


301
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享本单元的数据构造并不是很容易
随机生成的数据可能在图的结构中不能覆盖很多的可能性
我选择了使用极端数据进行压力测试
比如id数据类型是int 那么就可以使用int类型的最大值和最小值进行测试 看代码能够正常工作
在第二次作业使用极端数据成功hack了一次
包括我自己在第三次作业被hack的数据也是某种程度的极端数据(下文提到)
这里自己发挥的不多 基本沿用JML的规定
采用邻接表来构建图 数组大多采用HashMap 保证查询的高效
因为测试数据整体来说对查询的压力高于构建
从数据结构上看
Network类为主体 其中图的节点类是Person 构建了带权(value)无向图 显然的邻接表式(熟人)
Tag 依赖于Person Messages则是在Network和Tag的基础上的结构
规格与设计分离的原则是指在软件开发过程中,我们可以分别独立地描述软件的“什么”和“如何”。即,我们将软件的功能需求或业务逻辑(即规格)与软件的实现细节或内部结构(即设计)显式地分离开。
这样做的好处
上面也提到了 规格只是一种对于接口的约束 而不是建议的实现方式
我在没有领会到这一点的情况下 按照JML写了方法 包括但不限于在 三元环那里使用了三重循环
在ddl当天 学习了并查集 将实现方式进行了修改
第一次需要注意的是
这样做基础是构建压力小于查询 但实际上构建少于查询是合理的
而且这样在时间复杂度上也更为合理 避免了O(n2) O(n3)
需要注意的是 使用并查集 在增加关系 和 查询上都是 常数级
