


301
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享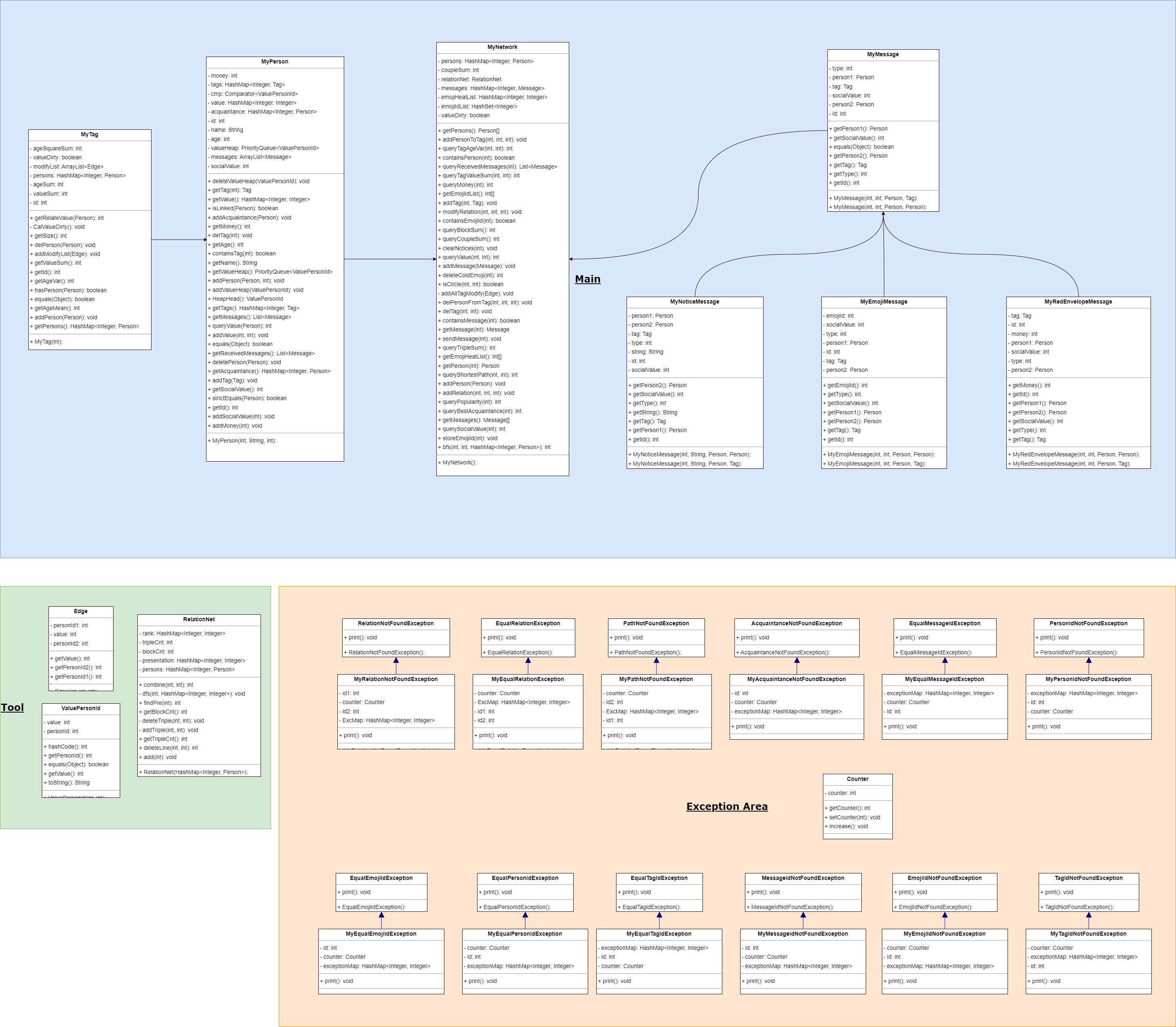
第一次作业相对比较简单,主要是根据JML进行编写,熟悉JML的使用过程,因此在这次作业主要是把精力放在优化性能上。
并查集的构建
在这次作业中有一个指令isCircle,作用是查询两个person之间是否能通过若干个中间的person媒介进行连接,使得两者能做到 间接性的 伙伴关系。
这个指令的JML给出的是循环遍历,但是这种的时间复杂度是O(n^2 ),很容易出现TLE,因此有必要进行优化。
但要怎么优化呢?我们考虑到,这个其实本质上就是查询分组问题:只要两个人有联系,我们就把他们放在同一个组里面就好,这也就是并查集。
并查集的具体构建在网上都有,这里就不再赘述,主要思路就是使用一个数组标识每个节点的所在组别,在加入节点或者连接边的时候进行修正。
并查集的优化
当查询一遍结果之后,就将该节点的标识改成这一组别的标识。
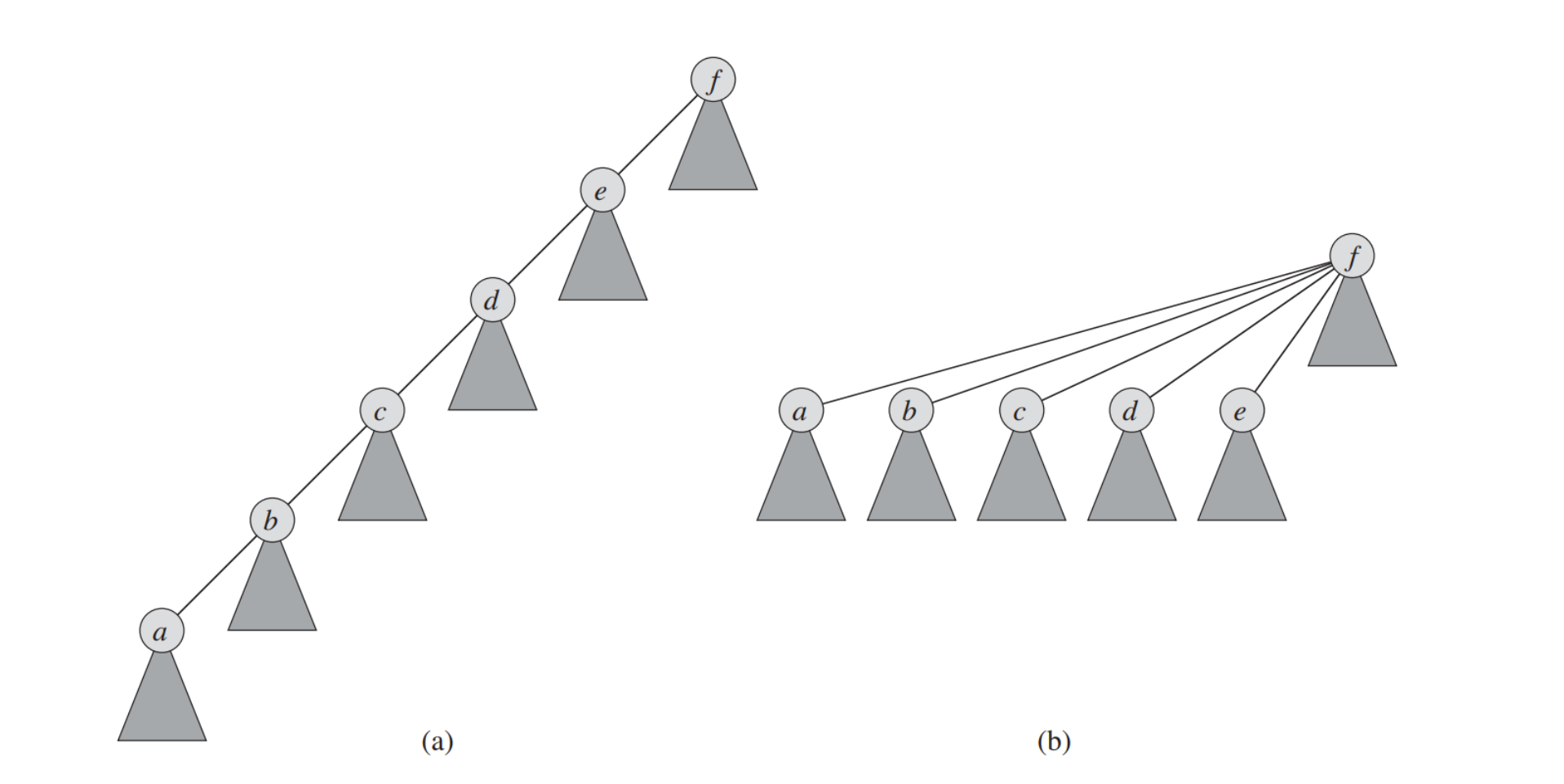
按秩合并
合并的时候采取将小秩的组别插入到大秩的组别种,减小树的高度。
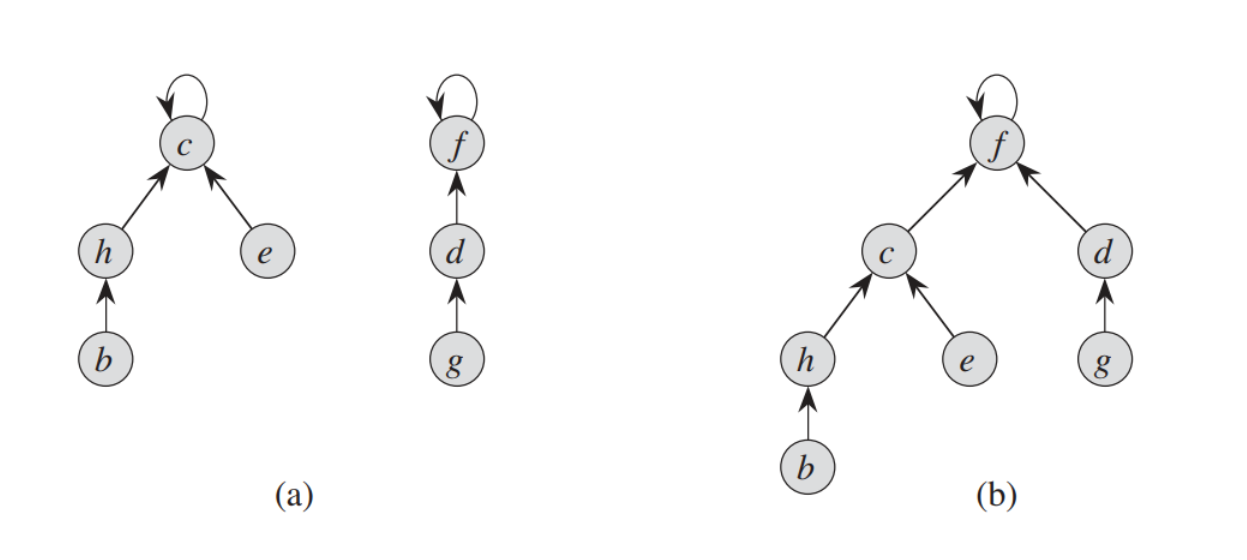
维护式修改
在本次作业种出现了queryTripleSum这个函数,如果单纯按照给出的JML是一定会爆的,因此我们选择在每次增删关系的时候,对其进行维护修改值。等到需要查询这个值的时候,直接将这个数据读取出来即可。虽然这样做在普通的指令上可能会有一些损失,但在总体上是一个正收益。
bug & hack
本次作业中并没有出现bug,也没有成功hack别人
第二次作业中,对性能优化的地方显著增加,下面一一描述。
计算类函数的优化
以getAgeMean()为例,我们可以设置一个ageSum来表示Tag中所有人年龄总和,每次向Tag中加人时维护ageSum,在getAgeMean直接返回ageSum/people.size()即可。还有一点要注意的就是方差计算的时候,因为我们的除法是向下取整,因此** 数量 * 平均数 != 总数 **
