[9章全]AI训练师 零基础入门与实战
社区首页 (3670)
 我加入的社区 我管理的社区 官方推荐社区
76
其他社区
3670
我加入的社区 我管理的社区 官方推荐社区
76
其他社区
3670
请编写您的帖子内容
社区频道(11)
显示侧栏
卡片版式
全部
活动
YOLO专区
问答
自然语言处理
计算机视觉
论文
代码
求职招聘
博文收录
Ada助手
最新发布
最新回复
标题
阅读量
内容评分
精选

399
评分
回复


[9章全]AI训练师 零基础入门与实战
[9章全]AI训练师 零基础入门与实战 从零到一:AI训练师的实战进阶之路 在人工智能技术席卷全球的今天,一个新兴职业正在悄然崛起——AI训练师。这个看似神秘的职业,实际上已成为连接人工智能技术与实际应用场景的关键桥梁。据统计,2023年中国AI训
复制链接 扫一扫
分享

410
评分
回复

[完整版10章]n8n+AI工作流:从入门到企业级AI应用实战
在传统企业的自动化实践中,我们常常看到这样的场景:IT部门花费数周时间开发一个数据同步脚本,业务人员每天手动整理不同平台的报表,客服团队重复复制粘贴相似的回复内容。这些孤立的自动化尝试如同一个个“自动化孤岛”,虽在局部提升了效率,却未能触及企业运营
复制链接 扫一扫
分享
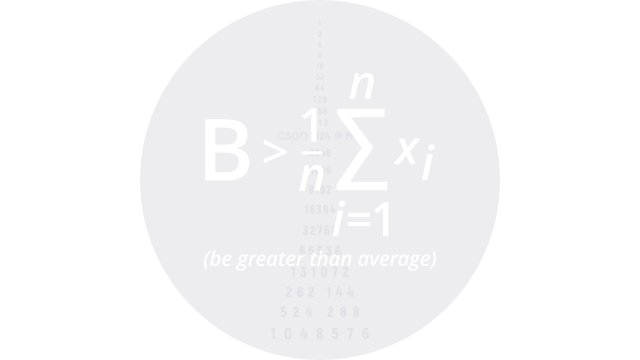
409
评分
回复

[完结22章]从0到1,LangChain+RAG全链路实战AI知识库教程
[完结22章]从0到1,LangChain+RAG全链路实战AI知识库教程 在信息爆炸的时代,每个企业都坐拥大量文档、报告、手册等非结构化数据,却常常陷入“知识就在那里,但就是找不到”的困境。传统的关键词搜索如同在迷雾中摸索,而早期基于规则的聊天机
复制链接 扫一扫
分享

521
评分
1

【2025更新】小白玩转AI大模型应用开发教程
【2025更新】小白玩转AI大模型应用开发教程 在人工智能浪潮席卷全球的今天,AI大模型不再只是科技巨头的专属玩具,而是逐渐成为每个有想法的普通人都能使用的强大工具。你是否曾经想过开发自己的AI应用,却苦于没有计算机背景?是否被"神经网络"、"
复制链接 扫一扫
分享

447
评分
回复
【2025更新】小白玩转AI大模型应用开发
清晨的第一缕阳光透过窗帘,你打开手机,语音助手为你播报今日日程;午休时,智能写作工具帮你润色工作报告;深夜,推荐算法为你找到心仪的电影。不知不觉间,人工智能大模型已渗透生活的每个角落。或许你以为,驾驭这些“数字巨兽”是科技巨头的专利,是博士们的游戏
复制链接 扫一扫
分享

459
评分
回复

[10章全]Java大模型工程能力必修课,LangChain4j 入门到实践
[10章全]Java大模型工程能力必修课,LangChain4j 入门到实践 在人工智能技术飞速发展的今天,大型语言模型已成为推动创新的核心引擎。Java作为企业级应用开发的主流语言,如何与大模型技术有效结合,成为开发者必须面对的重要课题。Lang
复制链接 扫一扫
分享

463
评分
回复
AI智能体(Agent)开发实战:工业级项目案例驱动课
AI智能体(Agent)开发实战:工业级项目案例驱动课 在工业控制中心,一个AI智能体正同时监控数百个传感器数据流。它检测到3号生产线的温度异常升高,立即调取历史数据比对,发现与2023年8月的事故模式高度吻合。在人类操作员尚未察觉前,它已经自动
复制链接 扫一扫
分享
689
评分
回复
[完结]AI 全栈开发实战营
AI全栈开发实战营:从数据到智能应用的完整旅程 在人工智能浪潮席卷全球的今天,AI全栈开发能力已成为技术人才的新标杆。"AI全栈开发实战营"应运而生,为开发者提供了一条从基础理论到产业实践的完整成长路径。这不仅是一场技术培训,更是一次思维模式的革
复制链接 扫一扫
分享
518
评分
回复

Yolov8.2.0导出的best_int8.tflite在安卓Flutter框架中无法检测出目标,不知道是咋回事?
Yolo 目标检测,未能识别图像内容
复制链接 扫一扫
分享

494
评分
回复

从训练到部署:基于YOLOv5和TensorRT的人脸口罩检测系统全流程实战指南(开源代码)
我发表了一篇新的文章:从训练到部署:基于YOLOv5和TensorRT的人脸口罩检测系统全流程实战指南(开源代码),适合对深度学习和目标检测感兴趣的开发者。文章详细介绍了如何从零开始构建一个高效的人脸口罩检测系统,涵盖了从数据标注、模型训练到模型部署
复制链接 扫一扫
分享

577
评分
1

YOLOv5s训练结果太高了
我用YOLOv5s训练自己的数据集,map接近1了,这是怎么回事啊
复制链接 扫一扫
分享

573
评分
1

我想用yolov5 5.0的模型,使用yolov5 6.0训练好的权重,会遇到这个问题,搜了两天了试了各种办法,都解决不了,求求大家了呜呜呜
[图片]
复制链接 扫一扫
分享
大家好我想问一些问题,请大家看一下
就是想自动化测试一下
...全文
573
评分
回复
大家好我想问一些问题,请大家看一下
就是想自动化测试一下
复制链接 扫一扫
分享


579
评分
回复


ChatGLM2-6b对话模型有那么点意思了
Windows 环境部署 ChatGLM2-6b 入门教程_windows 部署chatglm-CSDN博客
复制链接 扫一扫
分享

410
评分
回复
百度每天20%新增代码由AI生成,Comate SaaS服务8000家客户 采纳率超40%
百度每天20%新增代码由AI生成,Comate SaaS服务8000家客户 采纳率超40%
复制链接 扫一扫
分享

740
评分
1
 复制链接
复制链接 扫一扫
分享

685
评分
回复
复制链接 扫一扫
分享

532
评分
2
autoware联合相机和激光雷达得到的标定文件如何转为kitti的calib格式
autoware联合相机和激光雷达得到的标定文件如何转为kitti的calib格式
复制链接 扫一扫
分享

414
评分
回复

【树莓派】用于处理 I2C、SPI 和 UART 的C++库
【树莓派】用于处理 I2C、SPI 和 UART 的C++库_无水先生的博客-CSDN博客
复制链接 扫一扫
分享

427
评分
回复
【基础理论】隐马尔可夫模型及其算法
【基础理论】隐马尔可夫模型及其算法_无水先生的博客-CSDN博客
复制链接 扫一扫
分享
为您搜索到以下结果:








