


301
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享黑箱测试:要求测试人员站在用户的角度进行测试,给出数据输入,只要代码的输出合理即可,不需要关注内部的细节与实现。这种方法通常用于功能测试与用户角度的测试。公测与互测用的就是黑盒测试。
白箱测试:需要测试人员去检查代码内部的结构有与逻辑,通过代码分析,来保证自己的数据覆盖全部情况,无逻辑错误。主要用于单元测试与集成测试,我们针对jml语言写的Junit测试也是白箱测试的思想。
单元测试:是针对代码中的最小单元进行测试,通常是函数或方法,这种测试是基本单元的测试,防止在函数实现时产生问题;
功能测试:是验证系统功能是否符合需求和规格,这种测试可以帮助我们检查是否会遗漏功能;
集成测试:是验证多个模块之间的交互和集成是否正常,这个测试是在单元测试的基础上,保证接口之间连接等没有错误;
压力测试:是测试系统在负载情况下的性能表现,强测中很多对于性能的测试,可以让我们发现可优化的潜力;
回归测试:是在修改代码或添加新功能后,重新运行之前的测试用例,确保修改不会影响原有功能的正常运行,在我们修复bug后,要保证原有的正确功能不出问题。
在写Junit测试时,主要用了随机生成的策略。还可以与特殊图结合起来。
首先实现了异常类,在Count类中用静态变量和静态数组管理异常类出现的次数。并用单例模式实现count的引用。
public class Counter {
private static HashMap<Integer, Integer> epiCount;
private static HashMap<Integer, Integer> erCount;
private static HashMap<Integer, Integer> pinfCount;
//……
private static int epi = 0;
private static int er = 0;
private static int pinf = 0;
//……
private Counter() {
//……
}
private static Counter counter = new Counter();
public static Counter getInstance() {
return counter;
}
//……
}
然后在异常类的print()方法中实现次数的增加。这个单元的异常类都可以用这个方法实现。
public class MyEqualPersonIdException extends EqualPersonIdException {
private int id;
public MyEqualPersonIdException(int id) {
this.id = id;
}
public void print() {
Counter.getInstance().addException("epi");
Counter.getInstance().addException(id, "epi");
System.out.println("epi-" + Counter.getInstance().getException("epi")
+ ", " + id + "-" + Counter.getInstance().getIdException(id, "epi"));
}
}
然后是network中persons容器的选择,考虑到每个person都有一个独一无二的id,我选择了以id为键的Hashmap。同理,Person中acquaintance和values容器也选用以id为键的Hashmap。
第九次作业涉及到图模型的方法主要有isCircle()(判断两个person是否可达),queryBlockSum(关系图的连通分支),queryTripleSum(关系图中三角关系的数量)。对此,我新建了一个类Map专门管理整个network关系图,并利用了并查集算法。并查集是一种树型的数据结构,用于处理一些不相交集的合并及查询问题。有一个联合-查找算法定义了两个用于此数据结构的操作:
isCircle())map中的数据结构主要有:
public class Map {
private HashMap<Integer, Integer> parent = new HashMap<>(); //存储节点的父节点,父节点的parent是其本身
private HashMap<Integer, Integer> rank = new HashMap<>(); //存储每个节点所在树状图结构的层数(只有根节点时为0)
private HashMap<Integer, HashSet<Integer>> graph = new HashMap<>(); //存储每个节点和其邻居节点(邻居节点不包括节点本身)
private int blockCnt;
private int tripleCnt; //动态管理blockCnt和tripleCnt
……
}
find()方法体现了路径压缩的思想,在每次寻找节点所在树的根节点时,都将沿途的节点的父节点设置成根节点,这样可以将整个树的层数压缩至2,减小时间复杂度。而merge()方法则体现了按秩合并的思想,合并时,总是将秩较低的树的根指向秩较高的树的根。
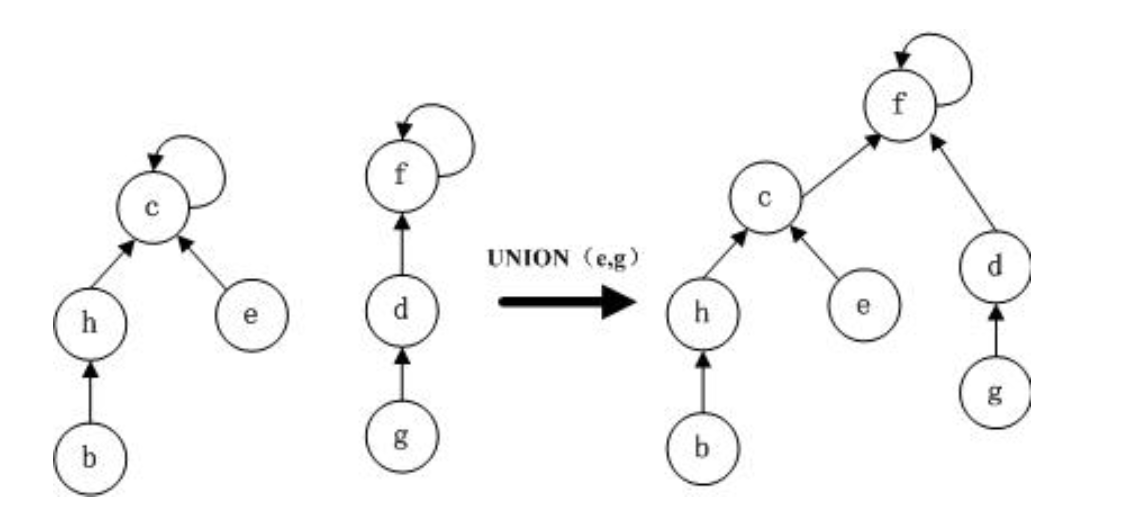
public class Map {
//……
public void add(int id) {
if (!parent.containsKey(id)) {
blockCnt++;
parent.put(id, id);
rank.put(id, 0);
}
}
public int find(int id) {
int root = id;
while (root != parent.get(root)) {
root = parent.get(root);
} //找到id所在树的根节点root
int now = id;