queryBestAcquaintance
这个指令的作用是查询一个人的最好的伙伴,最朴素的方法非常简单,遍历就可以,复杂度是O(n),看起来还是可以接受的(实际上好像确实可以接受),但是我们是否有更好的方法对其进行优化呢? 我们注意到,这个函数其实也是一种排序函数:把这个人的所有朋友的亲密度进行排序,读出最大的那个人的id。因此我们想到有一种排序算法的时间可以做到O(logn):堆排序,因此我们可以考虑这里用堆进行实现。
在Java中,堆的实现一般有两种方案:Treemap 或者 PriorityQueue,我是使用后者。因为后者的内部实现是一个完全二叉树,因此能提高效率。也就是每个Person都储存一个堆表示亲密度排序,在修改关系或者增删人的时候进行更改,读取的时候直接读取即可。
//MyPerson.java
private final PriorityQueue<ValuePersonId> valueHeap = new PriorityQueue<>(cmp);
public void addValueHeap(ValuePersonId element) {
this.valueHeap.add(element);
}
public void deleteValueHeap(ValuePersonId element) {
this.valueHeap.remove(element);
} //必须保证这个元素之前有过
public ValuePersonId HeapHead() {
return this.valueHeap.peek();
}
Queue<Integer> forwardQueue = new LinkedList<>();
Queue<Integer> backwardQueue = new LinkedList<>();
forwardQueue.add(id1);
backwardQueue.add(id2);
Set<Integer> forwardVisited = new HashSet<>();
Set<Integer> backwardVisited = new HashSet<>();
