




109
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享

推荐算法技术用于分析用户行为和偏好,预测并推荐用户可能感兴趣的内容或产品。在电子商务、流媒体服务等需要个性化推荐的场景中尤为重要。学习该技术是为了提升用户体验和平台用户粘性。技术难点在于推荐的准确性和效率。
随着技术的发展,推荐算法不断演进,从传统的协同过滤到基于内容的推荐,再到混合推荐系统和深度学习推荐模型,每种方法都有其独特的优势和应用场景。
协同过滤是推荐系统中最经典的算法之一,它基于用户的历史行为(如评分、点击等)来进行推荐。协同过滤有两种主要实现方式:
基于用户的协同过滤(User-based Collaborative Filtering):这种方法通过寻找与目标用户兴趣相似的其他用户,推荐这些用户喜欢的物品。它依赖于用户之间的相似度计算,通常使用余弦相似度或皮尔逊相关系数等方法。
基于物品的协同过滤(Item-based Collaborative Filtering):这种方法通过计算物品之间的相似度,推荐与用户已评价的物品相似的其他物品。它通常比基于用户的方法更高效,因为物品的数量通常少于用户数量。
SVD是一种矩阵分解方法,用于将用户-物品评分矩阵分解为三个矩阵的乘积:U(用户特征矩阵)、Σ(奇异值矩阵)、V(物品特征矩阵)。通过对评分矩阵进行SVD分解,可以找到潜在的用户和物品特征,从而预测用户对物品的评分。SVD在处理大规模数据集时特别有效,因为它能降维并提取数据的潜在结构。
基于内容的推荐算法侧重于分析物品的内容特征,如文本、图像或视频内容。这种方法通过匹配用户的历史偏好和物品的特征来生成推荐。它通常用于内容丰富的环境,如新闻文章、博客或视频。
混合推荐系统结合了多种推荐技术,以克服单一方法的局限性。例如,它可以结合协同过滤和基于内容的推荐,以提高推荐的准确性和多样性。混合系统可以利用不同算法的优势,提供更全面和个性化的推荐。
随着深度学习技术的发展,基于神经网络的推荐模型越来越受到关注。这些模型可以自动学习用户和物品的复杂特征表示,并用于预测用户的行为。深度学习推荐模型在处理大规模数据集和复杂用户行为时表现出色。
推荐算法的选择和实现取决于具体的应用场景、数据可用性和业务目标。有效的推荐系统可以显著提升用户体验和平台的用户粘性。随着技术的不断进步,推荐算法将继续发展和优化,以满足日益增长的个性化需求。
核心思想是找到与目标用户兴趣相似的其他用户,然后推荐那些相似用户喜欢而目标用户尚未接触的物品。
为了确保推荐的相关
性,我对搜索词和地理位置进行了严格的限定,确保推荐的美食名称必须包含搜索词且在用户附近(这里我定义的是1.5km以内)。通过分析用户的点赞、点踩和搜索记录等行为,我们构造了每个商品的得分向量,其中点赞行为对商品得分的正面影响最大,点踩行为则产生负面影响,而搜索记录则提供了一个较小的正面影响。在关键词匹配中,我们使用Jaccard相似度来衡量搜索词与菜谱或美食名称的匹配度,以确保推荐结果的相关性。其中为了对外提供接口,统一使用一个函数,并使用isRecipe作为区分美食和菜谱。
在a阶段测试时,发现推荐速度太慢,于是进行了以下优化:
优化1:数据库结构设计:为关键词和描述建立索引提高查询速度。
优化2:数据库操作优化:使用连接池来避免频繁地打开和关闭数据库连接,通过重用现有的数据库连接来提高效率。同时,采用批量查询来减少数据库查询次数,优化数据获取过程。
优化2:缓存机制的应用:通过使用缓存保存用户的相关记录,便于下次快速使用,这不仅提高了系统的响应速度,也减轻了数据库的压力。
使用findksimilarusers函数通过计算用户之间的相似度,找出最相似的k个用户(邻居)。
在选择相似性度量时,可根据以下几点进行选择:
• 当数据受用户偏好/用户的不同评分尺度影响时,请使用皮尔逊相似度
• 如果数据稀疏,则使用余弦(许多额定值未定义)
• 如果数据不稀疏并且属性值的大小很重要,请使用欧几里得(Euclidean)。
• 建议使用调整后的余弦(Adjusted Cosine Similarity)进行基于商品的方法来调整用户偏好。
我在这里使用余弦相似性,其定义如下:
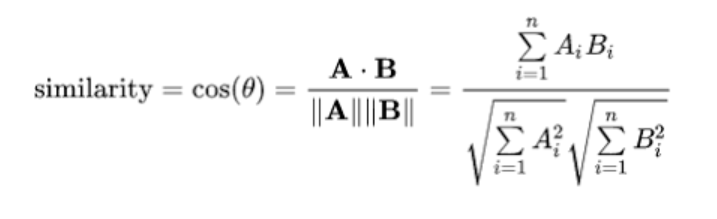
通过构造用户-商品得分矩阵并对矩阵计算余弦相似度得到最相似的k个用户(我设置4个)。
使用这些相似的用户的对商品的评分数据来预测目标用户对未评分物品的评分或偏好:通过邻居平均值的偏差的加权平均值来计算,并将其添加到目标用户的平均评分中。 偏差用于调整用户相关的偏差。 出现用户偏差的原因是某些用户可能总是对所有项目给予高评分或低评分。
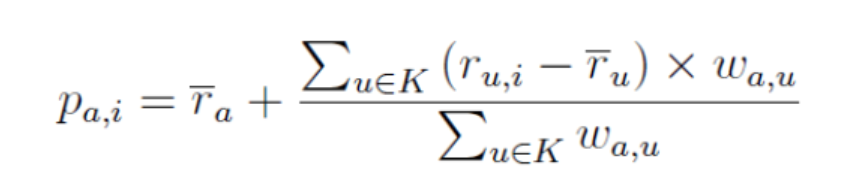
其中p(a,i)是目标用户a对商品i的预测,w(a,u)是用户a和u之间的相似度,K是和目标用户相似的K个用户。