while (now != root) {
int up = parent.get(now);
parent.put(now, root); //将沿途的节点的父节点都更新为根节点
now = up;
}
return root;
}
//addRelation(id1, id2, ……)
public int merge(int id1, int id2) {
//……
//首先更新graph
addTriple(id1, id2); //计算新增的三角关系,注意要在更新graph之后
int root1 = find(id1);
int root2 = find(id2);
if (root1 == root2) {
return -1; //若id1和id2本来就在一个树中,则不做操作
}
blockCnt--; //若原来不在一个树中,合并后将联通子图数减一
int rank1 = rank.get(root1);
int rank2 = rank.get(root2);
if (rank1 < rank2) {
parent.put(root1, root2); //将秩较低的树的根指向秩较高的树的根
}
else {
if (rank1 == rank2) {
rank.put(root1, rank1 + 1);
}
parent.put(root2, root1);
}
return 0;
}
//modifyRelation(id1, id2, ……)
public void deleteEdge(int id1, int id2) {
subTriple(id1, id2); //注意要在更新graph之前
//……
//更新graph
HashSet<Integer> visited1 = new HashSet<>();
dfs(id1, visited1); //利用dfs算法查找与id1可达的所有的节点(包括id1)
for (int node : visited1) {
parent.put(node, id1);
rank.put(node, 1);
}
HashSet<Integer> visited2 = new HashSet<>();
if (!visited1.contains(id2)) { //若visited1不包含id2,说明此时id1和id2已经不可达,需要更新与id2可达的所有节点,同时将blockCnt加一
blockCnt++;
dfs(id2, visited2);
for (int node : visited2) {
parent.put(node, id2);
rank.put(node, 1);
}
}
}
private void addTriple(int id1, int id2) {
for (int neighbor : graph.get(id1)) {
if (graph.get(neighbor).contains(id2)) {
tripleCnt++;
}
}
}
private void subTriple(int id1, int id2) {
//……
}
}
主要是在维护blockCnt时出现了错误,当删去边后,若两点间不可达,我忘了对blockCnt加一
public void deleteEdge(int id1, int id2) {
//……
if (!visited1.contains(id2)) { //若visited1不包含id2,说明此时id1和id2已经不可达,需要更新与id2可达的所有节点,同时将blockCnt加一
blockCnt++;
//……
}
}
第十次作业中涉及到图模型的方法主要是queryShortestPath,由于对于性能要求比较高,我采用了bfs算法。
public int getShortestPath(int start, int end) {
if (start == end) {
return 0;
}
Queue<Integer> queue = new LinkedList<>();
HashSet<Integer> visited = new HashSet<>();
HashMap<Integer, Integer> pre = new HashMap<>();
queue.offer(start);
visited.add(start);
pre.put(start, start);
while (!queue.isEmpty()) {
int current = queue.poll();
if (current == end) {
break;
}
for (int next : graph.get(current)) {
if (!visited.contains(next)) {
queue.offer(next);
visited.add(next);
pre.put(next, current);
}
}
}
int count = 0;
int current = end;
while (current != start) {
current = pre.get(current);
count++;
}
return count - 1;
}
对于queryBestAcquaintance,我主要利用了数据结构(容器)实现了性能提升。在Person中,额外用一个有序容器存储acquaintance。这样,在queryBestAcquaintance()时,就可以把O(n)的复杂度降低到O(1)。
public class MyPerson implements Person {
private TreeMap<Integer, TreeSet<MyPerson>> acquaintanceByValue
= new TreeMap<>(Collections.reverseOrder());
//……
private void addAcquaintanceByValue(MyPerson myPerson, int value) {
acquaintanceByValue.putIfAbsent(value,
