


301
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享本单元的主要学习任务是基于JML规格的程序设计,我们需要理解体会规格语言对于程序开发带来的帮助。除此之外,我们还需要在规格约束的基础上,进一步优化实现方法,减轻时间复杂度,体会规格和实现的区别。
在以往的作业中,因为每一个函数的界限不明确,因此我们通常选择黑盒测试,黑盒测试构造简单,但是因为是从整体程序角度进行测试,对单个函数测试的效果较差
相对于在往次作业常用的黑盒测试,在有规格的情况下,使用白盒测试能够强化测试效果,因为规格定义的方法功能十分明确,可以针对规格中的每一条进行白盒测试,而白盒测试是针对方法进行测试,能够更完善的测试每一个通路
除了方法以外,还要注意各位置的变量约束,例如变量是否发生改变,或者变量内部数据是否改变
通过Junit进行每一个方法的独立测试,在测试之前需要先设置好测试数据,数据可以通过合理的方式自动化构造,但是要注意覆盖面避免出现重复上千次的无效测试
测试要考虑到边界条件,例如在值为空,或者接近满的情况下如何应对
单元测试:
功能测试:
集成测试:
压力测试:
回归测试:
以sendMessage为例,数据生成时要充分覆盖到规格的每一个功能

上面的Type主要分为0和1两种,代表消息的类型不同,在测试时我们可以假设调用者的预先准备符合requires要求,因此不在其中的数据暂且忽略,以下只分析type == 0的情况
除此之外的要求有,containsMessage和isLinked两个可能报错的条件,因此可以针对这两句,构造少量的数据检验报错是否正常

在此处,有对于RedEnvelope类型信息的特判,因此可以构造部分RedEnvelope类型信息进行测试

这里还有关于非RedEnvelope类型的特判,因此所有的类型都需要考虑,并且加入到生成的信息种类中
例如:Message,RedEnvelopeMessage,NoticeMessage,EmojiMessage
后续关于EmojiMessage的特判也相同

此处提出,接收者的messages数组可能发生变化,因此要考虑数组为空和数组有较多内容的边界情况
除此之外,尽管我们可以通过随机生成得到大量测试点,并且也有得到边界值的可能性,但是概率太低,在有限的测试次数下难以针对边界值进行测试。
所以关于数据生成时,应当采取大规模随机测试点结合手动构造的极端测试点的方法,因为规格的存在,所有潜在的边界条件都有明确的标明,可以减轻我们构造测试点的工作量
Junit测试中使用assertTrue(),assertEquals()之类断言,检验程序运行结果和预期相同
而规格已经为我们定义了ensures之类断言,我们只需要按照其规定的条件去进行判断即可
但除此之外,也不要忘记not_assigned, assignable, invariant, safe之类,对于数据的保护
以下针对JML规格中可能出现的几种修饰,列出对应ensures的解决方案
\ensures : 直接断言
assertTrue(expr)
\result :
T result = func()
assertEquals(func(), expr)
\old(expr) :
oldExpr = get().clone()
func()
Expr = get()
要注意\old只修饰括号内元素的引用,例如\old(hashMap).get(0)和\old(hashMap.get(0))是不同的,前者表示运行前hashMap地址在运行后get(0),而后者表示运行前hashMap地址在运行前get(0)
\not_assigned 和 \not_modified类似,前者表示被赋值,后者表示被修改
\forall var; condition; expr : 可以用for循环与断言配合解决
for(var = condition_min; condition; var++) {
assertTrue(expr)
}
\exists var; condition; expr : 可以用for循环与flag配合解决
flag = false
for(var = condition_min; condition; var++) {
if expr then flag = true
}
assertTrue(flag)
\sum var; condition; expr : 可以用for循环解决
sum = 0
for(var = condition_min; condition; var++) {
sum += expr
}
\product var; condition; expr : 可以用for循环解决
sum = 1
for(var = condition_min; condition; var++) {
sum *= expr;
}
\max, \min var; condition; expr : 可以用for循环和if解决
ans = 0/MAX
for(var = condition_min; condition; var++) {
if expr >/< ans then ans = expr
}
\num_of var; condition; expr : 可以用for循环和if解决,可以替换为\sum var; condition && expr; 1
sum = 0
for(var = condition_min; condition; var++) {
if expr then sum++
}
A <==> B : A等于B,和==相似,但是优先级更低,可以用于判断是否同时相等
(A) == (B)
A <=!=> : 同理
(A) != (B)
A ==> B : 推导关系,可以用if和断言解决
if A then assertTrue(B)
在A不满足时无需考虑