把推荐系统作为服务部署,使用flask应用提供API接口。
问题:在用户基数较大的应用程序中,基于用户的方法面临可扩展性问题,因为它们的复杂性随用户数量呈线性增长。基于商品的方法解决了这些可扩展性问题,因此有了基于商品相似性推荐项目。
基于物品的推荐算法主要依赖于物品的属性和特征,为用户推荐与他们之前喜欢的物品相似的新物品。
采用与基于用户的协同过滤相似的处理方法,分析用户过去喜欢的物品的特征。
使用余弦相似性度量来计算一对商品之间的相似度。 可以通过使用简单的加权平均值来预测目标用户a对目标商品i的评分:

函数findksimilaritems使用最近邻方法采用余弦相似性来找到k项最相似的商品i。
使用基于商品的推荐系统方法的余弦相似性度量不考虑用户评分的偏差。 调整后的余弦相似度通过从每个共同评分对中减去各自用户的平均评分来抵消该缺点,并且被定义为如下
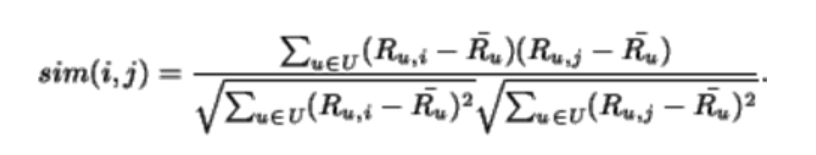
为了在Python中实现Adjusted Cosine相似度,我定义了一个名为computeAdjCosSim的简单函数,该函数返回调整后的余弦相似度矩阵,给出评分矩阵。函数findksimilaritems_adjcos和predic
t_itembased_adjcos利用调整后的余弦相似度来查找k个相似项并计算预测评分。
- def computeAdjCosSim(M):
- sim_matrix = np.zeros((M.shape[1], M.shape[1]))
- M_u = M.mean(axis=1) # mean
-
- for i in range(M.shape[1]):
- for j in range(M.shape[1]):
- if i == j:
-
- sim_matrix[i][j] = 1
- else:
- if i < j:
-
- sum_num = sum_den1 = sum_den2 = 0
- for k, row in M.loc[:, [i, j]].iterrows():
-
- if ((M.loc[k, i] != 0) & (M.loc[k, j] != 0)):
- num = (M[i][k] - M_u[k]) * (M[j][k] - M_u[k])
- den1 = (M[i][k] - M_u[k]) ** 2
- den2 = (M[j][k] - M_u[k]) ** 2
-
- sum_num = sum_num + num
- sum_den1 = sum_den1 + den1
- sum_den2 = sum_den2 + den2
-
- else:
- continue
-
- den = (sum_den1 ** 0.5) * (sum_den2 ** 0.5)
- if den != 0:
- sim_matrix[i][j] = sum_num / den
- else:
- sim_matrix[i][j] = 0
-
-
- else:
- sim_matrix[i][j] = sim_matrix[j][i]
-
- return pd.DataFrame(sim_matrix)
-
- def findksimilaritems_adjcos(item_id, ratings, k=4):
- sim_matrix = computeAdjCosSim(ratings)
- similarities = sim_matrix[item_id - 1].sort_values(ascending=False)
- indices = sim_matrix[item_id - 1].sort_values(ascending=False)[:k].index
-
- print('{0} most similar items for item {1}:\n'.format(k - 1, item_id))
- for i in range(0, len(indices)):
- if indices[i] + 1 == item_id:
- continue
-
- else:
- print('{0}: Item {1} :, with similarity of {2}'.format(i, indices[i] + 1, similarities[i]))
-
- return similarities, indices
- def predict_itembased_adjcos(user_id, ratings):
- prediction = 0
- for item_id in range(ratings.shape[1]):
- similarities, indices = findksimilaritems_adjcos(item_id, ratings)