new TreeSet<>(Comparator.comparingInt(MyPerson::getId)));
acquaintanceByValue.get(value).add(myPerson);
}
private void removeAcquaintanceByValue(MyPerson myPerson, int value) {
acquaintanceByValue.get(value).remove(myPerson);
if (acquaintanceByValue.get(value).isEmpty()) {
acquaintanceByValue.remove(value);
}
}
public int queryBestAcquaintance() {
if (acquaintanceByValue.isEmpty()) {
return id;
}
return acquaintanceByValue.get(acquaintanceByValue.firstKey()).first().getId();
}
}
在queryCoupleSum()时,可以不必遍历network中所有的person,可以设置flag标记哪些person已经被找到bestAcquaintance了。
public int queryCoupleSum() {
int count = 0;
HashSet<Integer> flags = new HashSet<>();
for (Integer i : persons.keySet()) {
if (flags.contains(i)) {
continue;
}
MyPerson myPerson = persons.get(i);
int best1 = myPerson.queryBestAcquaintance();
if (best1 == i) {
continue;
}
MyPerson bestPerson = persons.get(best1);
int best2 = bestPerson.queryBestAcquaintance();
if (best2 == best1) {
continue;
}
if (best2 == i) {
count++;
flags.add(best1);
flags.add(best2);
}
}
return count;
}
在MyTag中,要对getAgeMean(),getAgeVar(),getValueSum()所涉及的数据进行动态维护,具体方法是在类内部存储ageSum,agePowSum(age的平方和)和valueSum。
public int getAgeMean() {
//……
return ageSum / persons.size() }
public int getAgeVar() {
//……
int mean = getAgeMean();
return (agePowSum - 2 * mean * ageSum + persons.size() * mean * mean) / persons.size();
}
处于直觉没有维护tag里的valueSum,而是在每次queryTagValueSum时遍历一次,这就导致在面对复杂tag的多次查询可能会超时,强测的一个数据点就在这上面卡了时间:
……
qtvs 114514 1919810
qtvs 114514 1919810
qtvs 114514 1919810
qtvs 114514 1919810
qtvs 114514 1919810
qtvs 114514 1919810
……
解决方案是动态维护valueSum,在tag里实现changeValueSum方法,以便在删减边和修改边时调用。
public void changeValueSum(int value, int id1, int id2) {
if (persons.containsKey(id1) && persons.containsKey(id2)) {
valueSum += value;
}
}
还有注意一点,在jml里两个人之间的valueSum是算了两遍的,所以tag里getValueSum需要返回的是valueSum * 2。
要注意一点,就是queryReceivedMessages时,要涉及寻找messages的前5个消息,所以要用有序容器存储message,我选择了Arraylist
还是出现在了qtvs指令上,有可能是第十次作业没有测出来,原因是在addRelation时没有维护tag里的valueSum。
经过了三次作业与性能的斗智斗勇,我最终理解了jml只是对方法的前提和结果进行了约束,而中间的过程(包括性能提升等)可以让我们自由发挥,不必按照jml语言一板一眼地翻译成Java语言。
主要分为数据构造和测试两个部分,需要注意以下几点:
由于测试可能包含了稀疏图、密集图等,我三次作业都采用随机构造数据的方法。同时,为了测试强度尽量大,我将testNum设置成了20,然后再构造数据的过程中避免了各种异常。
为了避免调用被测试方法前后对象状态不一致而带来的各种bug,我采取了影子network的办法,就是在生成数据时就完全复刻出一个oldNetwork等,然后在调用被测试方法后再比较network和oldNetwork等之间的状态。
针对network里的pure方法,特别需要关注persons容器前后长度有没有发生改变。
在第十一次作业中,除了构造MyEmojiMessage之外,还需要构造其他两种message。
本单元难度确实比较小,我认为所有的难度主要集中于如何提升图查询的性能以及如何针对jml书写Junit测试。在这个过程中,我学会了并查集的思想,学会了动态维护数据的思想,也学会了在什么情况下该用bfs算法,在什么情况下该用dfs算法。虽然在阅读jml语言时会眼花缭乱(找括号),但其实jml中有很多类似的实现方法,只要对这些类似的实现方法熟悉,阅读jml语言的困难就会降低。