对于此类直接ensures的断言,可以直接使用assertTrue(!containsMessage(id))

此处出现了old修饰
oldMessage = getMessage(id)
oldSocialValue = oldMessage.getPerson1().getSocialValue()
sendMessage(id)
oldMessage.getPerson1().getSocialValue() == oldSocialValue + oldMessage.getSocialValue()

此处出现了==>符号,可以使用if (oldMessage instanceof RedEnvelopeMessage) { assertTrue(Expr) }
之类的结构,在不满足条件时,不需要断言


此处出现的not_assigned和invariant都需要保证数据不变,例如assertEqual(old, new)

此处出现的exists修饰,可以使用for循环嵌套flag的结构,即
flag = false
for (int I = 0; I < emojiIdList.length; i++) {
if (emojiIdList[i] == oldMessage.getEmojiId &&
emojiHeatList[i] == oldEmojiHeatList[i] + 1) {
flag = true
}
}
assertTrue(flag)

这里的forall修饰,直接使用for循环的结构即可验证
for(int i = 0; i < oldMessages.size(); i++) {
assertEquals(oldMessage.getPerson2().getMessages.get(i+1), oldMessages.get(i))
}
本单元作业中的Network类,本质上是由多个Person组成的一个图,在三次开发中,需要查询图中内容的函数总共以下几种:
以下介绍这几个函数的实现方式和优化方式
在具体实现中,我选择通过维护的方式,因为当时还不了解并查集,因此用了其他的方式,而具体需要维护的内容包括各个点所在的联通分支,以及三元环
public void addPerson(Person person) throws EqualPersonIdException {
int id = person.getId();
if (!containsPerson(id)) {
Map map = new Map(person);
persons.put(id, person);
maps.put(person, map);
} else { throw new MyEqualPersonIdException(id); }
}
此处的addPerson,向图中增加了一个点,但因为与其他点不相连,因此也是新增了一个联通分支,即person及其对应的分支map,这个函数复杂度约为O(1)
public void addRelation(int id1, int id2, int value) throws
PersonIdNotFoundException, EqualRelationException {
Person person1 = getPerson(id1);
Person person2 = getPerson(id2);
if (person1 != null && person2 != null && !getPerson(id1).isLinked(getPerson(id2))) {
((MyPerson) person1).link(person2, value);
((MyPerson) person2).link(person1, value);
maps.get(person1).newLink();
((MyPerson) person1).updateValue(person2);
((MyPerson) person2).updateValue(person1);
if (!maps.get(person1).equals(maps.get(person2))) {
Map map1 = maps.get(person1);
Map map2 = maps.get(person2);
map1.putAll(map2);
for (Person person : map2.keySet()) { maps.replace(person, map1); }
}
for (Person person : ((MyPerson) person1).getLink()) {
if (person2.isLinked(person) && !person.equals(person2)) {
Triple triple = new Triple(person1, person2, person);
tripleMap.put(triple, true);
}
}
} else {
if (!containsPerson(id1)) { throw new MyPersonIdNotFoundException(id1); }
else if (!containsPerson(id2)) { throw new MyPersonIdNotFoundException(id2); }
else { throw new MyEqualRelationException(id1, id2); }
}
}
此处增加了一个边,如果两个点本就在同一个联通分支,那么加边后仍不变,否则两个图会被添加到同一个分支中,因此需要将其中的一部分全部替换为另一个点的分支图
除此之外,因为增加了value,因此子图路径长度之和也会发生改变,需要进行维护,以及三元边,通过遍历两个点共同所有的点,即可找到对应新增的三元边,这个函数的复杂度约为O(n)
public void modifyRelation(int id1, int id2, int value) throws
PersonIdNotFoundException, EqualPersonIdException, RelationNotFoundException {
Person person1 = getPerson(id1);
Person person2 = getPerson(id2);
if (person1 != null && person2 != null && id1 != id2 && person1.isLinked(person2)) {
if (person1.queryValue(person2) + value > 0) {
((MyPerson) person1).modifyValue(person2, value);
((MyPerson) person2).modifyValue(person1, value);
((MyPerson) person1).updateValue(person2);
((MyPerson) person2).updateValue(person1);
} else {
((MyPerson) person1).updateValue(person2);
((MyPerson) person2).updateValue(person1);
((MyPerson) person1).removeLink(person2);
((MyPerson) person2).removeLink(person1);