- # similar users based on correlation coefficients
- sum_wt = np.sum(similarities) - 1
-
- product = 1
- wtd_sum = 0
- for i in range(0, len(indices)):
- if indices[i] + 1 == item_id:
- continue
- else:
- product = ratings.iloc[user_id - 1, indices[i]] *(similarities[i])
- wtd_sum = wtd_sum + product
- prediction = round(wtd_sum / sum_wt)
- # if prediction < 0:
- # prediction = 1
- # elif prediction > 10:
- # prediction = 10
- print('\nPredicted rating for user {0} -> item {1}: {2}'.format(user_id, item_id, prediction))
预测指定用户和商品的评分,并建议商品是否可以推荐给用户,如果该商品尚未被用户评分,并且预测评分排名靠前且分数大于1,则推荐给用户。
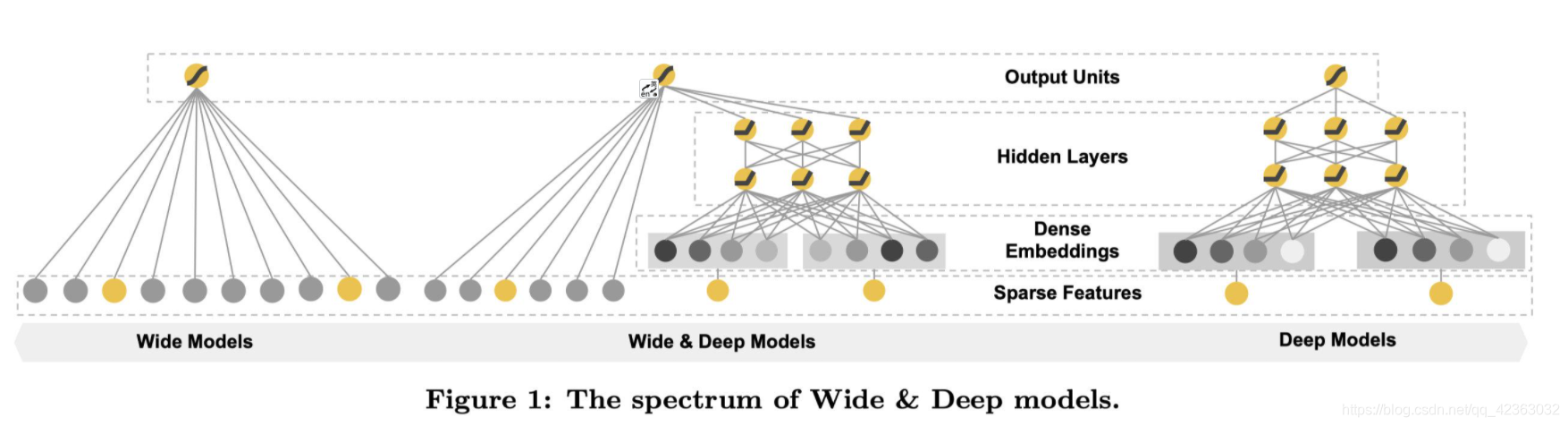
wide模型就是一个形如
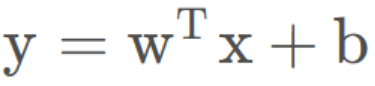

deep模型就是一个前馈神经网络:输入是一个sparse的feature,可以简单理解成multihot的数组。这个输入会在神经网络的第一层转化成一个低维度的embedding,然后神经网络训练的是这个embedding。这个模块主要是被设计用来处理一些类别特征,比如说item的类目,用户的性别等等。
和传统意义上的one-hot方法相比,embedding的方式用一个向量来表示一个离散型的变量,它的表达能力更强,并且这个向量的值是让模型自己学习的,因此泛化能力也大大提升。这也是深度神经网络当中常见的做法。
最上层输出之前是一个sigmoid层或者是一个linear层,就是一个简单的线性累加。英文叫做joint,原paper当中还列举了joint和ensemble的区别,对于ensemble模型来说,它的每一个部分是独立训练的。而joint模型当中的不同部分是联合训练的。ensemble模型当中的每一个部分的参数是互不影响的,但是对于joint模型而言,它当中的参数是同时训练的。
这样带来的结果是,由于训练对于每个部分是分开的,所以每一个子模型的参数空间都很大,这样才能获得比较好的效果。而joint训练的方式则没有这个问题,把线性部分和深度学习的部分分开,可以互补它们之间的缺陷,从而达到更好的效果,并且也不用人为地扩大训练参数的数量。
- '''
- WideDeep模型:
- 主要包括Wide部分和Deep部分
- '''
- class WideDeep(nn.Module):
-
- def __init__(self, feature_info, hidden_units, embed_dim=8):
- """
- DeepCrossing:
- feature_info: 特征信息(数值特征, 类别特征, 类别特征embedding映射)
- hidden_units: 列表, 隐藏单元
- dropout: Dropout层的失活比例
- embed_dim: embedding维度
- """
- super(WideDeep, self).__init__()
-
- self.dense_features, self.sparse_features, self.sparse_features_map = feature_info
-
- # embedding层, 这里需要一个列表的形式, 因为每个类别特征都需要embedding
- self.embed_layers = nn.ModuleDict(
- {
- 'embed_' + str(key): nn.Embedding(num_embeddings=(val), embedding_dim=embed_dim)
- for key, val in self.sparse_features_map.items()
- }
- )
-
-
- # 统计embedding_dim的总维度
- # 一个离散型(类别型)变量 通过embedding层变为8纬
- embed_dim_sum = sum([embed_dim] * len(self.sparse_features))