但是涉及到删除 就是O(n) 相对来说麻烦一点
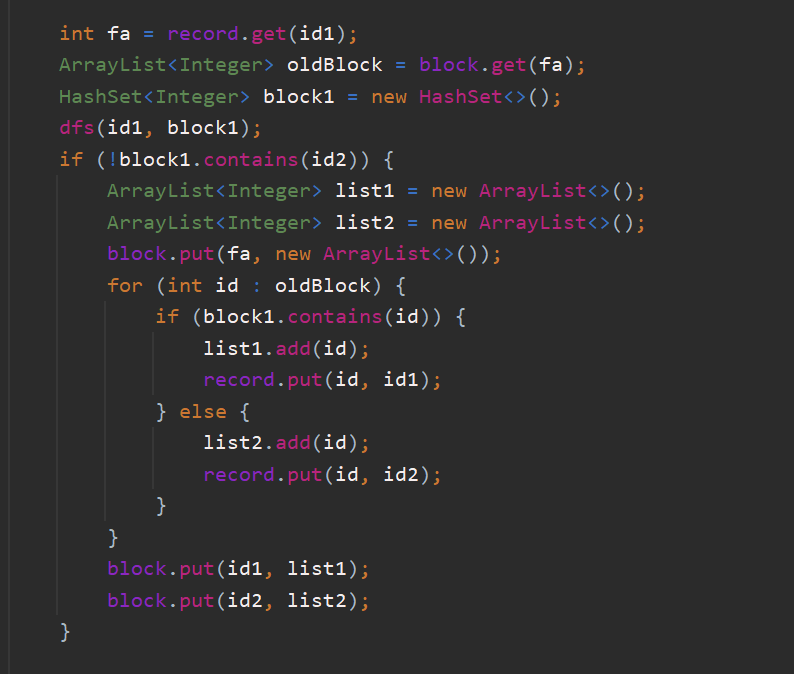
思路上 在删边时 判断删除后id1点的block有没有id2点 如果有 说明删了一条边还有边使之联通
就不用管了
如果不在 说明原来的block 就要分成两个
分成两个的操作是常数级
只是建立1的block 需要dfs 这个时间复杂度也是可以接受的
在涉及agevalue 和 方差的查询上 可以动态维护 Sum 和 SumSqure
也就是和 以及 平方和
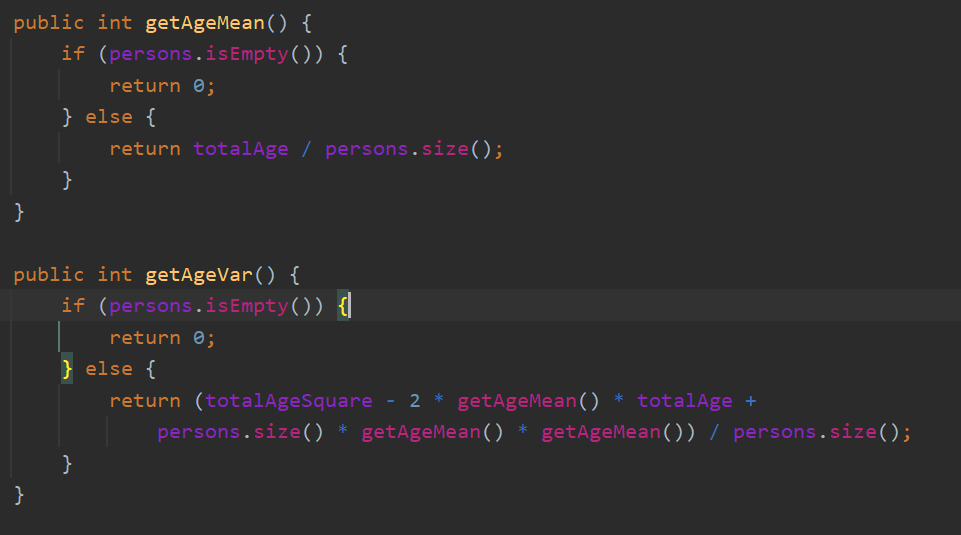
然后通过恒等变形就可以得到动态维护下的常数级查询
注意一点 getMean 是截断过的值就行了
值得注意的是 Tag的增加 导致在 modifyRelation 和 addRelation中 增加了维护的需求
然后是couple 使用了脏位coupleDirty
我在修改脏位上的逻辑没有细化 比如addRelation时就直接coupleDirty=true
modifyRelation时稍微细化了一下 判断getBestAcquaintance的前后变化情况
然后在脏位修改的情况下的查询的时间复杂度也就是O(n)
我分别使用了bfs和迪杰斯特拉 感觉差别不是很大 因为迪杰斯特拉用了优先队列
正常情况下还是用bfs
在性能上的要求不是很明显
按JML的规定来编写 自由发挥的空间不是很大
前两次作业未出现问题
第三次作业出现逻辑上的漏洞
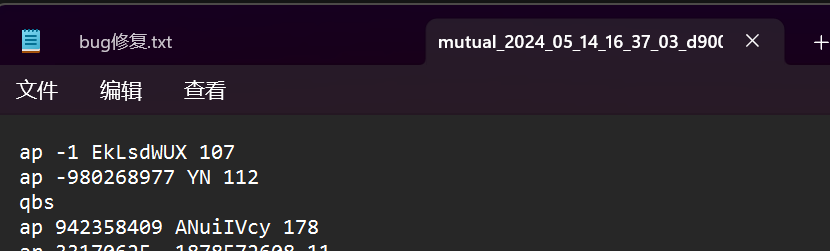
第一行是导致我出问题的原因