maps.get(person1).removeLink();
if (!maps.get(person1).fullLinked()) {
if (!preMap.containsKey(person1)) { preMap.put(person1, true); }
if (!preMap.containsKey(person2)) { preMap.put(person2, true); }
if (!maps.get(person1).isDirty()) { maps.get(person1).setDirty(); }
dirty = true;
}
for (Person person : ((MyPerson) person1).getLink()) {
if (person2.isLinked(person) && !person.equals(person2)) {
Triple triple = new Triple(person1, person2, person);
tripleMap.remove(triple);
}
}
}
} else {
if (person1 == null) { throw new MyPersonIdNotFoundException(id1); }
else if (person2 == null) { throw new MyPersonIdNotFoundException(id2); }
else if (id1 == id2) { throw new MyEqualPersonIdException(id1); }
else { throw new MyRelationNotFoundException(id1, id2); }
}
}
这个函数可能会导致删边,因此这也是维护最复杂的函数,首先是修改长度时,可能导致queryValueSum的值发生改变,需要进行维护。而删边之后可能导致联通分支断开,也可能导致queryValueSum值发生改变,甚至离开Tag,以及三元环断开,因此要进行多处判断。关于删边导致联通分支断开,可能需要重新建图,复杂度较高,因此在此设置脏位,将所有的变化保存下来,直到查询时再重新建图。除此之外对于值的修改和三元环的修改可以当场处理。因此此处复杂度约为O(n)
public int queryValue(int id1, int id2) throws
PersonIdNotFoundException, RelationNotFoundException {
Person person1 = getPerson(id1);
Person person2 = getPerson(id2);
if (person1 != null && person2 != null && person1.isLinked(person2)) {
return person1.queryValue(person2);
} else if (person1 == null) { throw new MyPersonIdNotFoundException(id1); }
else if (person2 == null) { throw new MyPersonIdNotFoundException(id2); }
else { throw new MyRelationNotFoundException(id1, id2); }
}
求边长,直接从点找到另一个点即可,复杂度O(1)
public boolean isCircle(int id1, int id2) throws PersonIdNotFoundException {
Person person1 = getPerson(id1);
Person person2 = getPerson(id2);
if (person1 != null && person2 != null) {
if (dirty) {
dirty = false;
updateMap();
}
return maps.get(person1).contains(person2);
} else if (person1 == null) { throw new MyPersonIdNotFoundException(id1); }
else { throw new MyPersonIdNotFoundException(id2); }
}
查询是否联通,在有脏位情况下,需要重新建图,通过bfs方式进行,因此复杂度为O(n^2),而如果没有脏位,则可以直接查询,复杂度为O(1)
public int queryBlockSum() {
if (dirty) {
dirty = false;
updateMap();
}
int sum = 0;
HashSet<Map> temp = new HashSet<>();
for (Map map : maps.values()) {
if (!temp.contains(map)) {
sum++;
temp.add(map);
}
}
return sum;
}
同理,如果脏位,则复杂度O(n^2),否则直接遍历点寻找不同的图,复杂度O(n)
public int queryTripleSum() { return tripleMap.size(); }
此处三元环受到维护,因此直接查询即可,复杂度O(1)
public void addTag(int personId, Tag tag) throws
PersonIdNotFoundException, EqualTagIdException {
if (containsPerson(personId) && !getPerson(personId).containsTag(tag.getId())) {
getPerson(personId).addTag(tag); }
else if (!containsPerson(personId)) { throw new MyPersonIdNotFoundException(personId); }
else if (getPerson(personId).containsTag(tag.getId())) {
throw new MyEqualTagIdException(tag.getId()); }
}
添加子图,直接添加即可,复杂度O(1)
public void addPersonToTag(int personId1, int personId2, int tagId) throws
PersonIdNotFoundException, RelationNotFoundException,
TagIdNotFoundException, EqualPersonIdException {
if (containsPerson(personId1) && containsPerson(personId2) &&
personId1 != personId2 && getPerson(personId2).isLinked(getPerson(personId1)) &&
getPerson(personId2).containsTag(tagId) &&
!getPerson(personId2).getTag(tagId).hasPerson(getPerson(personId1)) &&
getPerson(personId2).getTag(tagId).getSize() <= 1111) {