- # 总维度 = 数值型特征的纬度 + 离散型变量经过embedding后的纬度
- dim_sum = len(self.dense_features) + embed_dim_sum
- hidden_units.insert(0, dim_sum)
- # dnn网络
- self.dnn_network = Dnn(hidden_units)
-
- # 线性层
- self.linear = Linear(input_dim=len(self.dense_features))
-
- # 最终的线性层
- self.final_linear = nn.Linear(hidden_units[-1], 1)
-
- def forward(self, x):
- # print(x.shape)
- # 1、先把输入向量x分成两部分处理、因为数值型和类别型的处理方式不一样
- dense_input, sparse_inputs = x[:, :len(self.dense_features)], x[:, len(self.dense_features):]
- # 2、转换为long形
- sparse_inputs = sparse_inputs.long()
-
- # 2、不同的类别特征分别embedding
- sparse_embeds = []
-
- for key, i in zip(self.sparse_features_map.keys(), range(sparse_inputs.shape[1])):
- # print(key)
- # print(sparse_inputs[:, i].shape,sparse_inputs[:, i].max())
- # print(self.embed_layers['embed_' + key].num_embeddings)
- sparse_embeds.append(self.embed_layers['embed_' + key](sparse_inputs[:, i]) )
- # 3、把类别型特征进行拼接,即emdedding后,由3行转换为1行
- sparse_embeds = torch.cat(sparse_embeds, axis=-1)
- # sparse_embeds = torch.tensor(sparse_embeds)
- # 4、数值型和类别型特征进行拼接
- dnn_input = torch.cat([sparse_embeds, dense_input], axis=1)
-
- # Wide部分,使用的特征为数值型类型
- wide_out = self.linear(dense_input)
-
- # Deep部分,使用全部特征
- deep_out = self.dnn_network(dnn_input)
-
- deep_out = self.final_linear(deep_out)
-
- # out 将Wide部分的输出和Deep部分的输出进行合并
- outputs = F.sigmoid(0.5 * (wide_out + deep_out))
-
- return outputs
- def prepared_data(file_path):
- # 读入训练集,验证集和测试集
- # train_set = pd.read_csv(file_path + 'train_set.csv')
- # val_set = pd.read_csv(file_path + 'val_set.csv')
- # test_set = pd.read_csv(file_path + 'test.csv')
- # 数值型特征直接放入stacking层
- dense_features = ['I' + str(i) for i in range(1, 14)]
- # 离散型特征需要需要进行embedding处理
- sparse_features = ['C' + str(i) for i in range(1, 27)]
- col_names_train = ['Label'] + dense_features + sparse_features
- data = pd.read_csv(
- file_path +'/train.txt',
- sep='\t',
- nrows=1000,
- names=col_names_train
- )
- train_set = data[:700]
- val_set = data[701:900]
- test_set = data[900:1000]
-
- # 这里需要把特征分成数值型和离散型
- # 因为后面的模型里面离散型的特征需要embedding, 而数值型的特征直接进入了stacking层, 处理方式会不一样