forwardVisited.add(id1);
backwardVisited.add(id2);
boolean found = false;
while (!forwardQueue.isEmpty() && !backwardQueue.isEmpty() && !found) {
int forwardSize = forwardQueue.size();
for (int i = 0; i < forwardSize; i++) {
int current = forwardQueue.poll();
if (backwardVisited.contains(current)) {
found = true;
}
MyPerson currentPerson = (MyPerson) getPerson(current);
for (int key : currentPerson.getAcquaintance().keySet()) {
if (!forwardVisited.contains(key)) {
forwardVisited.add(key);
forwardQueue.add(key);
}
}
}
bug & hack
本次作业中出现了两个bug:一个是cmp函数中忽略了int-int可能超出int范围的问题(这个好痛啊,一下三个点没了),另一个是qtvs下因为时间复杂度太高而出现的问题,解决方法是在可能会修改这个值的时候进行一个标记,每次读取的时候如果标记是false就读取上一次的值,否则重新计算。
hack除了针对上述两个问题外,还有一个就是qcs的TLE问题。
本次作业没有特别多优化的点,大部分按照JML写就行。
bug & hack
呜呜呜这次是OO最大的滑铁卢哈哈哈哈,因为一个笔误(addMoney写成addSocialValue),直接强测寄掉了。
互测的时候发现的问题主要是如果tag_size==0的时候发红包的特判。
黑箱测试,也称为功能测试或数据驱动测试,是一种软件测试方法,其中测试人员无需关心软件内部的结构、逻辑或代码。测试人员仅根据软件的需求规格说明或功能说明来设计测试用例,检查软件的功能是否符合需求。在黑箱测试中,测试人员通常将软件视为一个无法打开的黑箱子,仅通过输入和输出来判断软件的正确性。
