆分,并认真检查了逻辑,目前的复杂度虽然偏高,但仍在可控范围内。
我的架构基于 OO 公众号中的教程提供的架构,并在此基础上有所改进。
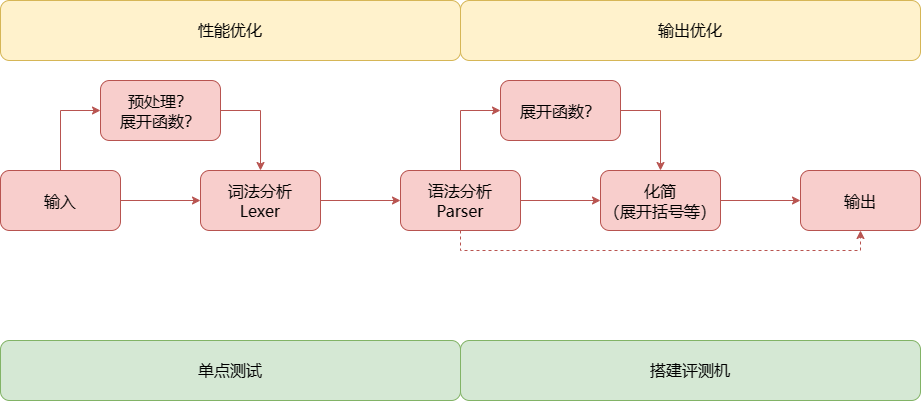
主要分为以下六部分:
Lexer 类将输入字符串分割为多个 token,每个 token 代表一个数、变量、运算符或函数名。Parser 类将一系列 token 解析为抽象语法树。值得一提的是,虽然公众号中已经提供了递归下降法的基本框架,但是同学们的实现还是千差万别。我在第二次研讨课中曾对此进行整理汇报,以下是其主要内容:
严格遵守题目中的形式化表述是个好主意。虽然形式化表述较为复杂且有一点反常识,但是其表述精确且几乎没有歧义,能保证程序的稳定性。除此之外,如果日后要搭建评测机,那么形式化表述会在计算输入代价(Cost)与检验输出合法性等方面大有裨益。
相比之下,有些同学在解析输入时并没有严格遵守形式化表述。他们中的有些人按照自己的理解来完成解析部分,有些人则是对输入进行“预处理”,然后解析预处理后的内容。在预处理过程中,连续多个正负号被合并为一个——虽然这样做能使表达式更加精简,但替换规则会比较复杂。另外,如果在解析简化后的表达式时考虑不够周到,那么可能会产生意想不到的 bug。
这里我要以我的室友为例。我的室友在第一次作业时就没有严格遵守形式化表述,按照自己的理解完成了解析部分,本地测试无误却无法通过中测,于是请我帮忙。我向其程序输入 ---1 后程序报错,而他对此一脸愕然,不敢相信这种输入合乎文法。因此,我非常建议大家严格遵守形式化表述。如果你在这三次迭代中没有严格遵守也没有出 bug,那是因为作业中的语法较为简单,如果语法再复杂些、预处理再繁琐些,那就很容易出 bug。
虽然形式化表述较为复杂,但也是可以优化的。以下是我的优化步骤,可供参考:
| 整理前的形式化表述 | 整理后的形式化表述 |
|---|---|
|
|
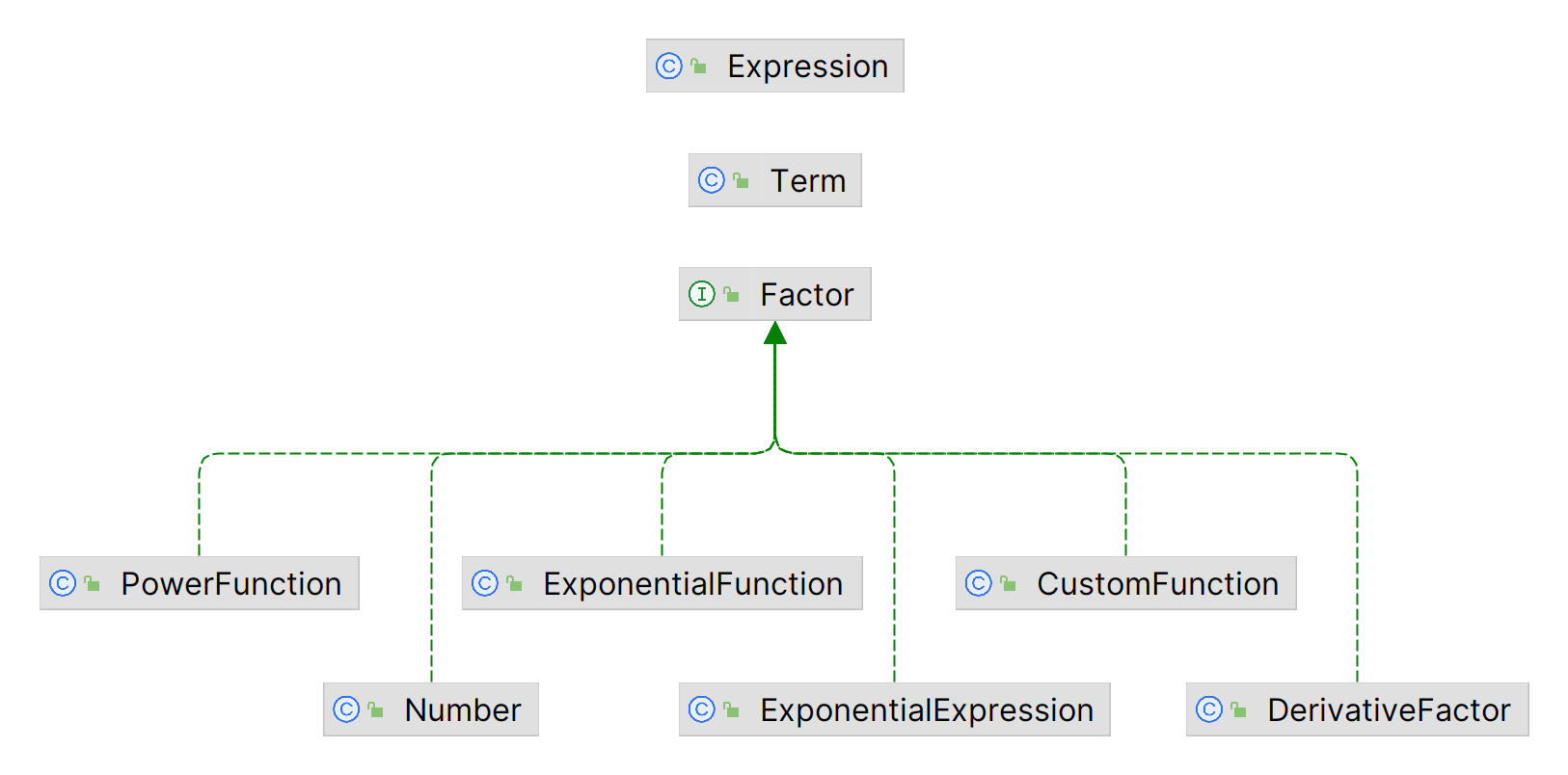