- data_df = pd.concat((train_set, val_set, test_set))
- #==================================================
- # 数据预处理
-
-
- # 2.对分类特征进行独热编码
- for f in sparse_features:
- le = LabelEncoder()
- data_df[f] = le.fit_transform(data_df[f])
- # 1、填充缺失值
- # 类别特征填充为-1
- data_df[dense_features] = data_df[dense_features].fillna('-1')
- # 连续特征填充为0
- data_df[sparse_features] = data_df[sparse_features].fillna(0)
- # 3、对于连续性变量进行归一化
- mms = MinMaxScaler()
- data_df[dense_features] = mms.fit_transform(data_df[dense_features])
-
- #==============================
- train = data_df[:700]
- val = data_df[701:900]
- test = data_df[900:1000]
-
-
- # 定义一个稀疏特征的embedding映射, 字典{key: value},
- # key表示每个稀疏特征, value表示数据集data_df对应列的不同取值个数, 作为embedding输入维度
- sparse_feas_map = {}
- for key in sparse_features:
- sparse_feas_map[key] = 1000000
- # sparse_feas_map[key] = int(data_df[key].max()) + 1
- # sparse_feas_map[key] = data_df[key].nunique()
-
- feature_info = [dense_features, sparse_features, sparse_feas_map] # 这里把特征信息进行封装, 建立模型的时候作为参数传入
- # 把数据构建成数据管道
- dl_train_dataset = TensorDataset(
- # 特征信息
- torch.tensor(train.drop(columns='Label').values).float(),
- # 标签信息
- torch.tensor(train['Label'].values).float()
- )
-
- dl_val_dataset = TensorDataset(
- # 特征信息
- torch.tensor(val.drop(columns='Label').values).float(),
- # 标签信息
- torch.tensor(val['Label'].values).float()
- )
- dl_train = DataLoader(dl_train_dataset, shuffle=True, batch_size=16)
- dl_vaild = DataLoader(dl_val_dataset, shuffle=True, batch_size=16)
- return feature_info,dl_train,dl_vaild,test
-
- def train_ch(net, dl_train, dl_vaild, num_epochs, lr, device):
- """⽤GPU训练模型"""
- print('training on', device)
- net.to(device)
- # 二值交叉熵损失
- loss_func = nn.BCELoss()
- # 注意:这里没有使用原理提到的优化器
- optimizer = torch.optim.Adam(params=net.parameters(), lr=lr)
-
- # animator = Animator(xlabel='epoch', xlim=[1, num_epochs],legend=['train loss', 'train auc', 'val loss', 'val auc']
- # ,figsize=(8.0, 6.0))
- # timer, num_batches = Timer(), len(dl_train)
- log_step_freq = 10
-
- for epoch in range(1, num_epochs + 1):
- # 训练阶段
- net.train()