白箱测试,也称为结构测试、透明盒测试或开放盒测试,是一种软件测试方法,其中测试人员可以访问软件的内部逻辑、结构、路径和代码。白箱测试通常涉及到单元测试、集成测试和系统测试。在白箱测试中,测试人员会根据程序的内部结构、逻辑和代码来设计测试用例,以检查程序中的错误。
单元测试是最小单位的测试,通常针对软件中的最小可测试单元(如函数、方法或类)进行。单元测试的目标是确保代码的各个单元都能按照预期工作。单元测试通常由开发人员编写和执行,以确保代码的质量。
功能测试是一种黑箱测试方法,旨在测试软件是否按照需求规格说明正确实现功能。测试人员会根据软件的功能需求设计测试用例,并检查软件的输出是否符合预期。功能测试可以确保软件的功能正确性。
集成测试是一种在单元测试之后进行的测试阶段,用于检查不同的软件单元在集成到一起时是否能正常工作。在集成测试中,测试人员会检查单元之间的接口和交互,以确保它们能够协同工作并满足整体需求。
压力测试是一种非功能性测试方法,旨在评估软件在异常或极端条件下的性能。在压力测试中,测试人员会模拟大量的用户请求、数据输入或其他资源消耗,以检查软件在高负载下的性能表现。压力测试可以帮助发现软件的性能瓶颈和潜在问题。
回归测试是一种在软件修改或更新后重新执行之前已经通过测试的测试用例的过程。回归测试的目的是确保修改或更新没有引入新的错误,并且软件仍然符合之前的测试标准。回归测试可以确保软件的稳定性和一致性。
本单元的数据构造比较多样化,我倾向于对于每个函数的各个方法进行逐一的测试。但是在测试阶段也是主要运用了别人的评测机,在自己的测试仅仅进行了压力测试(卡TLE)
本单元的Junit测试与之前在先导课程的时候的测试有很大的不同,先导课的测试主要是简单的对于某个函数的单独的测试,但是这里的测试的规模就比较大了,是一个完整的集成的测试。一般来说,有两种流派:手捏和随机。
先说一下这两者的优缺点。手捏优点很明显,这是一个确定的数据,那么在测试的时候只需要你这一个数据点足够强就可以稳过,并且在判定assert的时候可以直接给出一个确定的值,就不用搁那算半天了()。随机的优点是...覆盖面更全...可以锻炼你写代码的能力...好像就没了哈哈哈,但写完随机的真的感觉跟写一个小评测机差不多。