为了完成任务,抽象语法树需要胜任多种多样的功能:展开括号、合并同类项、展开自定义函数、求导、输出优化……为每个类设计一套算法,复杂程度可想而知。为了简化语法树的复杂度,“标准化”的思想应运而生。
在第一次作业中,我们观察展开括号后的表达式,发现表达式和项都遵循以下的普适结构:
$$表达式 = \pm 项 \pm 项 \cdots \pm 项 \ 项 = coe \cdot x^{xexp}$$
第二次作业中加入了指数函数,经过一番计算,我们能重新找到普适结构:
$$表达式 = \pm 项 \pm 项 \cdots \pm 项 \ 项 = coe \cdot x^{xexp} \cdot \exp(eexp)$$
于是,我们引入标准项与标准表达式的概念:
StandardTerm,更多人称之为 Mono)由系数(coe)、$x$ 的指数(xexp)和 $e$ 的指数(eexp)组成。标准项支持取反、加(合并同类项)、乘、求导、比较、转字符串。StandardExpression,更多人称之为 Poly)由多个标准项组成。标准表达式支持取反、加、减、乘、乘方、求导、比较、转字符串。另外,标准表达式用什么容器来储存多个标准项呢?可以用 ArrayList,也可以用 HashMap。前者需要的内存少,后者查询的速度快,两者都有人在用,而且都用得很好。我选择的是 ArrayList,而且我发现 ArrayList 的一大亮点:元素间是有先后顺序的。因此如果我实现了项与项之间的比较方法,那么就可以对表达式进行排序。排序后的表达式便于进行优化,还可以相互比较大小。
hw2 新增展开函数后,大家相处了两种展开函数的方法:一是在预处理阶段,将输入字符串中的函数调用替换为函数值;二是在语法分析之后,将语法树中的函数调用因子替换为函数值对应的语法树。前者的有点事简单直接,转化为已知问题求解。缺点是 替换时需要多次扫描字符串进行解析
,容易出 bug。后者的潜力在于Bonus:对函数定义进行化简,可惜我没有实现这一步,倒是享受到了缺点——复杂嵌套.