- loss_sum = 0.0
- metric_sum = 0.0
-
- for step, (features, labels) in enumerate(dl_train, 1):
- # timer.start()
- # 梯度清零
- optimizer.zero_grad()
-
- # 正向传播
- predictions = net(features)
- loss = loss_func(predictions, labels.unsqueeze(1) )
- try: # 这里就是如果当前批次里面的y只有一个类别, 跳过去
- metric = metric_func(predictions, labels)
- except ValueError:
- pass
-
- # 反向传播求梯度
- loss.backward()
- optimizer.step()
- # timer.stop()
-
- # 打印batch级别日志
- loss_sum += loss.item()
- metric_sum += metric.item()
-
- # if step % log_step_freq == 0:
- # animator.add(epoch + step / num_batches,(loss_sum/step, metric_sum/step, None, None))
-
- # 验证阶段
- net.eval()
- val_loss_sum = 0.0
- val_metric_sum = 0.0
-
-
- for val_step, (features, labels) in enumerate(dl_vaild, 1):
- with torch.no_grad():
- predictions = net(features)
- val_loss = loss_func(predictions, labels.unsqueeze(1))
- try:
- val_metric = metric_func(predictions, labels)
- except ValueError:
- pass
-
- val_loss_sum += val_loss.item()
- val_metric_sum += val_metric.item()
-
- # if val_step % log_step_freq == 0:
- # animator.add(epoch + val_step / num_batches, (None,None,val_loss_sum / val_step , val_metric_sum / val_step))
-
- print(f'final: loss {loss_sum/len(dl_train):.3f}, auc {metric_sum/len(dl_train):.3f},'
- f' val loss {val_loss_sum/len(dl_vaild):.3f}, val auc {val_metric_sum/len(dl_vaild):.3f}')
- # print(f'{num_batches * num_epochs / timer.sum():.1f} examples/sec on {str(device)}')
-
由于模型较大而数据量不够,导致过拟合问题。尽管尝试了一些方法(如L1和L2正则化,Dropout等),但效果依旧不理想,最终淘汰了这个方案。这反映了在实际应用中,模型的选择和数据量的匹配至关重要。
描述:在协同过滤中,用户-物品评分矩阵通常非常稀疏,导致相似度计算不准确。这种稀疏性问题会影响推荐的准确性,因为相似度计算依赖于用户或物品之间的共同评分。
解决过程:
KNN算法填充:我们采用了KNN(K-Nearest Neighbor)算法来填充缺失的评分。通过找到与目标用户或物品最相似的K个邻居,并使用这些邻居的评分来估计缺失的评分。
数据标准化:对用户评分进行标准化处理,减小评分之间的差异。这有助于提高相似度计算的准确性。
调整后的余弦相似度:在基于物品的协同过滤中,我们使用调整后的余弦相似度(Adjusted Cosine Similarity)来计算物品之间的相似度。这种方法通过从每个共同评分对中减去各自用户的平均评分来抵消用户评分偏差的影响。
- from sklearn.metrics.pairwise import cosine_similarity
- import numpy as np
-
- # 调整后的余弦相似度
- def adjusted_cosine_similarity(matrix):
- user_means = np.mean(matrix, axis=1, keepdims=True)