下面给出一个简易的随机化Junit测试的基本框架:
@RunWith(Parameterized.class)
public class XXXTest{
private ....
public ...
@Parameters
public static Collection prepareData(){ //创建数据
int testNum = 88;
Object[][] object = new Object[testNum][];
......
object[i] = new Object[] {...};
return Arrays.asList(object);
}
@Test
public void queryCoupleSumTest(){
//your test
}
}
对于和JML规格的结合,除了普通的ensure之外,还需要重点关注pure````、``assignable等不能修改的指令。一般选择是新建两个数据集,数据完全一样除了地址,接下来对两个数据集采取相同的操作手段,最后对比不需要更改的地方即可。
对于Junit对规格实现的准确程度,我觉得还是非常不错的。因为测试方法中对于每一个ensure都是分开检查的,非常具有全面性和覆盖性。
本单元主要是根据JML进行代码的撰写,如果不考虑性能的话,可以说基本是不需要懂太多脑子进行架构的,只需要把JML翻译过来即可。JML在实际操作中大概只会在那些核心尖端领域或者是非常重要的代码块进行黑箱描述,保证撰写者和使用者所期望的实现是一样的,但是在平常的简易的程序中JML其实并不会发挥很大的作用,就像平常写作业的时候的一个函数,总没有谁会在旁边写一大段JML吧。
但是因为本人的粗心大意,在一个简单的单元丢得分比前面两个单元丢的分加起来还多,这也从侧面反映出JML的精确性,看的时候需要很仔细。
同时,规格和实现分开也是JML的一大特点,这样就更便于读者对这个函数进行黑箱包装,只关心其前置条件、结果特点、副作用等,无需关注内部具体是如何实现的,也构成了函数的最最最本质的作用(封装)。