可以看出来这个数据是随机出来的
这位同学大概没有看我的代码
如果看了 只要几行就够了而不是几百行
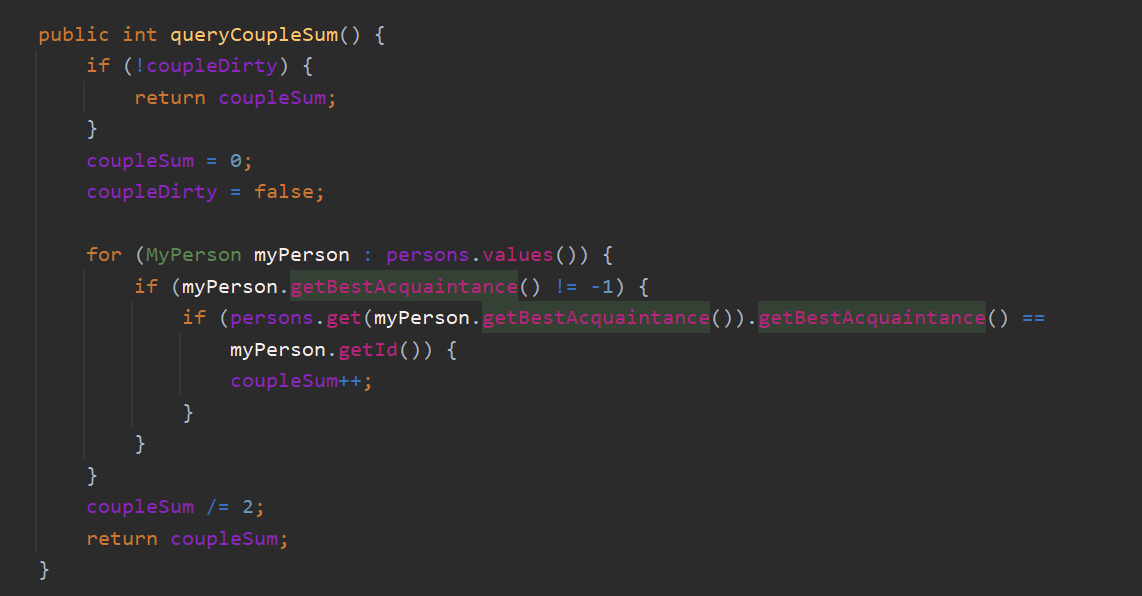
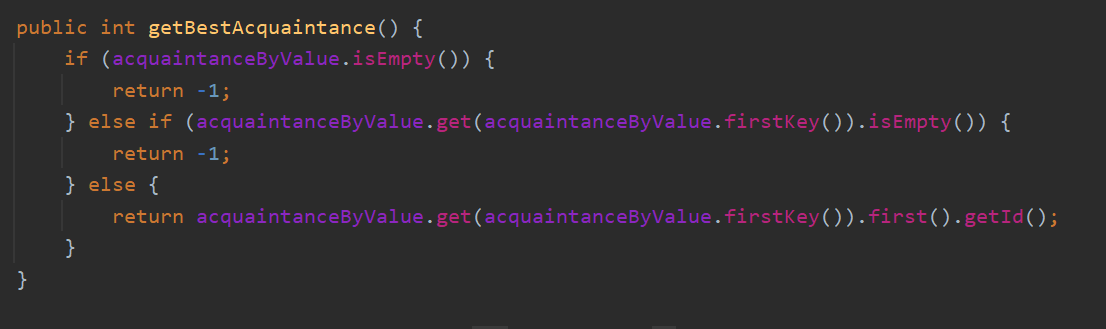
我在MyNetwork 中使用 判断 异常值-1 表示id值的有效性
但是实际上 id 本就是在int范围内 完全可能是-1


增加对异常情况的判断即可
这个bug 虽然是黑箱测试出来的 但比较适合静态分析和白箱测试(前提是头脑清醒能发现)
通过JML规格构建Junit测试比较清晰,只需将JML规格保证不变的内容全部检查一遍,并检验结果是否正确即可。
比如文档中有提示 检查 requires ensures assignable 等行为
这个单元总体来说工作量不是很大
如果不用写单元测试)
这几次的JML体验感说实话不是特别好
但是 我认为这个单元想要传达的是一种契约式编程的思想
正是有着JML这种工具 才能让课程组不用写大段的自然语言来告诉大家每个函数如何写
这个单元大部分的方法都是固定的 而不是自由发挥的 这是与前两个单元的不同
前两个单元是一种黑箱式的契约 告诉你这个程序需要保证正确
然后实现是自由的
这个单元在固定框架(图结构和类、方法) 上如果不用JML
就需要写更长的文档 说明每一个方法应该如何实现和边界情况
同时自然语言又很容易导致歧义 虽然JML没能完全避免这一点
但总的来说 JML提供了一个范例和可行的方案
还有一点 规格和实现分离的想法也很重要
如果没领会到这一点 就会像我一样在第一次提交的前几个小时学习并查集