- adjusted_matrix = matrix - user_means
- return cosine_similarity(adjusted_matrix)
-
- # 计算物品相似度
- item_similarity = adjusted_cosine_similarity(train_data.T)
描述:由于模型复杂度高且数据量不足,导致模型过拟合。过拟合的模型在训练数据上表现良好,但在测试数据上表现不佳,这限制了模型的泛化能力。
解决过程:
正则化技术:我们尝试了L1和L2正则化技术来限制模型参数的复杂度。正则化通过在损失函数中添加惩罚项来减少模型的过拟合风险。
Dropout技术:在训练过程中使用Dropout技术随机丢弃一些神经元,防止网络对训练数据中的特定样本过度敏感。
早停法(Early Stopping):在训练过程中监控验证集的性能,当验证集的性能不再提升时停止训练,避免过拟合。
- from keras.models import Sequential
- from keras.layers import Dense, Dropout
- from keras.callbacks import EarlyStopping
-
- # 构建模型
- model = Sequential()
- model.add(Dense(64, activation='relu', input_dim=20))
- model.add(Dropout(0.5))
- model.add(Dense(1, activation='sigmoid'))
-
- # 编译模型
- model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
-
- # 早停法
- early_stopping = EarlyStopping(monitor='val_loss', patience=5)
-
- # 训练模型
- model.fit(train_data, train_labels, epochs=100, validation_split=0.2, callbacks=[early_stopping])
描述:在处理大规模数据集时,系统的响应速度和处理能力成为瓶颈。数据库操作频繁,导致系统性能下降。
解决过程:
数据库连接池:使用连接池来避免频繁地打开和关闭数据库连接,通过重用现有的数据库连接来提高效率。
缓存机制:通过使用缓存保存用户的相关记录,便于下次快速使用,这不仅提高了系统的响应速度,也减轻了数据库的压力。
批量查询:减少数据库查询次数,通过批量查询来获取数据,优化数据获取过程。
- from sqlalchemy import create_engine
- from sqlalchemy.pool import QueuePool
-
- # 使用连接池
- engine = create_engine('database_url', poolclass=QueuePool, pool_size=10, max_overflow=20)
-
- # 使用缓存
- from cachetools import cached, TTLCache
- cache = TTLCache(maxsize=100, ttl=300)
-
- @cached(cache)
- def get_user_data(user_id):
- return pd.read_sql_query(f"SELECT * FROM interactions WHERE user_id={user_id}", engine)
在本次技术总结中,我详细介绍了我使用的几种推荐算法的实现方式及其在实际应用中的优化策略。可以看到,尽管宽广神经网络模型在理论上具有强大的特征交互能力,但由于模型复杂度高且数据量不足,导致过拟合问题,最终未能达到预期效果。这一经历强调了模型选择与数据量匹配的重要性。此外,我还总结了以下几点:
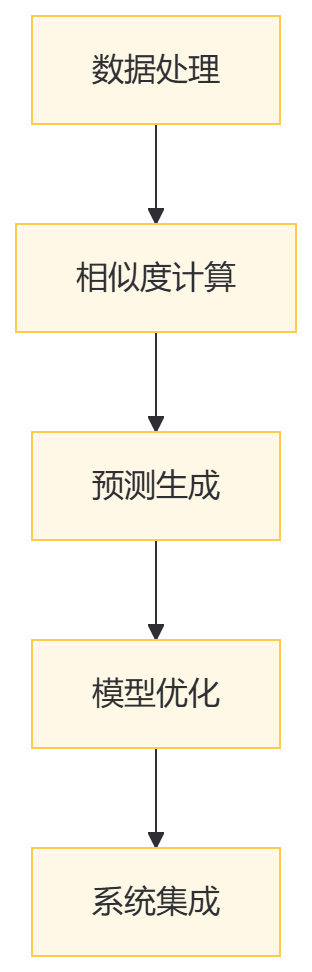
数据处理的重要性:精确的数据处理和特征工程是构建有效推荐系统的基础。通过对用户行为的细致分析和数据的精确处理,我们能够为用户提供更加个性化和准确的推荐。
模型优化的必要性:在模型训练过程中,优化数据库操作、引入缓存机制、使用连接池等措施显著提升了系统的响应速度和处理能力。
算法多样性的价值:不同的推荐算法适用于不同的场景和需求。通过结合协同过滤、基于内容的推荐、混合推荐系统和深度学习模型,我们可以更全面地满足用户的个性化需求。
持续学习和实验的重要性:在推荐系统的研究和实践中,持续的优化和实验是必不可少的。通过不断尝试和调整,可以找到最适合当前问题的模型结构和参数。
传统推荐系统算法(一):协同过滤(Collaborative Filtering,CF)-CSDN博客