getPerson(personId2).getTag(tagId).addPerson(getPerson(personId1));
} else if (!containsPerson(personId1)) {
throw new MyPersonIdNotFoundException(personId1);
} else if (!containsPerson(personId2)) {
throw new MyPersonIdNotFoundException(personId2);
} else if (personId1 == personId2) {
throw new MyEqualPersonIdException(personId1);
} else if (!getPerson(personId2).isLinked(getPerson(personId1))) {
throw new MyRelationNotFoundException(personId1, personId2);
} else if (!getPerson(personId2).containsTag(tagId)) {
throw new MyTagIdNotFoundException(tagId);
} else if (getPerson(personId2).getTag(tagId).hasPerson(getPerson(personId1))) {
throw new MyEqualPersonIdException(personId1);
}
}
此处将点加入子图,在加入后,子图需要更新queryValueSum,因此复杂度为O(n)
public int queryTagValueSum(int personId, int tagId) throws
PersonIdNotFoundException, TagIdNotFoundException {
if (containsPerson(personId) && getPerson(personId).containsTag(tagId)) {
return getPerson(personId).getTag(tagId).getValueSum();
} else if (!containsPerson(personId)) { throw new MyPersonIdNotFoundException(personId); }
else { throw new MyTagIdNotFoundException(tagId); }
}
queryValueSum受到维护,因此复杂度为O(1)
public void delPersonFromTag(int personId1, int personId2, int tagId) throws
PersonIdNotFoundException, TagIdNotFoundException {
if (containsPerson(personId1) && containsPerson(personId2) &&
getPerson(personId2).containsTag(tagId) &&
getPerson(personId2).getTag(tagId).hasPerson(getPerson(personId1))) {
getPerson(personId2).getTag(tagId).delPerson(getPerson(personId1));
} else if (!containsPerson(personId1)) {
throw new MyPersonIdNotFoundException(personId1);
} else if (!containsPerson(personId2)) {
throw new MyPersonIdNotFoundException(personId2);
} else if (!getPerson(personId2).containsTag(tagId)) {
throw new MyTagIdNotFoundException(tagId); }
else { throw new MyPersonIdNotFoundException(personId1); }
}
从子图删除点,需要更新queryValueSum,因此复杂度O(n)
public void delTag(int personId, int tagId) throws
PersonIdNotFoundException, TagIdNotFoundException {
if (containsPerson(personId) && getPerson(personId).containsTag(tagId)) {
getPerson(personId).delTag(tagId);
} else if (!containsPerson(personId)) {
throw new MyPersonIdNotFoundException(personId);
} else { throw new MyTagIdNotFoundException(tagId); }
}
删除子图,复杂度O(1)
public int queryShortestPath(int id1, int id2) throws
PersonIdNotFoundException, PathNotFoundException {
if (containsPerson(id1) && containsPerson(id2)) {
int path = dijkstra(getPerson(id1), getPerson(id2));
if (path >= 0) { return path; }
else { throw new MyPathNotFoundException(id1, id2); } }
else if (containsPerson(id1)) { throw new MyPersonIdNotFoundException(id2); }
else { throw new MyPersonIdNotFoundException(id1); }
}
求无权值的最短路径,我这里选择的方式是dijkstra算法,复杂度约为O((V+E)logV)
总而言之,因为删除边的可能会导致重新建图,时间复杂度很难降到O(n^2)以下,所以其他算法复杂度在O(n^2)以下的不影响压力测试的结果。而主要消耗时间的在于MR函数的删边操作,所以仅对该操作进行脏位设置,并且通过图论全联通的(n-1)(n-2)/2判断其联通可能,减少脏位的设置情况,尽可能简化运算。
本次实验中,除了实时维护的操作以外,脏位也是优化时间复杂度的一个有效工具
由此可以看出,例如三元环函数,规格实现为三个for循环嵌套,这样的复杂度十分高,导致超时。而我们选择在运行过程中维护,复杂度最高的操作是全部为mr操作,假设共n个点m个数据,则复杂度一共为O(nm),而如果使用for循环嵌套,则复杂度最高为全部为查询函数qts,复杂度O(mn^3),差距显著,所以我们使用了其他的设计方式,而保证函数规格的功能正常实现,体现了规格与实现分离
通过十数周的OO学习,我们已经逐渐理解层次化设计对于我们程序开发的帮助,但仍有缺点需要解决
我们在第三单元学习了规格设计,这种方法使得我们能够将程序分工合同化,明确层次之间的分界线
规格主要作用是,描述软件架构,为开发团队提供了对所需构建的软件系统的清晰理解和一致的认识
无规格约束:

规格约束:
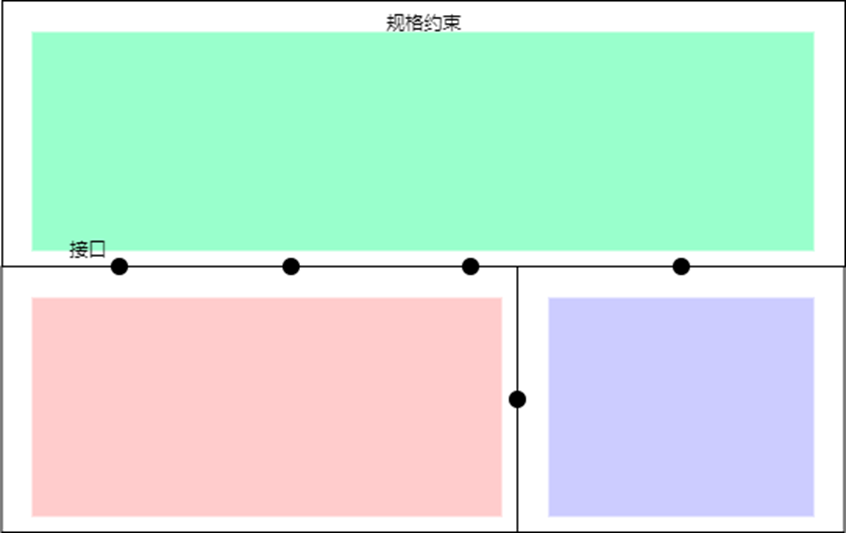
规格为软件架构划清了界限,规格通过对接口函数提出明确的功能要求,分配调用者和被调用者的权限要求,对层次化设计做出了功能和性能上的补全
接口定义:
•给出详细的函数功能要求,明确准备工作,减轻学习成本
•不需要完全阅读函数实现方式,安全的按照规格要求调用该函数
协作成本:
•因为有了明确的责任分摊,无需顾虑对方的特殊需求,只满足规格要求即可。
•程序出现问题时,可以分清问题责任
标准化:
•整体程序实现符合规格定义的标准,使得整体程序遵循一种模式
程序测试:
•有了明确的函数职责要求后,可以针对规格直接设计单一函数的单元测试
•通过白箱测试的方法保证函数符合规格要求
规格语言为我们开发程序提供了极大地便利,无论在开发,拓展,协作或是测试等等方面,都得到一定的优化。
因此尽管在最初构造规格时可能需要一些功夫,但总的来说,磨刀不误砍柴工