我将语法分析与展开函数分成了两步,因此更为复杂.
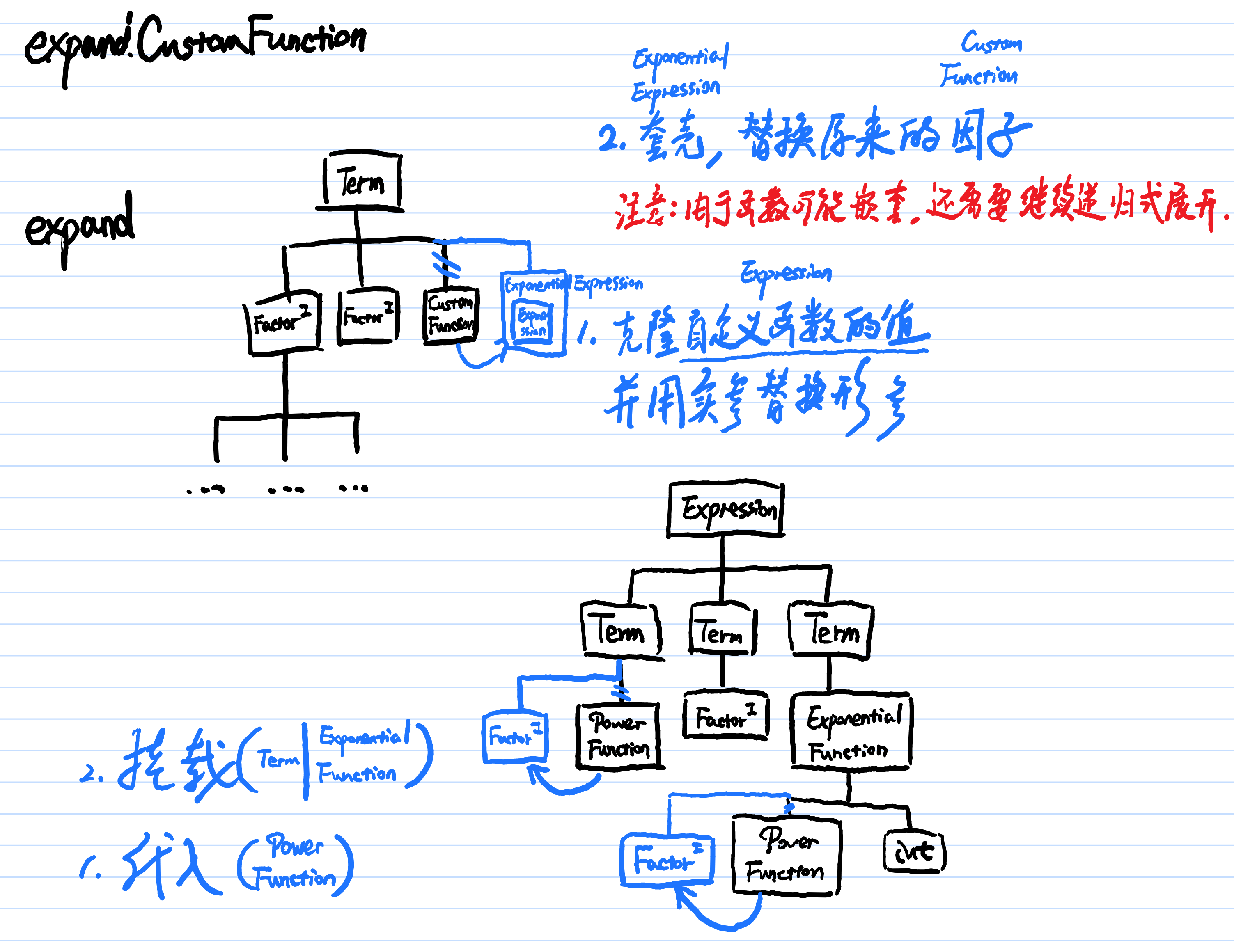
在这里分享一下董佬的做法:董佬并没有为题目中规定的 AST 建立各种各样的类,而只为标准化 AST 建了类。在解析时,他不生成题目中规定的 AST,而直接生成标准化 AST。在展开函数时,他使用参数替换规则解析表达式,方便!!!!(董和军)
本次作业众多与 AST 有关的类。有些人选择使用可变类,进行修改操作时会直接修改原始对象;而有些人则选择不可变类,修改操作创建新的对象,元对象不会变化。两种方法各有优劣,也个有人使用。可变类:时间、空间复杂度相对较小,对象的其他引用会受到影响,需要频繁考虑是否需要深拷贝。不可变类:对象的其他引用不会受到影响,无需为深拷贝而担忧,时间、空间复杂度相对较大。
在为担忧后,我选择了不可变类。虽然不可变类需要频繁创建新的对象并丢弃旧的对象,但我使用了一些手段来降低复杂度:操作过程中使用可变对象存储,对外返回不可变对象。
总体来说,OO 课 多种实现方法 没有标准答案。
本次作业的优化主要分为两部分:性能优化与输出优化。
在性能优化方面,我的优化集中在 StandardTerm 和 StandardExpression 这两个类里:
StandardExpression 是始终有序的。在添加项时,我使用二分查找,插入或合并。
为此,我实现了 StandardTerm 和 StandardExpression 这两个类的 compareTo(...) 方法。StandardTerm 间的比较是先比较 eexp,eexp 相同再比较 xexp,xexp 相同则是同类项——如果还要比较,那就比 coe。而 StandardExpression 间的比较则是从第一项开始依次比较。
操作过程中使用可变对象存储,对外返回不可变对象。
在实现 StandardExpression.pow() 时,我使用了快速幂算法。
除此之外,我尽量减少了创建 Token 类实例的数量,而改用常量代替。
在输出优化方面,我做了两点:一是当结果中有正项时,将正项移到最前面,这样可以省略开头的加号;二是尝试将指数函数中的公因数提取到指数的位置上,如果能使输出长度变短则予以采纳。
除此之外,身边的同学也做了不少优化:有人提取非最大公因数,更短。还有人将指数函数拆成两项并提取最大公因数。虽然这些举措确实可以缩短输出长度,但是能够发挥作用的情况甚少。除此之外,缩短输出长度对性能分甚少,但是需要花费大量的实现,而且有可能出 bug。总体来说,我认为这种过度的优化得不偿失。
至于输出优化,因为和性能分挂钩,所以已经被充分讨论过了:
在 hw1 中,我只实现了第一点;在 hw3 中,我又部分实现了第二点(只比较不提取公因数与提取最大公因数两种情况)。而身边的某些卷王整日为优化输出煞费苦心。在我看来,虽然这些举措确实可以缩短输出长度,但是只能在少数精心构造的数据面前发挥作用。除此之外,缩短输出长度得到的加分甚少,而投入的时间又甚多,不仅容易产生 bug,对程序性能也有影响。总体来说,我认为这种过度的优化实在是得不偿失。
由于我的时间有限,并没有亲自搭建数据生成器与评测机,而是使用了同学的。
在前三次作业中,虽然样例、中测与评测机帮我找出了不少 bug,但仍有一些隐藏的 bug 未被发现。在强测和互测中共发现了 3 个 bug:
hw2 中,指数过大时会溢出。这是因为我没有预料到指数会那么大,所以用 int 储存。这个 bug 可以通过认真研究题目要求来避免。在“数据限制”一节中提到输入表达式最长为 200 个字符。综合种种限制,以下表达式的展开结果中,指数会超过 int 乃至 long:
(((((((((((((((((((((((((((((((((((((((((((((((((x^8)^8)^8)^8)^8)^8)^8)^8)^8)^8)^8)^8)^8)^8)^8)^8)^8)^8)^8)^8)^8)^8)^8)^8)^8)^8)^8)^8)^8)^8)^8)^8)^8)^8)^8)^8)^8)^8)^8)^8)^8)^8)^8)^8)^8)^8)^8)^8)^8)^8
最终我的解决方法是用 BigInteger 储存指数。
hw2 中,指数函数中的自定义函数调用未能嵌套展开。这是因为项和指数函数中都能包含因子,当自定义函数调用展开后,负责嵌套展开的代码写在了 Term(项)里,而没有写在 ExponentialFunction(指数函数)里。最终我将嵌套展开的代码移动到了 CustomFunction(自定义函数调用)里。
hw3 中,StandardTerm.eexp 中只有一项时,提取的指数为负数。这是因为提取指数的计算方法为:先取第一项的系数,再与后面每一项求最大公因数。虽然求最大公因数的方法返回的是正数,但是当只有一项时,程序会直接返回第一项的系数,而不会经过求最大公因数的函数。解决方法是取第一项的系数时要取绝对值。
以上三个问题都是由于考虑不周而产生的。一方面,我应该在编程前充分考虑每一种情况;另一方面,自己搭建评测机的重要性日益凸显。
这是 OO 正课的第一单元。在本单元中,我学会了使用递归下降法解析并化简表达式。同时,经过课上的学习与课下的实践,我对面向对象有了更多了解。
虽然能够按时提交作业、顺利完成任务已经很棒了,但美中不足的是,由于时间不足,我没能搭建自己的评测机。希望我在下个单元能抽出足够的时间,实现自己生成数据、自己完成任务、自己检验答案的闭环。



